Bedrock Text
The Bedrock Text Processor is a versatile tool, facilitating interaction with an array of foundation models hosted by various AI companies.
This section aims to deliver a comprehensive overview of the foundation models accessible through the Bedrock Text Processor, accompanied by insights into their respective parameters.
Configure the processor parameters as explained below.
Connection Name
A connection name can be selected from the list if you have created and saved connection details for Bedrock earlier. Or create one as explained in the topic - Bedrock Connection →
Select Provider
Amazon Bedrock hosts a variety of foundation models, each with unique strengths and application domains. Pick a provider to access foundation models (FMs) from AI companies:
AI21 Labs
Utilize instruction-following LLMs for diverse language tasks, including question answering, summarization, and text generation.
Jurassic-2 Ultra
Excels in handling intricate language processing tasks and generative text applications.
Robust support for advanced text generation in English, Spanish, French, German, Portuguese, Italian, and Dutch.
Fine-tuning capabilities for optimal performance in custom applications.
Particularly beneficial for complex tasks like detailed QA, summarization, and draft generation.
Valuable asset for sectors such as finance, legal, and research.
The model can process a maximum of 8,192 tokens at once. Tokens are units of text, and if your input text surpasses this limit, you may need to adjust or truncate it to fit within the model’s capacity.
Jurassic-2 Mid
Excels in advanced text generation with optimal quality through fine-tuning.
Suitable for diverse language tasks, making it ideal for QA, content creation, and information extraction.
Applicable across various industries for a wide range of text-related applications.
The model can process a maximum of 8,192 tokens at once. Tokens are units of text, and if your input text surpasses this limit, you may need to adjust or truncate it to fit within the model’s capacity.
AI21 Labs Parameters
These parameters allow you to control the randomness, length, and stopping conditions of the text generated by the AI model based on your preferences and needs.
Randomness and Diversity
The Jurassic models support the following parameters to control randomness and diversity in the response.
Temperature: Modifies the distribution from which tokens are sampled.
Default = 0.5. Setting temperature to 1.0 samples directly from the model distribution.
Lower values increase the chance of sampling higher probability tokens, and higher values do the opposite.
A value of 0 essentially disables sampling, resulting in greedy decoding where the most likely token is chosen at every step.
Top P: Sample tokens from the corresponding top percentile of probability mass.
Default = 1. For example, a value of 0.9 will only consider tokens comprising the top 90% probability mass.
Length
The Jurassic models support the following parameters to control the length of the generated response.
Max Completion Length: Maximum length of the generated completion.
Default = 200
Stop Sequences: Stops decoding if any of the strings is generated.
Example: To stop at a comma or a new line, use [".", “\n”].
The decoded result text will not include the stop sequence string, but it will be included in the raw token data.
The sequence which triggered the termination will be included in the finishReason of the response.
Repetitions
The Jurassic models support the following parameters to control the repetitions of the generated response.
Presence Penalty: Controls the magnitude of the penalty.
Range: 0 <= float <= 5.0.
A positive penalty value implies reducing the probability of repetition.
Larger values correspond to a stronger bias against repetition.
Count Penalty: Controls the magnitude of the penalty.
Range: 0 <= float <= 1.
A positive penalty value implies reducing the probability of repetition.
Larger values correspond to a stronger bias against repetition.
Frequency Penalty: Controls the magnitude of the penalty.
Range: 0 <= int <= 500.
A positive penalty value implies reducing the probability of repetition.
Larger values correspond to a stronger bias against repetition.
Penalize Special Tokens
Fine-tune how the model handles specific types of tokens. Depending on the specific requirements of your task, you can choose to penalize or not penalize these special tokens to achieve the desired behavior in your AI model. It provides a level of control over the model’s sensitivity to different types of linguistic elements.
Whitespaces: Assign a penalty to tokens representing whitespaces and newlines. This can influence the model’s behavior related to spacing and formatting in textual data.
Punctuations: Apply the penalty to punctuations. Determines whether the penalty is applied to tokens containing punctuation characters and whitespaces, such as
;,,,!!!, or▁\\[[@.Numbers: Apply the penalty to numbers. Determines whether the penalty is applied to purely-numeric tokens, such as
2022or123. Tokens that contain numbers and letters, such as20th, are not affected by this parameter.Stopwords: Apply the penalty to stop words. Determines whether the penalty is applied to tokens that are NLTK English stopwords or multi-word combinations of these words, such as
are,nor, and▁We▁have.Emojis: Exclude emojis from the penalty. Determines whether the penalty is applied to any of approximately 650 common emojis in the Jurassic-1 vocabulary.
Amazon
Access text summarization, generation, classification, open-ended Q&A, information extraction, embeddings, and search capabilities.
