Vertex AI Text Processor (Beta)
Vertex AI offers access to Gemini models from Google. It is capable of understanding text, images, audio, and video inputs.
You can try sample prompts for extracting text from images, converting image text to JSON, analyzing speech files for summarization, transcription, Q&A, processing multiple types of input media at the same time, and many more tasks, all through intuitive and natural language instructions.
AI Models
Vertex AI processor gives you access to below AI models:
gemini-1.5-flash-001
A foundation model that performs well at a variety of multimodal tasks such as visual understanding, classification, summarization, and creating content from image, audio and video. It’s adept at processing visual and text inputs such as photographs, documents, infographics, and screenshots.
It is designed for high-volume, high-frequency tasks where cost and latency matter. On most common tasks, Flash achieves comparable quality to other Gemini Pro models at a significantly reduced cost. Flash is well-suited for on-demand content generation where speed and scale matter.
Use cases
Visual information seeking: Use external knowledge combined with information extracted from the input image or video to answer questions.
Object recognition: Answer questions related to fine-grained identification of the objects in images and videos.
Digital content understanding: Answer questions and extract information from visual content like infographics, charts, figures, tables, and web pages.
Structured content generation: Generate responses based on multimodal inputs in formats like HTML and JSON.
Captioning and description: Generate descriptions of images and videos with varying levels of detail.
Reasoning: Compositionally infer new information without memorization or retrieval.
Audio: Analyze speech files for summarization, transcription and Q&A.
Multimodal processing: Process multiple types of input media at the same time, such as video and audio input.
gemini-1.5-pro-001
Gemini 1.5 Pro is a foundation model that performs well at a variety of multimodal tasks such as visual understanding, classification, summarization, and creating content from image, audio and video. It’s adept at processing visual and text inputs such as photographs, documents, infographics, and screenshots.
Use cases
Visual information seeking: Use external knowledge combined with information extracted from the input image or video to answer questions.
Object recognition: Answer questions related to fine-grained identification of the objects in images and videos.
Digital content understanding: Answer questions and extract information from visual content like infographics, charts, figures, tables, and web pages.
Structured content generation: Generate responses based on multimodal inputs in formats like HTML and JSON.
Captioning and description: Generate descriptions of images and videos with varying levels of detail.
Reasoning: Compositionally infer new information without memorization or retrieval.
Audio: Analyze speech files for summarization, transcription and Q&A.
Multimodal processing: Process multiple types of input media at the same time, such as video and audio input.
Processor Configuration
Configure the processor parameters as explained below.
Connection Name
A connection name can be selected from the list if you have created and saved connection details for Vertex AI earlier. Or create one as explained in the topic - Vertex AI Connection →
Select Provider
Pick a provider to access foundation models (FMs) from AI companies. The provider parameters and FMs will be updated based on your selection.
Prompt
A prompt is a concise instruction or query in natural language provided to the Vertex AI processor to guide its actions or responses.
In the Prompts section, you have the flexibility to:
Choose Predefined Sample Prompts: Discover a set of ready-to-use sample prompts that can kickstart your interactions with the Vertex AI processor.
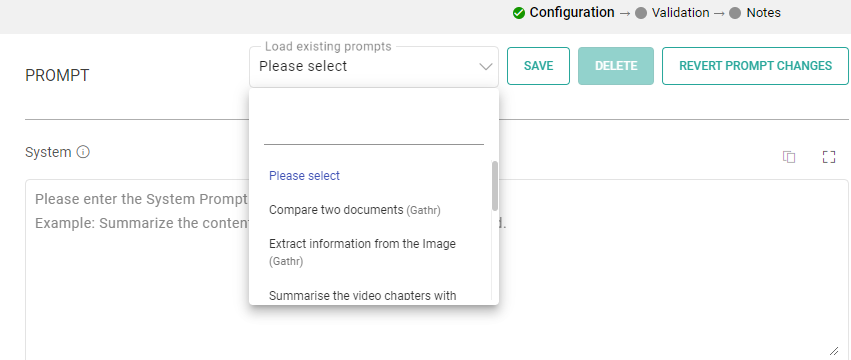
Configuration Options: Customize prompts to suit your specific needs.
