Redshift ETL Target
Write data from databases, data lakes, into Amazon Redshift as a target destination, and then perform complex analytical queries to gain insights into your data.
Redshift works for batch data sources. It uses S3 temp directory to unload data into Redshift database table.
Target Configuration
Configure the data emitter parameters as explained below.
Fetch From Target/Upload Schema File
The data source records needs to be emitted to a Redshift target table.
If Gathr has access to the target table in the Redshift database, choose the option Fetch From Target.
If Gathr does not have access to the Redshift target table, you can choose the option Upload Schema File in order to map the Redshift table columns with the source columns during design-time and confirm the data type for each column.
In such cases you can run the application in a registered environment, that has access to all the required resources. During run-time, the application will run on the registered cluster of your choice picking up the configuration values as provided during application design.
When you select the Upload Schema File option, a Schema Results section will get displayed at the bottom of the configuration page.
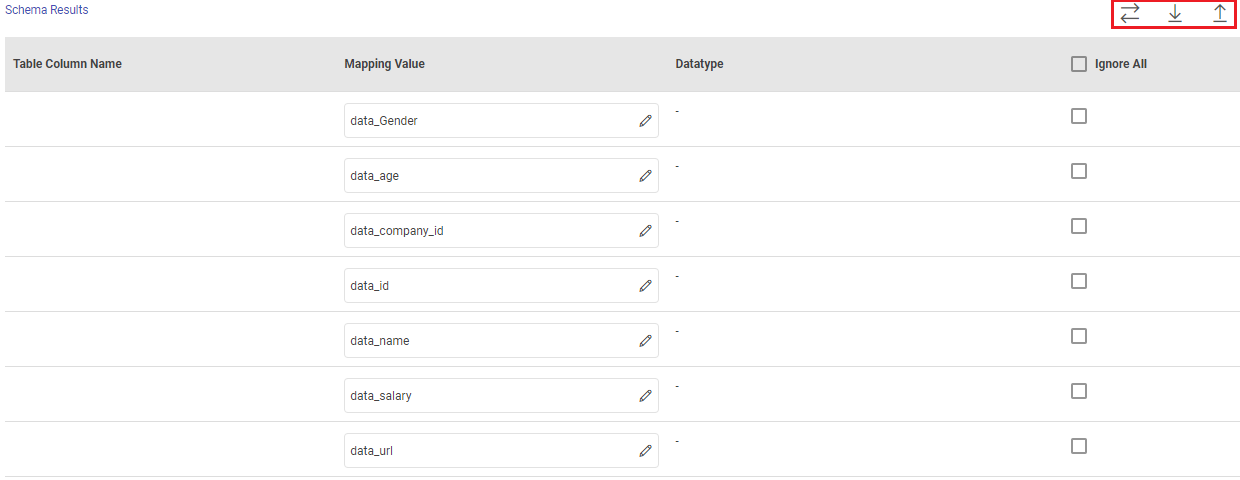
You can then download the sample schema, provide Redshift - Table Column Name against mapping values and verify the data type.
Once it is updated, you can upload the saved file to see a sample of how the records from a source column will be written into the corresponding mapped Redshift column.
Connection Name
Connections are the service identifiers. A connection name can be selected from the list if you have created and saved connection details for Redshift earlier. Or create one as explained in the topic - Redshift Connection →
S3 Connection Name
Select a connection for S3 temp directory from the list if you have created and saved connection details for S3 earlier. Or create one as explained in the topic - Amazon S3 Connection →.
Bucket Name
S3 Bucket name is to be specified where temporary files will be stored while transferring data to redshift.
Schema Name
Select/provide the name of the schema in the Redshift database where you want to write data.
The schema represents the logical structure that organizes tables, views, and other objects within the database.
Table Name
Select/provide the name of the table in the specified schema where you want to write data.
Save Mode
Save mode specifies the behavior when writing data to the target Redshift table.
Choose how to handle data when writing to the Redshift table:
Append: New data records are added to the target Redshift table without modifying existing data.
Overwrite: The existing data in the target Redshift table is replaced entirely by the incoming data.
Ignore: Duplicate records from the incoming data that match existing records in the target Redshift table are skipped during the write operation.
Update: Allows updating existing records in the target Redshift table based on specified criteria, such as matching columns. With Update as the preferred Save Mode, Update Type is to be specified.
Update Type
Choose the update strategy for existing records:
CDC (Change Data Capture) - CDC captures changes from the source system.
SCD (Slowly Changing Dimension) - SCD handles different types of dimension changes.
| Update Type | Description | When to Select |
|---|---|---|
| CDC | Captures changes in source data since last sync. | - Real-time or near-real-time updates needed. - Only changes since last sync need to be processed. - Historical change tracking not a primary concern. |
| SCD | Handles changes in dimensional data over time. | - Dealing with dimensional data. - Historical change tracking important. - Need to preserve historical context for analysis and reporting. |
SCD Type
If SCD is selected as the update type, choose the type of Slowly Changing Dimension strategy to apply:
Type 1: (Keep Latest with Overwrite) updates existing records directly.
Type 2: (Keep Latest with Version) creates new records with versioning.
Join Columns
Define the columns used to match existing records in the Redshift table with incoming data.
This helps determine which records to update based on matching values in specified columns.
Ensure these columns uniquely identify records for accurate updating.
Add Configuration: Enables to configure additional custom properties.
Post Action
To understand how to provide SQL queries or Stored Procedures that will be executed during pipeline run, see Post-Actions →
Notes
Optionally, enter notes in the Notes → tab and save the configuration.
If you have any feedback on Gathr documentation, please email us!