Titan Text G1 - Express v1
High-performance text model supporting 100+ languages.
Versatile for content creation, classification, and open-ended Q&A.
Applicable in education and content marketing.
The model can process a maximum of 8K tokens at once. Tokens are units of text, and if your input text surpasses this limit, you may need to adjust or truncate it to fit within the model’s capacity.
Titan Text G1 - Lite v1
Cost-effective text generation focused on English language.
Efficient for summarization, copywriting in marketing, and corporate communications.
The model can process a maximum of 4K tokens at once. Tokens are units of text, and if your input text surpasses this limit, you may need to adjust or truncate it to fit within the model’s capacity.
Amazon Parameters
These parameters allow you to control the randomness, length, and stopping conditions of the text generated by the AI model based on your preferences and needs.
Randomness and Diversity
The Titan models support the following parameters to control randomness and diversity in the response.
Temperature: Use a lower value to decrease randomness in the response.
Top P: Use a lower value to ignore less probable options.
Length
The Titan models support the following parameters to control the length of the generated response.
Response length: Specify the maximum number of tokens in the generated response.
Stop Sequences: Specify a character sequence to indicate where the model should stop. Currently, you can only specify one of the following options:
|User:
Anthropic
Explore LLM for conversations, question answering, and workflow automation, grounded in research on training responsible AI systems.
Claude 2 v2
Creative content generation, coding support, multiple languages.
Versatile for creative dialogue, tech development, and educational content.
The model can process a maximum of 100K tokens at once. Tokens are units of text, and if your input text surpasses this limit, you may need to adjust or truncate it to fit within the model’s capacity.
Claude 2.1 v2.1
High-capacity text generation, multiple languages.
Comprehensive analysis, trend forecasting, document comparison.
The model can process a maximum of 200K tokens at once. Tokens are units of text, and if your input text surpasses this limit, you may need to adjust or truncate it to fit within the model’s capacity.
Claude 1.3 v1.3
Writing assistance, advisory capabilities, multiple languages.
Effective for document editing, coding, general advisory in diverse sectors.
The model can process a maximum of 100K tokens at once. Tokens are units of text, and if your input text surpasses this limit, you may need to adjust or truncate it to fit within the model’s capacity.
Claude Instant 1.2 v1.2
Rapid response generation, multiple languages.
Fast dialogue, summary, and text analysis, ideal for customer support and quick content creation.
The model can process a maximum of 100K tokens at once. Tokens are units of text, and if your input text surpasses this limit, you may need to adjust or truncate it to fit within the model’s capacity.
Anthropic Parameters
These parameters allow you to control the randomness, length, and stopping conditions of the text generated by the AI model based on your preferences and needs.
Randomness and Diversity
The Claude models support the following parameters to control randomness and diversity in the response.
Temperature: Controls the level of randomness in the response.
The default value is 0.5, ranging from 0 to 1.
Use lower values (closer to 0) for analytical or multiple-choice tasks and higher values (closer to 1) for creative and generative tasks.
Top P: Utilizes nucleus sampling, where the cumulative distribution over all token options is computed in decreasing probability order.
It is terminated once it reaches a specified probability determined by top_p.
It is recommended to adjust either temperature or top_p, but not both.
Interaction with K: If both Top P and Top K are enabled, P acts after K, meaning it filters probabilities after the Top K token choices have been determined.
Top K: Controls the number of options the model considers for each subsequent token during text generation. It limits the choices to the most probable K options, excluding less likely responses and prioritizing those with higher probabilities.
In other words, it narrows down the selection to focus on the top-ranked possibilities for more effective and targeted text generation.
Length
The Claude models support the following parameters to control the length of the generated response.
Maximum Length: Sets the maximum number of tokens to generate before stopping.
It’s advised to set a limit of 4,000 tokens for optimal performance. Anthropic Claude models may stop generating tokens before reaching this value, as each model has its own maximum limit for this parameter.
Stop Sequences: Sequences that prompt the model to stop generating text. Anthropic Claude models currently stop on “\n\nHuman:” and may incorporate more built-in stop sequences in the future.
You can use the stop_sequences inference parameter to include additional strings that signal the model to stop text generation.
Cohere
Benefit from foundational large language models tailored for enterprise applications.
Command v14.7
Develop advanced English text.
Enable dynamic chat experiences.
Support customer support interactions.
Facilitate the creation of marketing content.
The model can process a maximum of 4K tokens at once. Tokens are units of text, and if your input text surpasses this limit, you may need to adjust or truncate it to fit within the model’s capacity.
Command Light v14.7
Generate efficient English text.
Cost-effective for small-scale chat.
Suitable for content tasks.
Adaptable for business communications.
The model can process a maximum of 4K tokens at once. Tokens are units of text, and if your input text surpasses this limit, you may need to adjust or truncate it to fit within the model’s capacity.