Save Prompts: Store your preferred prompts for future use.
Delete Prompts: Remove prompts that are no longer necessary.
Prompt Reset: To reset the prompt, clear the details in the prompt field, restoring it to its default state.
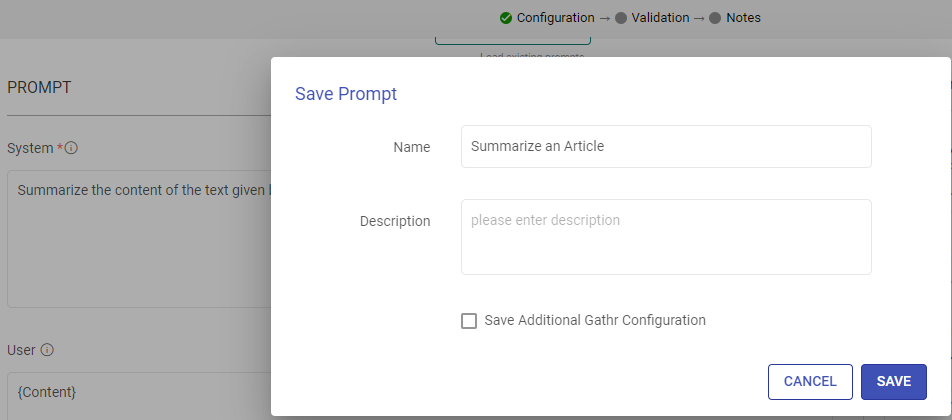
System
Provide high-level instructions and context for the AI model, guiding its behavior and setting the overall tone or role it should play in generating responses.
Note: <|endoftext|> is a document separator that the model sees during training, so if a prompt is not specified, the model will generate a response from the beginning of a new document.
The placeholder {some_key} represents a variable that can be replaced with specific column data. You can map this key to a column in the next section using “EXTRACT INPUTS FROM PROMPT”.
User
The user prompt is a specific instruction or question provided by the user to the AI model, directing it to perform a particular task or provide a response based on the user’s request.
Note: <|endoftext|> is a document separator that the model sees during training, so if a prompt is not specified, the model will generate a response from the beginning of a new document.
The placeholder {some_key} represents a variable that can be replaced with specific column data. You can map this key to a column in the next section using “EXTRACT INPUTS FROM PROMPT”.
Input
The placeholders {__} provided in the prompt can be mapped to columns to replace its value with the placeholder keys.
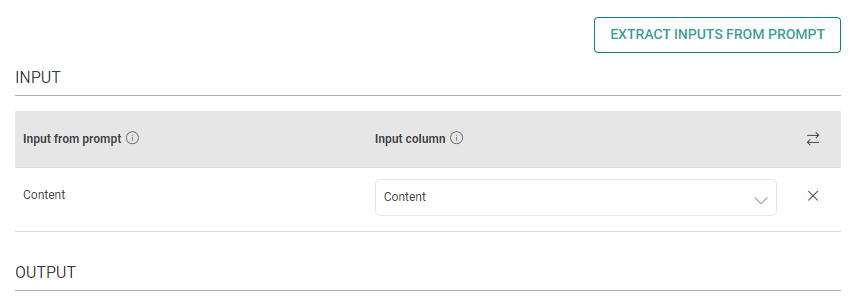
Input from prompt
All the placeholders {__} provided in the fields above are extracted here to map them with the column.
Input column
Select the column name to replace its value with the placeholder keys.
MULTIMODAL INPUT COLUMNS
Multimodal models can process a wide variety of inputs, including text, images, audio, and video as prompts.
Input column
Select the column that contains the multimodal input.
Type
Specifies the format of the input data. Choose either File URL option to read data from publicly accessible URLs specified in source column or base64 to read input data as a base64 encoded string.
MIME Type
The Media Type or MIME Type is a standard way of classifying file formats and types of data. It specifies the nature of the data contained in a resource or message. Supported MIME Types are:
application/pdf
audio/mpeg
audio/mp3
audio/wav
image/png
image/svg
image/jpeg
video/mov
video/mpeg
video/mpg
video/mp4
video/avi
video/wmv
video/mpegps
video/flv
Drop Column
Please tick the checkbox to remove the input column from output.
