Create CDC Applications
The steps to create a CDC application are as follows:
Go to the Applications home page from the main menu and click on the CREATE CDC APPLICATION option.
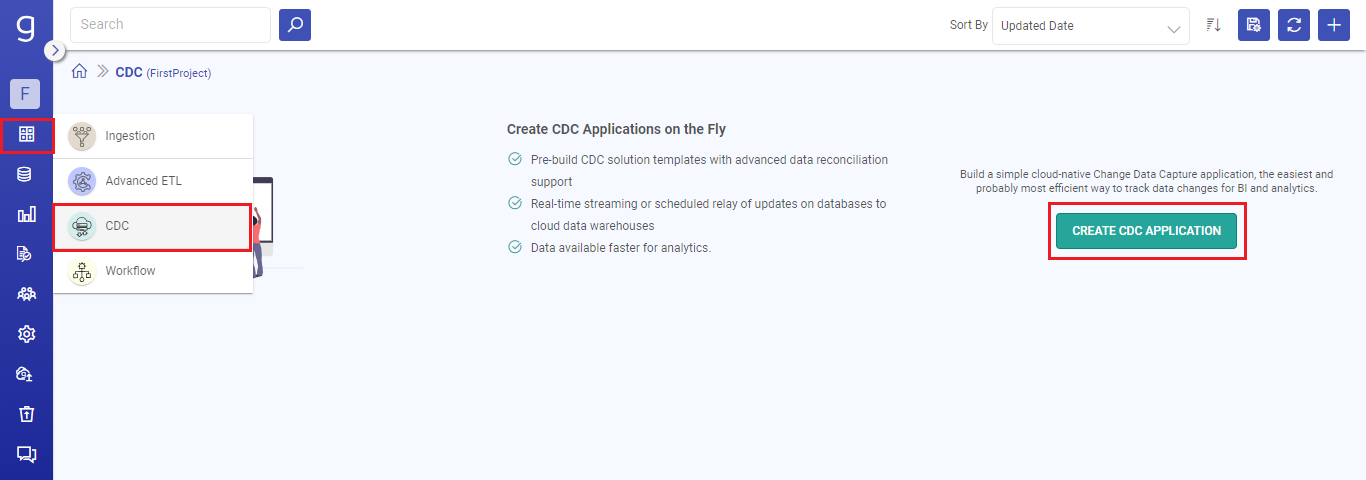
Provide a name for the CDC application to be created and select a source and a compatible target from the available options. Click OK to continue.

The supported templates for CDC applications are:
MySQL to S3/GCS/Snowflake/BigQuery
PostgreSQL to S3/GCS
MSSQL to S3/GCS
Oracle to S3/GCS/Snowflake
Teradata to S3
To continue further with the CDC application creation steps, an example from one of the templates, i.e., Postgres to S3 with the capture method as Incremental Read is described.
You can create a CDC application with other templates for the supported targets by following similar configuring steps as described in this example.
On the Source panel, provide the details for each field as per the table below:
Field Name Description Database Connection Create a new connection or choose any existing one if available in the list of connections in which your table exists, for which you want to capture CDC. This tab has an info Icon, which shows the connection details.Method Method of capturing CDC.
Database Agent: Debezium is a service that captures change data from database in real-time and publish those changes to the Kafka topic, so that downstream applications can consume that data and perform the operations on it.Two more fields namely, Kafka Connection and Read Mode will appear if Method is selected as Database Agent.
Incremental Read: Captures all the records in an incremental manner and will capture only insert and update records.
Database Connector API: In this method, application uses the Debezium database connector API to capture change data from the database.
LogMiner: In this method, the application directly accesses Oracle redo logs, which comprises of the entire set of records of all the activities performed on the database.Kafka Connection Choose the Kafka connection where your database agent is writing data. Read Mode Choose whether you want to create application in batch or streaming mode. Validate the required access by clicking on the Validate option on the bottom right corner of the Source configuration Window.
