Data
How is ‘Get records executed on a container level’ different from ‘Get records executed Floor level’ operations?
Get records floor level:
- Right-click on Gathr Analytics Floor > Database Connector > Native Database > Get Records
- Select the table name, and it will fetch all the records.
Get records container level:
- Select the container header of Editable app > Right-click > Database Connector > Native Database > Get Records.
- The given operation on high level is used to run a whole container on contextual level.
Consider, the given container has 2 columns C1 and C2.
- C1 have values V1, V2, V3
- C2 have values: P1, P2, P3
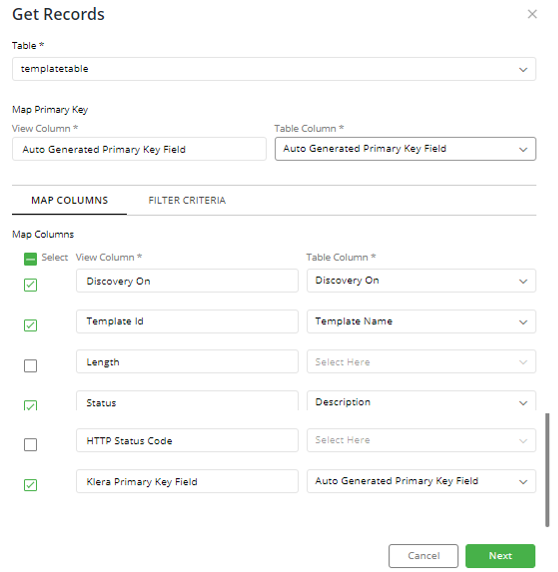
On executing, we will get below form. Please refer the below snippet,
- Map columns
- Status (C1) is mapped to ‘Description’ column of Template Table. On operation completion (C1) will have values D1, D2, D3 of description column.
- Template ID (C2) is mapped to ‘Template Name’ column of Template Table. On operation completion (C2) will have values N1, N2, N3 of description column. Similarly, it is for ‘Discovery On’.
- Length column will not have any mapping available. It is of integer datatype, and there are no columns of Integer(number) data type in Template table. So, it will show up empty. We can uncheck the given column.
- Map Primary Key
- User can map Primary key of the container table with primary key of native table. It is not necessary values of both Primary keys should be same.
Datatype of both these columns should be same i.e. String=String, Int=Int
- For example, in MySQL employee_ID in employee table, and employee_ID in salary table. To get the result from both the tables employee_ID value should be same.
- Although, in Gathr Analytics we only need to check if both columns are same of datatype i.e. string, integer, float, etc.
- Filter Criteria.
- This is used to limit the records based on certain Filter criteria and mapping columns.
- Consider, given column ‘Discovery on’ has a value ‘Accounts’ in a container. This value ‘Accounts’ is searched in ‘Discovery On’ column in Template table, if the same value exists, Gathr Analytics will retrieve the records from Template Table.
- Users can update the condition as per the requirement
How to search record in Native Database?
Users can select a column from any container of an Editable App to get data of Native database’s table contextually.
- Select the column of the required container to filter the data > Right click > Database connector > Native database > Search record.
- User will get a form to ‘Reduce Data’ to apply necessary filters. Next, another form will pop-up to ‘Search Records’.
- Please select the table from the drop-down.
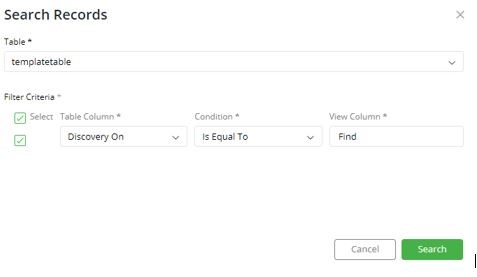
- Kindly refer to the below snippet, and check Filter Criteria from right to left.
‘Find’ column of the given container is mapped to the ‘Discovery On’ column of the Template Table.
- Consider, given column Find has a value ‘Accounts’. This value ‘Accounts’ is searched in ‘Discovery On’ column, if the same value exists, Gathr Analytics will retrieve the records from Template Table. Criteria will be using ‘AND’ condition.
- Users can update the condition as request and click on Search.
Does data scope filter persist on executing an operation on context level?
Data scope filter is a visualization level filter to reduce the data of a specific visualization only. Consider, we have executed operation to get JIRA boards. Applied data scope filter where Board type contains ‘Scrum’. Records is reduced to 1. This is how a data scope filter works. Table 1: +—————-+——————+ |Board type| Board name| +—————-+——————+ |Scrum | Production | |Kanban | Dev | |Kanban | Stage | +—————–+—————–+
Table 2: +—————-+——————+ |Board type| Board name| +—————-+——————+ |Scrum | Production | +—————-+——————+
Now, let’s consider Table 2.