Output
The output can be configured to emit data received from input. This configuration includes utilizing Prompts, which can be interpreted as input columns via placeholders, and allows for emitting output either by specifying a column name or parsing it as JSON.
Process Response
Please provide the response format. Text/JSON
Json Key in Response
Add the JSON keys instructed to the model and map them with the corresponding output column names.
Output Column as JSON
Please type the column name for the data corresponding to the JSON keys instructed to the model.
Output Column as TEXT
Please type the column name for the data to be emitted.
RATE CONTROL
Choose how to utilize the Vertex AI’s services:
Make Concurrent Requests with Token Limit: You can specify the number of simultaneous requests to be made to Vertex AI, and each request can use up to the number of tokens you provide.
This option is suitable for scenarios where you need larger text input for fewer simultaneous requests.
OR
Rate-Limited Requests: Alternatively, you can make a total of specified number of requests within a 60-second window.
This option is useful when you require a high volume of requests within a specified time frame, each potentially processing smaller amounts of text.
Enable retry requests
Enabling retry requests allows for automatic resubmission of failed or incomplete requests, enhancing data processing reliability.
No. of Retries
The number of times a request will be automatically retried if the response from Vertex AI is not in JSON format or does not have all the entities.
When
Please select the criteria for retry. Select “Any output key is missing” if all keys are mandatory. Else, select the mandatory keys.
Include previous response
Please mark if a previous incorrect response should be added to the retry request messages prompt. Else, leave it unchecked.
Additional User Prompt
Please type prompt text to be considered while retrying the request.
Example: Please provide the response in JSON format.
Google Parameters
The parameters described below are configuration settings that govern the behavior and performance of Vertex AI models, influencing how they respond to prompts and generate outputs.
Choose a model
Select the model to determine the AI’s capabilities.
Region
Select one of the following geographical regions to specify the tuning job region.
europe-west3 (Frankfurt, Germany)
europe-west4 (Netherlands)
europe-west6 (Zürich, Switzerland)
europe-west8 (Milan, Italy)
europe-west9 (Paris, France)
europe-southwest1 (Madrid, Spain)
europe-central2 (Warsaw, Poland)
europe-north1 (Finland)
northamerica-northeast1 (Montréal, South Carolina)
southamerica-east1 (São Paulo, Brazil)
me-central1 (Doha, Qatar)
me-central2 (Dammam, Saudi Arabia)
me-west1 (Tel Aviv, Israel)
Maximum Number of Tokens
Maximum number of tokens that can be generated in the response. 200 tokens roughly equal 120-160 words. Adjust for shorter or longer responses.
Temperature
Control the randomness in responses. Lower values yield focused results. Higher values encourage creativity. Range: 0.0 - 2.0.
Top P
Limits token selection to the most probable ones until their combined probability reaches Top-P. Lower for precise responses, higher for diverse results.
Stop Sequence
Ends response generation when the model produces any specified sequence. Choosing appropriate stop sequences can help you avoid generating unnecessary tokens. Hit ↵ Enter to insert a newline character in a stop sequence. Hit the Tab key to finish inserting a stop sequence.
Safety Settings
Large language models (LLM) might generate output that you don’t expect, including text that’s offensive, insensitive, or factually incorrect. To maintain safety and prevent misuse, Gemini uses below safety filters to block prompts and responses that it determines to be potentially harmful.
HARM_CATEGORY_HATE_SPEECH
HARM_CATEGORY_DANGEROUS_CONTENT
HARM_CATEGORY_SEXUALLY_EXPLICIT
HARM_CATEGORY_HARASSMENT
You can select a threshold of each safety attribute to control how often prompts and responses are blocked.
Ground Model Responses
Connects model output to verifiable sources of information. This is useful in situations where accuracy and reliability are important.
Grounding Source
Grounding is the ability to connect model output to verifiable sources of information.
Choose between Google Search or Vertex AI Search for grounding model responses.
Google Search results for data that is publicly available and indexed.
Vertex AI Search results for your own text data using Vertex AI Search as a datastore.
Vertex AI Data Store Path: Specify the data store path when using Vertex AI Search as the grounding source.
If you have any feedback on Gathr documentation, please email us!