Here, you request to validate the connection, required privileges, ensure enabling the CDC and the Kafka connection (for Database Agent method).
Once the validation is successful, click the Next button to configure the source table.
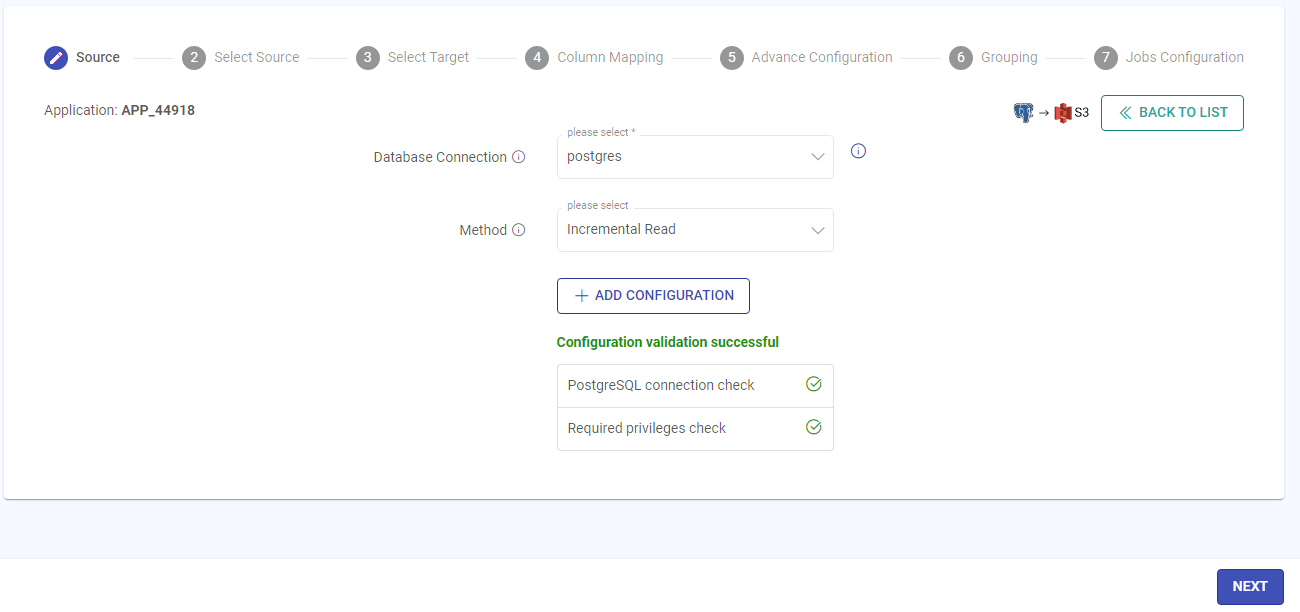
On the Select Source panel, all the source databases will be listed. The tables for the required database can be accessed by expanding the accordion view. Click to choose the required database(s) and table(s). Once the selection is made, click Next.