We select ‘Board name’ column to get its JIRA Sprint.
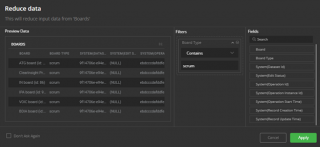
Gathr Analytics will take all the context values i.e. Production, Dev and Stage, user will a pop up a reduce data form. This is called Pre-filter.
So, filter applied on the data scope level is not equal to pre-filter. Data scope filter doesn’t persist at pre-filter level, as data scope filter level is confined to visualization level only
In the above case, we must apply Board type = Scrum and then execute Sprint operation. Please refer the given snippet.
I have executed GitHub operation to fetch the repositories, does Gathr Analytics download/clone it on the hosted server?
Gathr Analytics does not download any repositories on the server. We have fetching the data from REST APIs exposed by GitHub. It is similar of getting response on the API tools like Postman, or CURL response we get on Linux terminal. Gathr Analytics does not download any data, and it is transparent and discrete.
What does ‘aborting the long running execution’ on Gathr Analytics mean?
Consider, if you are fetching JIRA history operation, and the data is huge. Now, if this operation is running for more than 3 hours, it is aborted by Gathr Analytics. This is an expected behavior of Gathr Analytics. Most of the cases, operations are completed less than 3 hours. However, we can update and increase the timeout on Gathr Analytics.
Why I am unable to purge the data set even though there are no hidden containers?
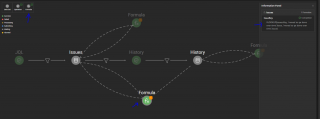
If there are any formula associated between 2 datasets, user will be unable to purge it. Please go to execution graph, and check mark Formula. Kindly the refer the below snapshot. We see there is a formula associated between Issue and History dataset. Remove/delete ‘IssueKey’ formula present in Issue’s data. Doing so, click on Purge. Gathr Analytics will purge History data set.
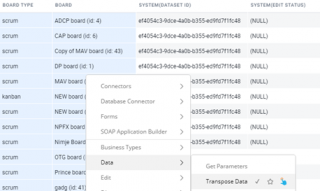
How to Transpose data in Gathr Analytics?
- Select data from the grid on which you would like to perform Transpose Data operation
- Then right click by keeping the data selected and then go to Data Option in the list
- Select Transpose Data option as shown in the image below.
- This will Transpose your data.
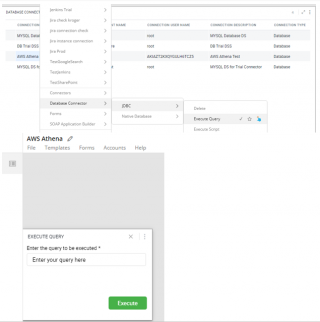
How to execute query on AWS Athena?
To execute a query on the configured AWS Athena connection, please follow the steps below.
- Right-click on Gathr Analytics floor->Database Connector->JDBC->Manage->Show. Click and Drag the dataset on the floor.
- Right-click on Athena Connection Name->Database Connector->JDBC->Execute Query
- You will get a form, please enter the query, and click Execute.
Which Databases are currently supported on Gathr Analytics?
Gathr Analytics integrates with many Databases, list of supported databases are as follow: –
- Database Category: Timeseries InfluxDB
- Database Category: JDBC MySQL Oracle DB2 MariaDB PostgreSQL SQLServer TeraData AWS Athena
Do Gathr Analytics support for AWS Athena JDBC Connection support?
Yes, Gathr Analytics does support for AWS Athena JDBC connection support.
What is Gathr Analytics Elastic Service?
Gathr Analytics has embedded ElasticSearch of its own and it is deployed on the same machine where Gathr Analytics is deployed. Gathr Analytics stores data generated by the users through an Exploration or an app in this ElasticSearch.
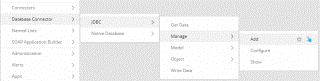
How to Connect with Databases using Generic Read & Write in new Gathr Analytics UI?
Please follow below steps to connect with Database using generic Read/Write. Step 1. Connect to the required database.
- Right-click on Gathr Analytics floor. Database Connector-> JDBC-> Manage -> Add.
- Fill the required details in “Connect to a Database” form.
- Provide a user-friendly name for the database connection.
