RDS ETL Target
RDS emitter allows you to write to RDS databases. RDS is Relational Database service on Cloud.
Target Configuration
Fetch From Target/Upload Schema File
The data source records needs to be emitted to a RDS target table.
In case if the Gathr application has access to a target table in the RDS database, choose the option Fetch From Target.
In case if Gathr application does not have access to a RDS target table, you can choose the option Upload Schema File in order to map the RDS table columns with the source columns during design-time and confirm the data type for each column. In such cases you can run the application in a registered environment, that has access to all the required resources. During run-time, the application will run on the registered cluster of your choice picking up the configuration values as provided during application design.
When you select the Upload Schema File option, a Schema Results section will get displayed at the bottom of the configuration page.
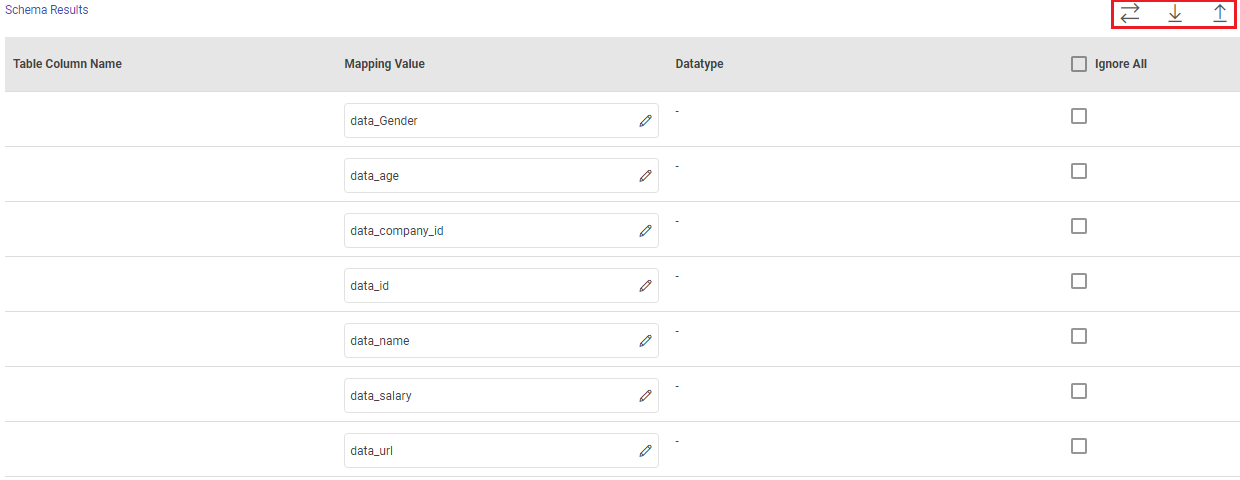
You can then download the sample schema, provide RDS - Table Column Name against mapping values and verify the data type.
Once it is updated, you can upload the saved file to see a sample of how the records from a source column will be written into the corresponding mapped RDS column.
Connection Name: Connections are the service identifiers. A connection name can be selected from the list if you have created and saved connection details for RDS earlier. Or create one as explained in the topic - RDS Connection →
Schema Name: Existing database Schema Names whose tables are fetched. (for MSSQL, DB2 and POSTGRES)
Table Name: Existing table name of the specified database.
Enable Batch: Enable parameter to process batch multiple messages and improve write performance.
Batch Size: Batch Size determines how many rows to insert per round trip. This helps the performance on JDBC drivers. This option applies only to writing. It defaults to 1000.
Output Mode: Output Mode to be used while writing the data to data sink. Select the output mode from the given three options:
Append: Output Mode in which only the new rows in the streaming data will be written to the sink.
Complete: Output Mode in which all the rows in the streaming data will be written to the sink every time there are some updates.
Update: The existing data in the designated target table will be updated, and any new data will be inserted.
Enable Trigger: Trigger defines how frequently a streaming query will be executed.
Processing Time: It will appear only when Enable Trigger checkbox is selected. Processing Time is the trigger time interval in minutes or seconds.
ADD CONFIGURATION: Enables to configure additional properties.
Post Action
To understand how to provide SQL queries or Stored Procedures that will be executed during pipeline run, see Post-Actions →
Notes
Optionally, enter notes in the Notes → tab and save the configuration.
If you have any feedback on Gathr documentation, please email us!