Dynamics GP Ingestion Target
See the Connector Marketplace topic. Please request your administrator to start a trial or subscribe to the Premium Dynamics GP connector.
Dynamics GP Ingestion Target allows you to emit the transformed data into your Dynamics GP accounts.
Target Configuration
Configure the data emitter parameters as explained below.
Connection Name
Connections are the service identifiers. A connection name can be selected from the list if you have created and saved connection details for Dynamics GP earlier. Or create one as explained in the topic - Dynamics GP Connection →
Use the Test Connection option to ensure that the connection with the Dynamics GP channel is established successfully.
A success message states that the connection is available. In case of any error in test connection, edit the connection to resolve the issue before proceeding further.
Entity
Tables in Dynamics GP are statically defined to model Dynamics GP entities.
The Entities will list as per the configured connection. Select the entity in which the data needs to be emitted.
Save Mode
Save mode specifies how to handle any existing data in the target.
Append: The source records will be appended in the specified target per the schema mapping.
Update: The data in the designated target will be updated according to the schema mapping and condition key columns.
For Update Mode an additional field will appear:
Condition Key Columns:
Select the data source column(s) that should define the Where Condition to identify the records that should be updated.
For instance, a source column with column name ID is selected to function as a condition key. It will be utilized as a reference to match corresponding target column values. Consequently, the records for all rows in the target entity with matching values for the column “ID” will be updated.
Add Configuration: Additional properties can be added using this option as key-value pairs.
Schema Mapping
In this schema, you can define the source and target column mappings.
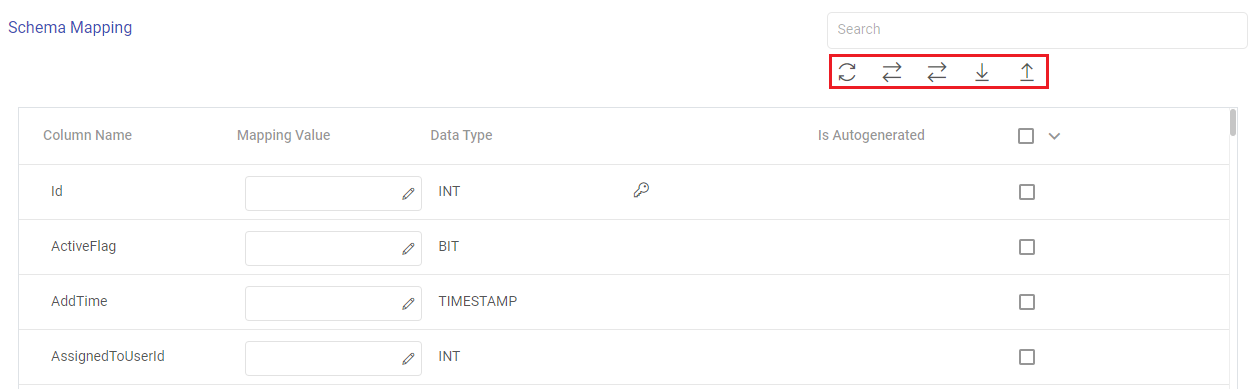
The actions available for the schema mapping section are explained below:
Search: Search the Column Name values to get a specific target column.
Refresh Schema: Use this option to refresh the entire schema mapping section.
Auto Fill: Use this option to match the source and target column names, and automatically fill the source column mapping values to the corresponding target columns.
Auto Fill Sequentially: Use this option to sequentially fill the incoming source column mapping values to the corresponding target columns.
Download Mapping: Use this option to download a sample schema file. Update mapping values in the downloaded file.
In case if Gathr application does not have access to a target table, you can choose the option download schema mapping option to map the target table columns with the source columns during the design time and confirm the data type for each column.
In such cases you can run the application in a registered environment, that has access to all the required resources. During run-time, the application will run on the registered cluster of your choice picking up the configuration values as provided during application design.
Upload Mapping: Use this option to upload the sample schema file with updated mapping values to provide the schema mapping.
The fields visible in the schema mapping section are explained below:
Column Name: The column names as per the target entity selected will get populated in the Schema Mapping section.
Mapping Value: The source column should be mapped for each target column listed in the Schema Mapping section. This operation can be done individually or in bulk using the auto fill action.
Data Type: The data type of each target column is listed, for example, INT, TIMESTAMP, BIT, VARCHAR and so on.
Is Autogenerated: Specifies if any target column(s) are autogenerated, for example, ID column may have autogenerated values.
Ignore None/All/Unmapped: The target columns selected here will be ignored while emitting the data. There are bulk actions available to ignore none of the columns, all the columns or only the unmapped columns.
If you have any feedback on Gathr documentation, please email us!