- Select Database Category and Type from the dropdown list.
- Add a new account or choose an existing one to connect to the database.
- Enter connection URL or IP: Port and credentials in Server Information section.
IMPORTANT: Please check “Add model for the connection”.
- Click on Connect. Upon successful connection, you will receive the list of all Views, Triggers, etc. in the view panel.
Step 2: Fetch Data from a table.
- To fetch data from the added connection, do a right click on the floor -> Database Connector-> JDBC -> Get Data.
- In the first form, choose your Connection, Schema, Table and Columns and click on Submit.
- In the second form, you can add filter criteria if required and click Submit. Data will be available in the View Panel.
Step 3: Write data to a table.
- Right click on the header of the container you want to write to table, Database Connector-> JDBC-> Write Data. In the first form, add filter criteria if required and apply.
- In the second form, choose Connection, Schema, Table, Action (Add/Update/Delete) and click next.
- In the third form, map the table columns with data set column and submit. Quick tips: Database should be accessible from Gathr Analytics machine.
Can Gathr Analytics Connect with other Databases like – Elasticsearch, SQL, etc.?
Yes, Gathr Analytics can connect with any database that has JDBC/ ODBC type of connectivity.
Where would our data be residing if we plan to use Gathr Analytics? Will it be on-premise or cloud?
Gathr Analytics is available as in – premise solution wherein your data will be residing in your premise within your server. We are coming up with a SaaS version of Gathr Analytics in couple of months, where the data will be on cloud following standard protocols & compliance.
What is a Gathr Analytics native database? How can we access and write to it?
If you have some use case that needs you to store data but you don’t have any database to connect to, then you can make use of Klera’s internal database to write data into it as well as fetch data from it. For example, you may have an app that runs on one project of Jira at a time and calculates some important KPIs for you. You may want to run this app for several other projects but would not want to lose the calculated KPIs.
In such a case, one can take the following steps to ensure a smooth integration of all KPIs for different projects and then have a separate dashboard for a roll-up presentation:
- Save this app as an Exploration (Editable App)
- Extend this app to include a write-back step on the calculated KPI(s) straight away from the table of Jira (on Gathr Analytics) to Klera’s native database.
Please note, that you don’t have to define any structure for creating a table to Klera’s database. You simply select the table and write it back by following the steps mentioned in the URL below. Just make sure that you keep this table’s execution mode (click on the container’s three-dot menu at the top right, Select Execution Mode and Set it to Append Mode) to Append All/Unique Mode based on requirements.
Once you have done this and ran the app completely once, resave this Editable App as Non Editable App with Reset App function kept On while saving.
That’s it. Now you can run this app on other projects and keep accumulating the calculated KPI(s) to Klera’s database.
Later, you can fetch data from this Native Database into another Exploration (Editable App) and make dashboards on them to see all the KPIs rolled up for several projects.
Does an Author needs to create all generic read-write operations again if the database environment is migrating?
We have an option on Database connector, using which a user can edit the connection string, credentials and point to a different database.
- Open Gathr Analytics Exploration and right-click on the floor
- Go to Database Connector > JDBC > Manage > Configure
- Select Database Connection from the dropdown list and click Configure Considering new database getting added, it will have the same schema to make current datasets work.
If there is any change in the database table structure or table name, then Gathr Analytics author will have to create a new write-back and read operations from Database Connector.
How to control the size of incoming data? Pre-Filters & Post-Filters
Gathr Analytics understands that the data fetching can lead to quite enormous amount of data which might not be necessary. Hence, to control the size of this incoming data, Gathr Analytics has given 2 Filters : Pre-Filters & Post-Filters.
Pre-Filter – To provide a condition even before the data fetching starts. This Filter automatically comes up when you select the whole column instead of a particular item. Here, you can create filter(s) on conditions of parent dataset on the basis of which the data can be further fetched. For Example, You select the whole Project column and create a Pre-Filter where Project Start Date (other column from same dataset) is after a certain date. Then Issues operation will fetch the Issues dataset whose Projects started after the pre-defined date.
Post-Filter – This filter is created after the data is fetched once and user feels that this amount of data is not needed, then he can provide a filter on existing dataset by using standard columns of the same dataset to re-fetch the data again based on the condition applied. To apply Post-Filter, you have to go to “Execution Graph” and look for the filter icon before the Filter Icon before the dataset node. Click that and apply the Post-Filter condition.
Please note, you can also edit the Pre-Filters on the Execution Graph by Clicking on the Filter Icons before the Dataset Node.