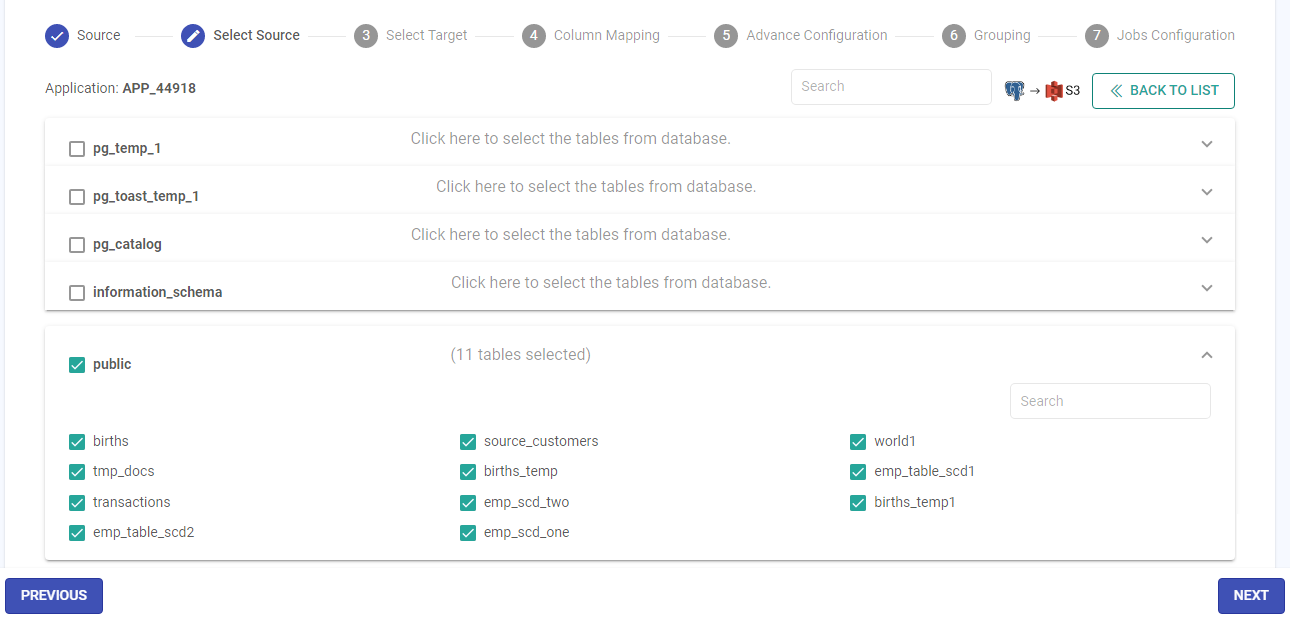
On the Select Target panel, configure the details for each field as per the table below:
Field Name Description Target Connection It is the connection of the target where you want to write the source table data.
Please add a new connection or use any existing one if it is available in the list of connections.
You can view the details of the connection by clicking on the View Details icon.You will need to provide the target path in case of S3.Source Tables It is the table of source database from where you want to read the data.
As you click on one of the Source Tables you can see the target paths available as per configured connection, where you may choose a specific folder within the bucket. Also, there are options to refresh the folders and create new folders corresponding to the source.
There is an option before each source table entry that allows you to map the source table to multiple targets by replicating the entry and an option to do bulk assignment of target tables.Kafka Topic It is the drop-down of Kafka topics out of which you can choose one of the topics where Debezium database agent is configured to write the changed data. This will be visible only for **Database Agent** method.Target Tables It is the table from target connection where you want to write the data. Map the source table to the target table.
As you click on one of the Source Tables you can see the target paths available as per configured connection, where you may choose a specific folder within the bucket. Also, there are options to refresh the folders and create new folders corresponding to the source.
There is an option before each source table entry that allows you to map the source table to multiple targets by replicating the entry and an option to do bulk assignment of target tables.You can create a new path in case of S3.Output Format It is the format of the selected target table.
You can change the format type as required.Output Delimiter It is the field delimiter for the target table data.
It applies only to the CSV format types.Once the target mapping is done, click the Next button to configure the Column Mapping.