Cohere Parameters
These parameters allow you to control the randomness, length, and stopping conditions of the text generated by the AI model based on your preferences and needs.
Randomness and Diversity
The Command models support the following parameters to control randomness and diversity in the response.
Temperature: Control the amount of randomness injected into the model’s response during text generation.
Default: 0.9
Minimum: 0
Maximum: 5
Setting temperature closer to 0 produces more focused and deterministic responses, suitable for analytical or multiple-choice tasks where precision is crucial.
Setting temperature closer to 1 increases randomness, making the responses more diverse and creative, suitable for tasks that benefit from imaginative and varied outputs.
P: Top P, it influences the probability distribution of token selection during text generation.
A lower value of P allows the model to focus on the most probable options, ignoring less likely ones. You can set P to 0 or 1.0 to disable this feature.
Interaction with K: If both P and K are enabled, P acts after K, meaning it filters probabilities after the Top K token choices have been determined.
K: Controls the number of options the model considers for each subsequent token during text generation. It limits the choices to the most probable K options, excluding less likely responses and prioritizing those with higher probabilities.
In other words, it narrows down the selection to focus on the top-ranked possibilities for more effective and targeted text generation.
Length
The Command models support the following parameters to control the length of the generated response.
Max Tokens: The maximum number of tokens to include in the generated response.
Stop Sequences: Set up to four sequences that tell the model when to stop generating. Once a stop sequence is encountered, the model stops generating further tokens, and the stop sequence is not included in the final text.
Examples of stop sequences:
If you set the stop sequence as “\n\n”, the model will stop generating tokens when it encounters two consecutive newline characters.
For a stop sequence like “STOP_GENERATION”, the model will halt generation upon encountering this specific string in the output.
Using ["#", “!END!”], the model will stop generating tokens when it encounters either the “#” symbol or the “!END!” string.
Return Likelihoods: specify whether and how the token likelihoods are returned with the model’s response. You can choose from the following options:
NONE: (Default) Don’t return any likelihoods, excluding this information from the response.
GENERATION: Only return likelihoods for tokens that are generated as part of the model’s response.
ALL: Return likelihoods for all tokens, including both generated tokens and any additional tokens processed during the generation.
Meta
Experience the power of large language models with Meta’s Llama, now accessible for individuals, creators, researchers, and businesses of all sizes to innovate responsibly.
Llama 2 Chat 70B v1
Optimized for large-scale language modeling in English.
Ideal for detailed text generation.
Well-suited for developing dialogue systems in customer service.
Suitable for creative industries.
The model can process a maximum of 4K tokens at once. Tokens are units of text, and if your input text surpasses this limit, you may need to adjust or truncate it to fit within the model’s capacity.
Llama 2 Chat 13B v1
Designed for dialogue systems and text generation in English.
Small-scale tasks like language translation.
Text classification.
Ideal for multilingual communication platforms.
The model can process a maximum of 4K tokens at once. Tokens are units of text, and if your input text surpasses this limit, you may need to adjust or truncate it to fit within the model’s capacity.
Meta Parameters
These parameters allow you to control the randomness, length, and stopping conditions of the text generated by the AI model based on your preferences and needs.
Randomness and Diversity
The Meta models support the following parameters to control randomness and diversity in the response.
Temperature: Control the randomness in the response generated by the Meta model.
To make the model’s responses less random, set the parameter closer to 0. The default value is 0.5, offering a balanced randomness level. You can adjust it from 0 to 1 for your desired level of unpredictability.
Top P: Set the
top_pparameter to a lower value to decrease reliance on less probable options.The default is 0.9, providing a balance. You can adjust it within the range (0 to 1) to control the model’s consideration of less likely choices.
Length
The Meta models support the following parameters to control the length of the generated response.
- Response length: Specify the maximum number of tokens in the generated response.
Prompt
A prompt is a concise instruction or query in natural language provided to the Bedrock Text processor to guide its actions or responses.
In the Prompts section, you have the flexibility to:
Choose Predefined Sample Prompts: Discover a set of ready-to-use sample prompts that can kickstart your interactions with the Bedrock Text processor.
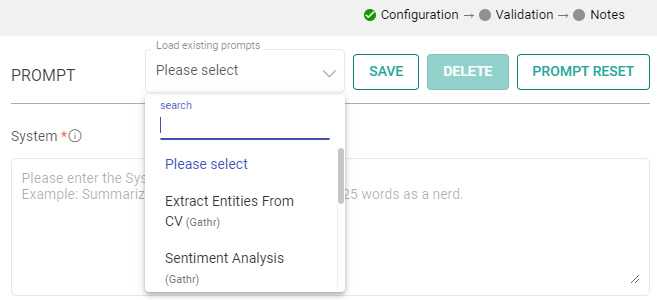
Configuration Options: Customize prompts to suit your specific needs.