A green colored Filter Icon means that the Pre or Post Filter is applied while fetching the data.
How to create joins?
Gathr Analytics provides the following types of Joins and Unions.
- Inner Join
- Full Join
- Cartesian Join
- Left Join
- Right Join
- Union
- Union All
To carry out the Joins Operation, you can:
- Select Column A from the container of Dataset X and Column B (by holding the Control Key) from the container of Dataset Y (Joining on the basis of primary key provided by you) > Right Click > Join > Select the type of Join
- Simply Select Container A and Container B without specially selecting any column (joining on the basis of primary key decided automatically by the system) > Right Click > Join >Select the type of Join
2 Important points to consider while carrying out Joins are:
- Right Click on which container after you have selected the containers/columns? – Remember, the Container where you Right Click will always by the Right Dataset (whether you select Left Join or Right Join). It doesn’t matter in other cases where you Right Click.
- While carrying out Unions, make sure that the data structure (columns and their types) are same for it to be successful.
How to Implement “Write Back”?
There are 2 different ways Gathr Analytics allows users to “Write back” the data. A. JDBC B. Native Database (Gathr Analytics Elastic Service) Steps to “Write back” the data for both methods are mentioned below. A. JDBC In order to write back the data to JDBC, select the desired container of which the data you would like to write back.
- Right-click on container header > Database Connector > JDBC > Write Data
- Apply desired data filters on the “Reduced Data” panel on the screen and click “Apply”
- Write Data Panel will pop up. Select the desired options from this panel.
- Connection: Select the desired database where you would like to write back
- Object Group: Select the desired schema where your destination tables are located
- Object: this is where you select the desired table to write back the data
- Action: Select the desired options for the given list
- Add New Record(s): given the fact that no similar record exists corresponding to the data you have in Gathr Analytics container, select this option.
- Update Existing Record(s): Update the existing records in the database table with the records that you have in the Gathr Analytics container
- Delete Existing Record(s): Delete the existing records in the database table which are related to the data in Gathr Analytics container
- After the desired selection, click “Next”
- “Map Fields” form will open
- Mandatory fields: User need to map the primary column of the dataset to the database table’s primary column
- Optional Fields: User need to map additional columns that need to writeback to the database table to keep the relevant data
- Then click “Submit”
This will create Execution Detail Dataset. If the writeback is successful, the status will successful otherwise it will give the user the error message if the writeback fails.
Now let’s focus on the steps of writing back to Native Database in Gathr Analytics.
B. Native Database (Gathr Analytics Elastic Service) In order to write back the data to Native Database, select the desired container of which the data you would like to write back.
- Right-click on container header > Database Connector > Native Database > Add Records
- Apply desired data filters on the “Reduced Data” panel on the screen and click “Apply”
- Add Records form will pop up. Select the desired options from this panel.
- Add Records To A New Table (this will create a new table)
- An Existing Table (if the table already exist, select this option)
- Select “A New Table” option and provide New table name and click “Next”
- “Add Additional Column To Table” form will pop up. Select the desired options as below.
- Select Primary key Column for the Dataset: select the desired column which you like to keep as primary key while writing data to a native database table
- Select Columns: Select all the columns which you need to write back to the table
- Click “Add Records”
- This will generate Execution Detail Dataset. This will return all the columns and records for which write back was performed.
- In order to check if the write back for all the records was successful, look for the status column.
- Success: the record was successfully written back into the table
- Failed: the record failed during the write-back
What are the ways to refresh data?
There are various ways in which data can be refreshed:
- App Level/Exploration Level Refresh – This can be done by going to File Menu and Re-Executing the complete App. This way, each and every dataset refreshes.
- Dataset Level Refresh – This can be done by going to Data Panel and selecting the Dataset of your choice. Then go to 3 dot menu of it and select Re-Execute to Refresh that dataset. But, keep a note the all the children dataset which are dependent on this dataset for contextual operation run will also get refreshed.
- Container Level Refresh – Containers are the views which are in the tabs. Selecting any container, going to its menu and Re-Executing refreshes the corresponding dataset and subsequently all the other containers based on this dataset. But, keep a note the all the children dataset which are dependent on this dataset for contextual operation run will also get refreshed.
- Interactive Refresh – At all the above mentioned levels, their is also the option of Interactive Re-Execution where any contextual data fetching can be refreshed on the basis of other context from its parent dataset through a pop-up form. For example, Dataset A has n Projects and you selected Project pqr to fetch its Jira Issues. During Interactive Re-Execution, there would be a form popping up which will give list of all the projects where you can select other project xyz to fetch its issues and the data and corresponding containers will update accordingly.