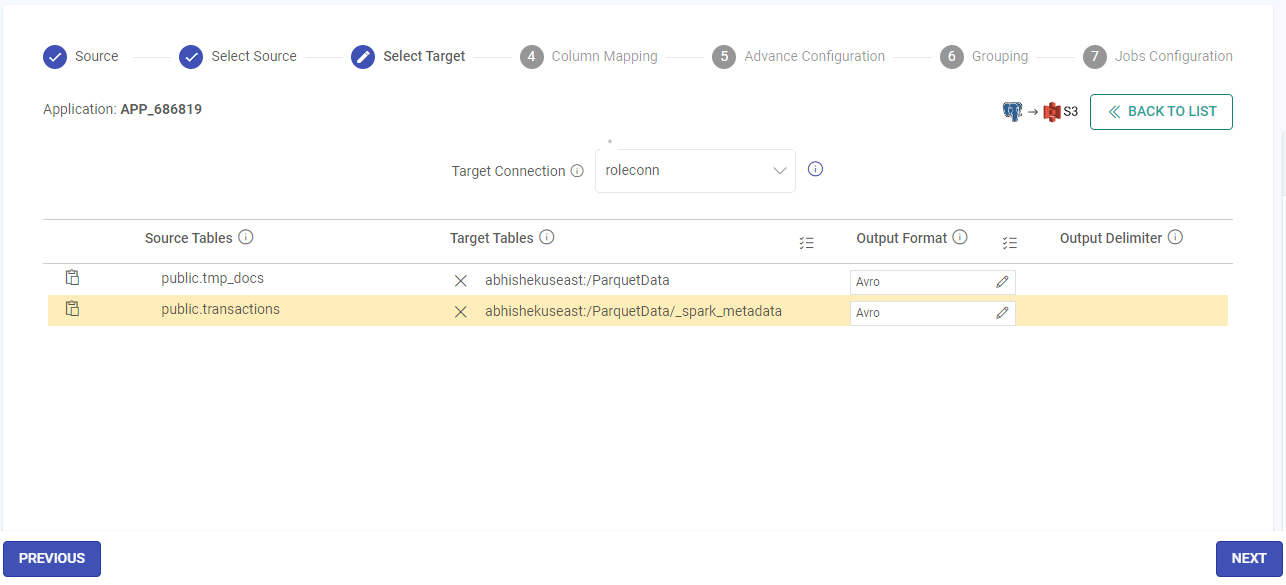
The Column Mapping panel has two major sections: first has the list of Source Table, their corresponding Target Table, SCD Type, version column and deleted flag column and the second is where the Target table columns will open for you to map. Configure the details for each field as per the table below:
Field Name Description Column Mapping first section: Source Table Source Table is the table for which you want to capture the CDC. Target Table Target Table is the table where you want to capture the Source table CDC. SCD Type Select Slowly Changing Dimension (SCD) type that should be used for streamlining your data-flow to capture the CDC.
Type 1:
It will only contain the updated records while selecting.
Type 2:
It will maintain the entire history of the source. Therefore, you need to have two additional columns in case of Type2. One of the columns will maintain version of the record and the other will maintain DELETED_FLAG.
Here, the deleted flag identifies if the record is deleted or not. For the Insert and Update operations on records the deleted flag value will be false and for the delete operation the value will be true.
Append:
Use this mode in case if you want to insert only the source tables.Version Key Target Column is the corresponding column to Source column for which you want to capture Source table CDC. Deleted Flag Key Choose the Deleted Flag key from the ‘Column Type’ column by clicking on the fourth Deleted Flag key icon. Here, the deleted flag represents the current state of record. It identifies if the record is deleted or not. Column Mapping second section: Column Mapping Section In the Column Mapping Section, the columns of both the source and target can be mapped. The source can be mapped with the corresponding columns of the target table.
There could be a case where you have multiple columns in your source table, but, you require to select a few columns and map them to the target table. In this wizard you can do that easily.
There could be a scenario where the source table column names are not like that of the target table names. To map those, you can simply drag and drop the columns against each other and map them.
You may also click on the auto map button at the top right of the screen to map similar name source column with the target column.Source Column Source Columns is the specific column from the source table for which you want to capture CDC. Column to Check Select an integer, long, date, timestamp or decimal type column on which incremental read will work. It is recommended that this column should have sequential, unique and sorted (in increasing order) values. Target Column Target Column is the corresponding column to Source column for which you want to capture Source table CDC. Column Types Partitioning Key:
The Partition key is the prime factor for determining how the data is stored in the table. The key helps you to organize the tables into partitions by dividing them into different parts.
