Data Science
At times you may need to derive insights from structured or unstructured data. With data science, you can interpret data for decision-making to provide meaningful information from volumes of data.
Data science is a field that comprises everything related to data cleansing, preparation, and analysis. It is the method used to extract insights and information from data.
Gathr incorporates data science techniques for deriving meaningful information from data. Using Gathr’s Machine Learning (ML) processors, one can train models and score models for streaming and batch data.
Making predictions on real-time data streams or a batch of data involves building an offline model and applying it to a stream. Models incorporate one or more machine learning algorithms trained using the collected data.
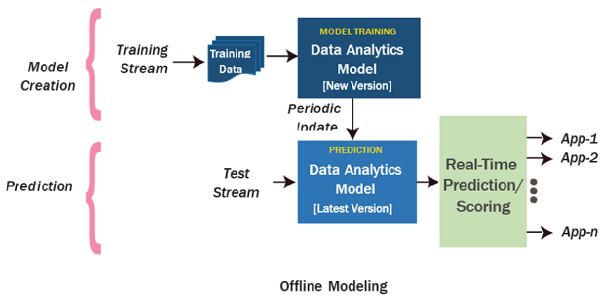
Machine Learning Processors
ML Analytics processors enable you to use predictive models built on top of the ML package.
ML provides a higher-level API built on data frames that helps you create and tune practical machine learning pipelines.
This topic is divided into the following sections:
Model Training
Model Scoring (Prediction)
Model Training
Models can be trained through Gathr with the help of ML processors. These models will be built on top of an ML package.
You can connect multiple models of different or same algorithms and train models on the same message in a single pipeline.
Intermediate columns calculated through transformations from one analytics processor will not be available on the next analytics processor if multiple analytics processors are trained in one pipeline.
Algorithms
In Gathr, there are eight algorithms under ML that support Model Training and Scoring.
Refer to each algorithm to know about configuration details.
The data flow for all these models includes a wizard-like flow. The same is shown in the figure below:

Configuration Section
Feature Selection
Pre-Processing
Post-Processing
Model Evaluation
Hyper Parameters
Model Scoring (Prediction)
Once the model is trained using training pipelines, it is registered to be used for scoring in any pipeline.
To use a trained model in a pipeline for scoring, drag and drop the analytics processor and change the mode of analytics processor from training to prediction.
| Field Name | Description |
|---|---|
| Operation | Type of operation to be performed by Operator. It could be Training or Prediction operation. |
| Algorithm Type | Select the Model Class, it could be Regression or Classification. |
| Model Name | Name of the model to be created when the training model is activated or the model name to be used for the prediction when the prediction mode is activated. |
| Detect Anomalies | Select to detect anomalies in the input data. |
| Anomaly Threshold | This is the threshold distance between a data point and a centroid. If any input data point’s distance to its nearest centroid exceeds this value then that data point will be considered as an anomaly. |
| Is Anomaly Variable | Input message field that will contain the result of anomaly test i.e. it will be true if a data record is an anomaly or false otherwise. |
Anomaly options are only available for K means, and Algorithm Type is available for Decision Tree, GBT, and Random Forest models.
Save the analytics processor and connect an emitter to verify the output.
Once the pipeline is saved, run it to predict the output.
If you have any feedback on Gathr documentation, please email us!