How to Delete/Purge Dataset(s)?
To Delete or Purge the datasets, one should simply go to the Data Panel in the Right of Screen > Hit the Icon of Purge Datasets at the top right of Data Panel. The 3 conditions which datasets should fulfill to get purged/deleted are:
- There should be no views on any tab/page (visible or hidden)
- The dataset should not have any formula column in it or any other dataset should not refer to its column(s) through their formulas
- The View Panel (top panel at the right) should be empty
How to access the data lake/data warehouse?
As Gathr Analytics does not create a Data Lake or Data Warehouse, the complete data is fetched and stored in different data sets which can be accessed through Data Panel.
Every operation, whether a direct Floor Operation (fetching data for a particular business object directly by right click) or a Contextual Operation (fetching data for a particular business object by limiting its scope by selecting particular column(s)/data points on column(s)) will fetch a data set separately and will be listed in Data Panel.
Can we export the data behind a visualization?
Yes, we can export the data behind container/visual. Right Click at the top blank space of container > Export > Select whether “filtered data” or “complete data” a. Complete Data: This will export all the rows of the dataset irrespective of any applied filters. b. Filtered Data: This will export the rows visible in the container as per the applied filters.
A CSV would be generated.
Can I create a data set on Gathr Analytics itself?
A data set can be created on Gathr Analytics through following steps:
- Right Click on the Floor > Formula > Create Data
- A form will open up where information of the data set can be given and it is quite intuitive where you will be able to create data easily through it.
How to edit data on Gathr Analytics?
To edit data on Gathr Analytics for “temporary” purpose, we can use the Edit Operation which exposes on a container when:
- Go to Container and select and column > Right Click > Edit > Select “Edit Data”
- For the very first time, it will give a warning message which means that The Changes Made Through Data Edit Will Be Over-Ridden By the Re-Execution of Exploration.
Hence, it is a temporary method.
Then a Pop Up Data Set will open up where you can edit the data points header and data under columns by double-clicking on them.
To achieve permanent changes which should not be over-ridden through re-execution, you have to make use of formulas.
How to delete a data set?
Deleting or PURGING in Gathr Analytics can be done through Data Panel itself by clicking on the Bin icon at the top right of the Data Panel
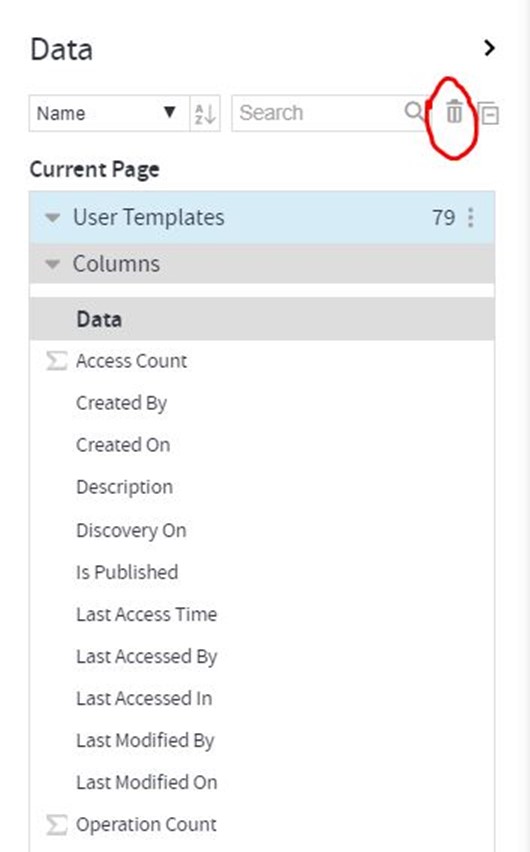
But, there are 3 check-points which a user needs to ensure else Gathr Analytics won’t delete that data set. The 3 check-points are:
- There should be no visualization/container of that data set on any of the Tabs
- There should be no entity or related template result of that data set existing on the View Panel
- There should be no formula on that data set, neither should be any formula on other data set referring to this data sets column(s). E.g., VlookUp on other data set fetching results from the one you want to delete. If all the above 3 criteria are met, then only the data set will get deleted. Please note, we cannot selectively delete a data set.
Can a user be barred from editing an existing data set in Gathr Analytics?
Yes, We can control whether a data set can be re-executed/refreshed by another user by the following approach:
- Got to Data Panel > Got to required Data Set > Open the Data Set Menu by clicking on the 3 dot menu at the right of data sets name > Go to “Set Access” > Select “Read Only”
- Now your data set cannot be re-executed even if the whole exploration is executed.