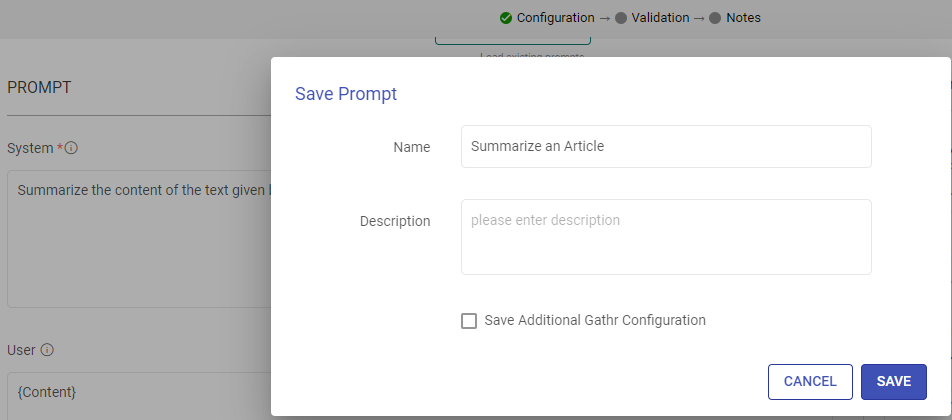
Save Prompts: Store your preferred prompts for future use.
Delete Prompts: Remove prompts that are no longer necessary.
Prompt Reset: To reset the prompt, clear the details in the prompt field, restoring it to its default state.
System
Provide high-level instructions and context for the chosen AI model, guiding its behavior and setting the overall tone or role it should play in generating responses.
Note: <|endoftext|> is a document separator that the model sees during training, so if a prompt is not specified, the model will generate a response from the beginning of a new document.
The placeholder {some_key} represents a variable that can be replaced with specific column data. You can map this key to a column in the next section using “EXTRACT INPUTS FROM PROMPT”.
Input
The placeholders {__} provided in the prompt can be mapped to columns to replace its value with the placeholder keys.
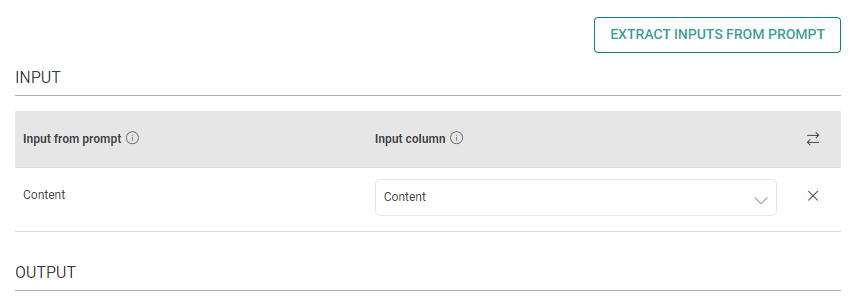
Input from prompt
All the placeholders {__} provided in the fields above are extracted here to map them with the column.
Input column
Select the column name to replace its value with the placeholder keys.
Output
The output can be configured to emit data received from input. This configuration includes utilizing Prompts, which can be interpreted as input columns via placeholders, and allows for emitting output either by specifying a column name or parsing it as JSON.
Process Response
Please provide the response format:
Assign to column:
Output Column as TEXT
Please type the column name for the data to be emitted.
Parse as JSON:
Json Key in Response
Add the JSON keys instructed to the model and map them with the corresponding output column names.
Output Column as JSON
Please type the column name for the data corresponding to the JSON keys instructed to the model.
RATE CONTROL
Choose how to utilize the AI model’s services:
Make Concurrent Requests with Token Limit: You can specify the number of simultaneous requests to be made to the AI model, and each request can use up to the number of tokens you provide.
This option is suitable for scenarios where you need larger text input for fewer simultaneous requests.
OR
Rate-Limited Requests: Alternatively, you can make a total of specified number of requests within a 60-second window.
This option is useful when you require a high volume of requests within a specified time frame, each potentially processing smaller amounts of text.
Enable retry requests
Enabling retry requests allows for automatic resubmission of failed or incomplete requests, enhancing data processing reliability.
No. of Retries
The number of times a request will be automatically retried if the response from AI model is not in JSON format or does not have all the entities.
When
Please select the criteria for retry. Select “Any output key is missing” if all keys are mandatory. Else, select the mandatory keys.
Include previous response
Please mark if a previous incorrect response should be added to the retry request messages prompt. Else, leave it unchecked.
Additional User Prompt
Please type prompt text to be considered while retrying the request.
If you have any feedback on Gathr documentation, please email us!