Join Key:
The Join key helps in incrementing the version of record by identifying the availability of similar record in the target table.If SCD type 2 is selected for a MySQL to Snowflake CDC template, then the user needs to create three extra columns in target table, i.e., version_col, deleted_flag, and current_ col.Once the column mapping is done, click the Next button to configure the Advanced Configuration. This is an optional high-level configuration for the data flow created in your application needed for performance optimization and monitoring.
Field Name Description Source Configuration
The source configuration is different for different CDC Methods.Configuration for Database Agent Method Partitions Number of partitions. Each partition is an ordered unchangeable sequence of message that is repeatedly added to a commit log. Replication Factor Number of replications. Replication provides stronger durability and higher availability. For example, a topic with replication factor N can tolerate up to N-1 server failures without losing any messages committed to the log. Define Offset Following configurations are used for Kafka offset.
Latest: The starting point of the query is just from the latest offset.
Earliest: The starting point of the query is from the starting /first offset.
Custom: A json string specifying a starting and ending offset for each partition.
startingOffsets: A JSON string specifying a starting offset for each partition i.e. {"topicA":{"0":23,"1":-1},"topicB":{"0":-1}}
endingOffsets: A JSON string specifying a ending offset for each partition. This is an optional property with default value “latest”.i.e. {"topicA":{"0":23,"1":-1},"topicB":{"0":-1Connection Retries The number of retries for component connection. Possible values are -1, 0 or any positive number. If the value is -1 then there would be infinite retries for infinite connection. Fail on Data Loss Provides option of query failure in case of data loss. (For example, topics are deleted, or offsets are out of range). This may be a false alarm. You can disable it when it doesn't work as you expected. Batch queries will always fail, if it fails to read any data from the provided offsets due to data loss. Delay Between Connection Retries Retry delay interval for component connection (in milliseconds). Is Schema Enabled While running the Debezium connector, you have to set the schema.enable property as true, then the checkbox isSchemaEnable should be check marked. Configuration for Database Connector API Method Offset Storage Allows you store the offset of read data. Reset Offset It is to reset the offset from Zookeeper. Replication Slot
(For PostgreSQL only)You can configure the slot to perform the read option from the available slots of database. You can also specify your own slot from here. Configuration for Incremental Read Method Column To Check Select a column on which incremental read will work. Displays the list of columns that has integer, long, date, timestamp, decimal type of values. It is recommended that this column should have sequential, unique and sorted (in increasing order) values. Start Value Mention a value to be set as the base for the incremental read with reference to the selected column. Only the records with values greater than the specified value will be read. Read Control Type You can control the reading of data from database by utilizing three different approaches.
Limit by Count: Here, you can specify the number of records that you want to read in a single request.
Limit by Value: Here, you can specify the value for configured column till the point where you want to read the data.
None: Here, you can read the data without specifying any limit.
From what value of columnToCheck, the data to be read.Enable Partitioning Read parallel data from the running query. No. of Partitions Specifies no of parallel threads to be invoked to read from JDBC in spark. Partition on Column Partitioning column can be any column of type Integer, on which spark will perform partitioning to read data in parallel. Lower Bound/Upper Bound Value of the lower bound for partitioning column/ Value of the upper bound for partitioning column. Configuration For LogMiner method Use Pluggable Database Select the option for 12c multi-tenant databases. Pluggable Database Name Name of the pluggable database that contains the schema you want to use. Use only when the schema was created in a pluggable database. Operations Operations for creating records.
INSERT
DELETE
UPDATEDatabase Time Zone Time zone of the database. When the database operates in a different time zone from Data Collector. Maximum Transaction Time Time in seconds to wait for changes for a transaction. Enter the longest period that you expect a transaction to require. Default is 60 seconds. Log Miner Session Window Time in seconds to keep a LogMiner session open. Set to larger than the maximum transaction length. Reduce when not using local buffering to reduce LogMiner resource use. Default is 7200 seconds. Max Batch Size (records) Maximum number of records processed at one time. Keep values up to the Data Collector maximum batch size. Default is 1000. LogMiner Fetch Size Minimum number of records to fetch before passing a batch to the pipeline. Keep this value low to allow the origin to pass records to the pipeline as soon as possible, rather than waiting for a larger number of records to become available. Lower values can increase throughput when writes to the destination system are slow. Default is 1. Query Timeout Time to wait before timing out a LogMiner query. Default is 300 seconds. Start From Start from is the point in the LogMiner redo logs where you want to start processing. When you start the pipeline, Oracle CDC Client starts processing from the specified initial change and continues until you stop the pipeline.