- This means, in case of contextual data fetching from other data sets, that data sets prior to the one set to Read Only will get re-executed but the data set on Read-Only and data sets after it will not be re-executed to latest data.
Of course, the user, with whom exploration is shared, if, has the rights and permission to see the option of Set Access can re-adjust the selection to Read & Write for that data set.
To know more about Sharing and Collaboration, access our other topics on community.
How to assess which container/visual belongs to which data set?
To find out which container/visualization is made from which data set, follow the mentioned steps:
- Open the Data Panel (preferably in every data set collapsed by licking on Collapse Icon Next to Delete/Purge icon) > Go to the tab of your preference > Hover the Mouse over the Container(s) > Respective Data Sets will start getting Highlighted in Light Blue Color
- We can do it vice-versa to assess which all containers are created for a data set and in which tabs they are situated by hovering the mouse over the data set and respective containers and tabs will start getting highlighted.
- Make sure you have un-hidden the hidden tabs while finding containers for a data set.
I see a data set in the view panel but I dont see any container representing it in any of the tabs. How to create a Visual/Container from it?
To create a view from existing data set for which there is no view currently on any tab, please take following approach:
- Data Panel > Required Data Set > Click the Side Arrow at the Left of Data Set’s Name to Open all the Column Names > Click and Hold any of the column (Multiple Columns can be selected by Control + Click) > Drag to the floor and Release the Click
This will create a container with basic Grid View of the column(s). Now, we can alter/update the view further.
How to find out which columns were used contextually while fetching the data (contextually) through another data set?
A user can access the Operation Details on any of the visual created on the data set.
- Click on the 3 Dot menu at the top left of a container > Click Operation Details
- This will give us a tool tip box of information where the selected Column/values are listed under the header Parameters.
Following is the image of the tool tip:
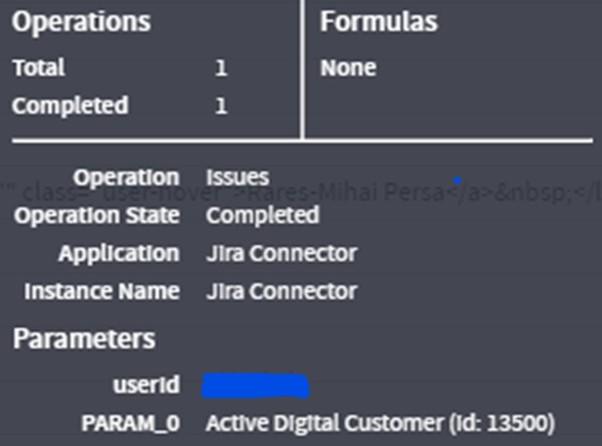
Soon we are coming up with the information of the Data Scope Filter applied while running the contextual information along with the Name of Columns.
What is a Gathr Analytics native database? How can we access and write to it?
Gathr Analytics supports writing to its own (native) dataset and enable user to quickly save data required for solving any use case in Gathr Analytics itself instead of depending on any external database. Native database help you to perform:
- Save data of any dataset into Native database. You can select column to save in native database.
- Read from the native database in the same exploration or another exploration and create the views or use data as per use case workflow.
Steps to save dataset in native:
- Right click on the container which you want to save in the native dataset.
Note: Adding records to Native is a container level operation.
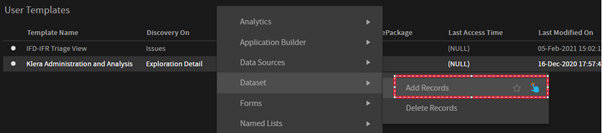
Add the required pre-filter, and in the Add Record form you will get the followings:
Action: Add New Dataset & other option is Select Existing Dataset.
You can select New Dataset if you are writing dataset for the first time. Note: Primary key in the dataset will remain same as the primary key of your dataset on Gathr Analytics.
Enter the name of the dataset if you choose “Add New Dataset” or choose from the list if you choose “Select Esisting Dataset”.
Select the column you want to write into the dataset from the source dataset. Upon successful execution, it will generate dataset execution which will give the details and status of adding/updating records.
Steps to read from native:
- Right click on the floor -> Get Records. Choose your dataset from which you want to get records.
- You can also execute List Dataset and select any specific dataset to get data.
I don’t have any data system or database to connect to. Can I still use Gathr Analytics for solving my use case?
Yes, you can still solve your use case by making use of Klera’s schemaless database which is very simple to use in terms of writing data into it as well as fetching data from it.
To write any data into it, simply, Right Click on the blank space within the container from which you want to write the data and you will get the option of “Dataset”. Go to Add Records and you can write the data present “In the Container” to the Klera’s Schemaless Database.
To fetch/get or Delete any existing dataset, you can Right Click on the floor, go to “Dataset” and then select the appropriate options to carry out your operation.
One thing to consider is that too much of Data Load might affect Klera’s performance. Hence, get in touch with our support team to understand the amount of data that can be easily handled, based on your system configuration.
I am concerned about the security of the data that it should be accessed from Gathr Analytics by the users who don’t have access to that particular item. How does Gathr Analytics handle this?
To protect your data from accessing by other Gathr Analytics user who is not intended to see this, you can use “Row Level Filter”. You can define multiple filter and assign them to the respective user or role. This is applicable only on the exploration level shared in Read-Only mode. To use the row level security, please follow the below steps:
- Find the visual data, apply the visual filter i.e., Exclude the required data or use Keep-Only on the required data.
- Once a filter applied, you will see entry in the bottom left
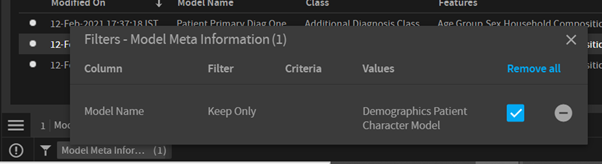
- Click on the funnel icon and choose Create Filter. This will open up a form where you can enter the Filter Name and assign to the user with who you want to share this exploration with Row Level Security enabled.
When other Gathr Analytics user open the shared exploration, they will see only the data which they are intended too as shared by owner of this exploration.
What happens if the data is being fetched and I close Gathr Analytics?
If data is being fetched or an operation is getting executed and we close the browser/ Gathr Analytics, the process will continue to run in the background and it will be completed after all records are fetched successfully. Now, if we log in and pick up from where we left, data will be updated on exploration.
How to assess the data type of a field/column on Gathr Analytics?
To know the data type of a field/column you can follow below steps:
- Right-click on column –> Business Types –> View Existing
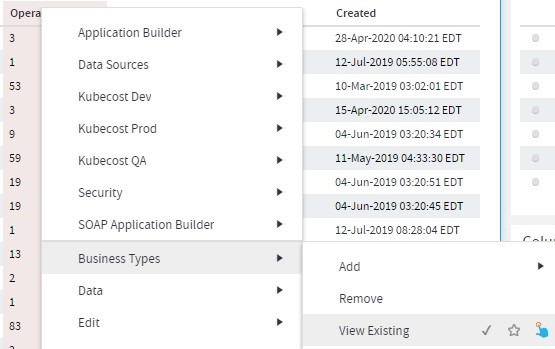
- A view will be generated. Bring it on the floor.
- Please check the data type column to get the necessary information
Where does the data sit when it is called on Gathr Analytics?
When we fetch the data from tool(s), we get a dataset and a view is render in view panel. We can drag it and get that view on the floor of Exploration.
Data continues to stays on Exploration when it is called on Gathr Analytics and it is stored in Gathr Analytics Elastic service.
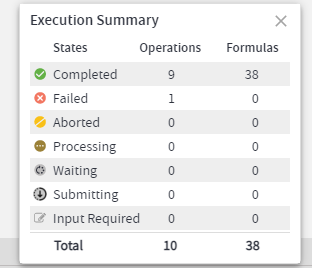
How to know whether the operation ran completely fine or not?
We can check the status of an operation along with its start time, end time, parameters passed and user who ran the operation, etc. with below approaches:
- Click on three dots menu on the top right corner of a container and click Operation Details.
- We can check status of operations from Execution Summary present at bottom right corner.
Another way to know status of an operation is through Execution Graph.
- Click on execution graph present on bottom right corner.
- Click on any operation to view its details.
Also, you can select the history tab and type “Fail” to get all the operations which are failing. When you expand that operation and hover over (!) you will the get the error message.
How to know the parent dataset of a child dataset?
To know the Parent Dataset of any Child Dataset/Contextual Dataset, take the following steps:
- Get the name of the Child Dataset by opening the Data Panel and hovering the mouse over the respective container (view). This will highlight the dataset and we can read its actual name.
- Go to the 3 Dot Menu of that container (view) at the top right of the container and Left Click to open Container Menu Options where you have to select “Operation Details”. This will give us information like – Name of the Parent dataset, Which Operation was performed to fetch this dataset, Which columns were selected to run the contextual operation.