From the latest change
The origin processes all change that occur after you start the pipeline.
From a specified datetime:
The origin processes all change that occurred at the specified datetime and later. Use the following format: DD-MM-YYYY HH:mm:ss.
From a specified system change number (SCN)
The origin processes all change that occurred in the specified SCN and later. When using the specified SCN, the origin starts processing with the timestamps associated with the SCN. If the SCN cannot be found in the redo logs, the origin continues reading from the next higher SCN that is available in the redo logs.Target Configuration
Target Configuration varies for S3 and Snowflake.Target Configuration for S3 Monitor Operation Statistics Monitor Data Manipulation operations such as insert, update and delete functions performed on data of the source tables. S3 protocol S3 protocol to be used while writing on S3. Once the Advanced Configuration is done, click the Next button to configure the Grouping.
In the jobs grouping page, you can group the jobs into a single unit. To create group, specify the group name and click Create. This means the dataflow that you have created can be grouped into a single application or into multiple applications.In certain cases, you may want to combine multiple ‘source to target’ jobs into one group. You can do this easily by assigning a group name to multiple jobs.
The last step in creating a CDC application is Jobs Configuration. Configure the details for each field as described below:
Common fields for Gathr Clusters and Registered Clusters:
Application Deployment: Option to choose the application deployment on either Gathr cluster or EMR cluster associated with the registered compute environment.
The prerequisite to utilizing registered clusters for running applications is to establish a virtual private connection from the User Settings > Compute Setup → tab.
To understand the steps for setting up PrivateLink connections, see Compute Setup →
Cluster Size: Option to choose one amongst Free Tier, Extra Small, Small, Medium, Large, or custom cluster sizes on which the applications will be deployed.
A cluster size should be chosen based on the computing needs.
The credit points (cp) utilization for each cluster is explained below:
Extra Small: 1 credit/min
Small: 2 credits/min
Medium: 4 credits/min
Large: 8 credits/min
GPU - Powered by NVIDIA RAPIDS: 10 credits/min
The GPU cluster is available only in the Gathr compute environment.The Small, Medium, Large, and GPU clusters can only be utilized with a Gathr Advanced or Business plan.
Also, a custom cluster can only be utilized with a registered compute environment that is available in a Business Plan.Utilize micro cluster if available: Micro cluster option is available for Extra Small Cluster sizes. It uses available free slots on Gathr Compute to optimize the application submission for small scale applications.
Store Raw Data in Error Logs: Enable this option to capture raw data coming from corrupt records in error logs along with the error message.
Additional configuration fields for Registered Clusters:
AWS Region: Option to select the preferred region associated with the compute environment.
AWS Account: Option to select the registered AWS account ID associated with the compute environment.
DNS Name: Option to select the DNS name linked to the VPC endpoint for Gathr.
EMR Cluster Config: A saved EMR cluster configuration is to be selected out of the list, or it can be created with the Add New Config for EMR Cluster option.
For more details on how to save EMR cluster configurations in Gathr, see EMR Cluster Configuration →
The application will be deployed on the EMR cluster using the custom configuration that is selected from this field.
Continue with the pipeline definition after providing the deployment preference.
Save and exit the pipeline definition page.
Once you finish doing the jobs configuration, click Done to create the CDC application.
The CDC application once created will appear on the listing page.
View CDC applications
In the view CDC applications section, Application Components, Groups Status and Operation Statistics can be viewed.

Group Details, Tables Mapping and description of the CDC application can be viewed from the top right side of the View CDC applications section.
If you have any feedback on Gathr documentation, please email us!