- Now you can search for the Parent dataset by its name in the Data Panel and also find its containers (views) by hovering the mouse over this dataset which will highlight the page where the containers are kept and then going to that particular page and hovering mouse over the dataset will highlight the respective containers.
You may also take a look at the “Execution Graph” to see complete parent-to-child relationships between all the datasets.
How to get the execution mode of any dataset?
You can get the execution mode of any dataset by clicking on three dots menu at top right corner of a container. Here you can see execution mode Manual/Schedule/On operation Complete.
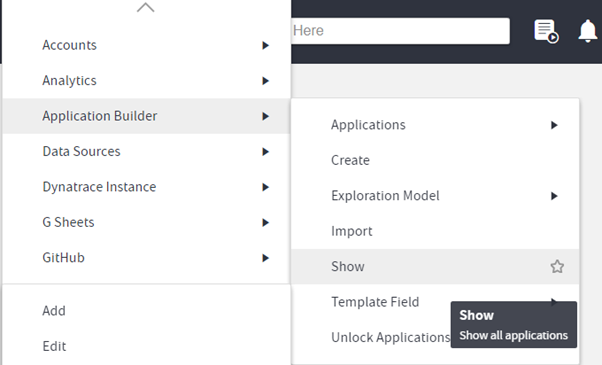
How to know which column/field to right click and find the contextual operation?
To know what to select to go ahead in your usecase for a connector, you can perform below steps:
- Right click on the floor and go to Application Builder -> Show.
- Bring the Dataset on the floor and right click on the Application/Connector name(the one which you are using) and goto
- Application Builder -> Operations -> Show
- Bring the dataset on the floor.
- Here, you will see all the operations and,
- Under the column Business Type(s), you will see the business types of the columns you need to select to move further.
For example, let’s take a case of Jira Connector Step-1
Step-2
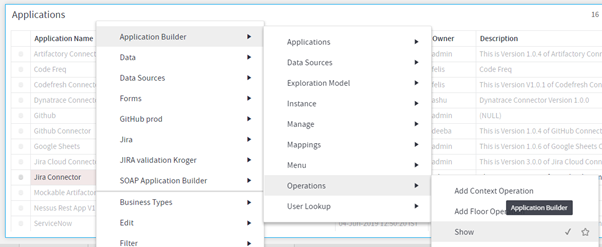
Step 3,4,5
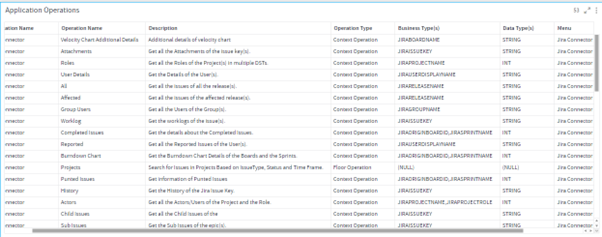
Once you see the business types corresponding to the Operation Name, you can find out the business types of your DST and select the relevant columns to move ahead.
Can i export selective data from Gathr Analytics?
You can export selective data as well as complete data from Gathr Analytics. Gathr Analytics enables you to export data from any dataset available on the floor. While exporting you can apply the Pre-filter which will enable you to export the selective data in a CSV format.
You need to follow the below steps:
- Right click on the container header.
- Goto Export -> Complete Data. You can apply the pre-filter in you want to reduce the data.
- If you select the Export -> Filtered Data, it will download the data as per the applied datascope.
How does Gathr Analytics ensure data security? In the same dashboard I want to share data as per user access rights. How do I achieve this?
Gathr Analytics takes care of data security in various ways to help users achieve the desired result along with keeping the check on data security. Following are the ways:
- Share work as a Template or App – Template and Apps work like a macro which performs all the data fetching, computations, and visualizations but for the connector/data source instance of the receiver of the template.
- Create Filter – This is User/Role Based Filter that is created on the visual level filter set for specific Role(s).
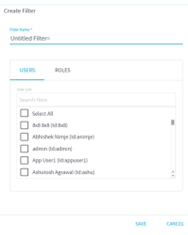
To apply this filter, click on the particular part of the view so that the whole dashboard filters/gets highlighted accordingly. Now go to the bottom left of your screen to click on the Funnel Icon and Select Create Filter. Now, select the particular User or Role for which you want to restrict the filtered view and give a name to this filter.
You can create multiple such filters on the basis of various visual filters for vivid users and roles. They will only see the record filtered for their user/role.
If you have any feedback on Gathr documentation, please email us!