MLflow Inference Processor
The MLflow Inference Processor is a versatile and advanced operator, empowering users to tackle diverse data tasks effortlessly using simple, natural language instructions.
Choose from a variety of models registered on MLflow to classify data, extract specific information, summarize lengthy texts, analyze sentiment—tasks, and perform many more operations that traditionally require complex coding skills.
Configure the processor parameters as explained below.
Model Selection
Provide the details of the MLflow registered model to be used.
Show Model Info
See the stored model version details using this option.
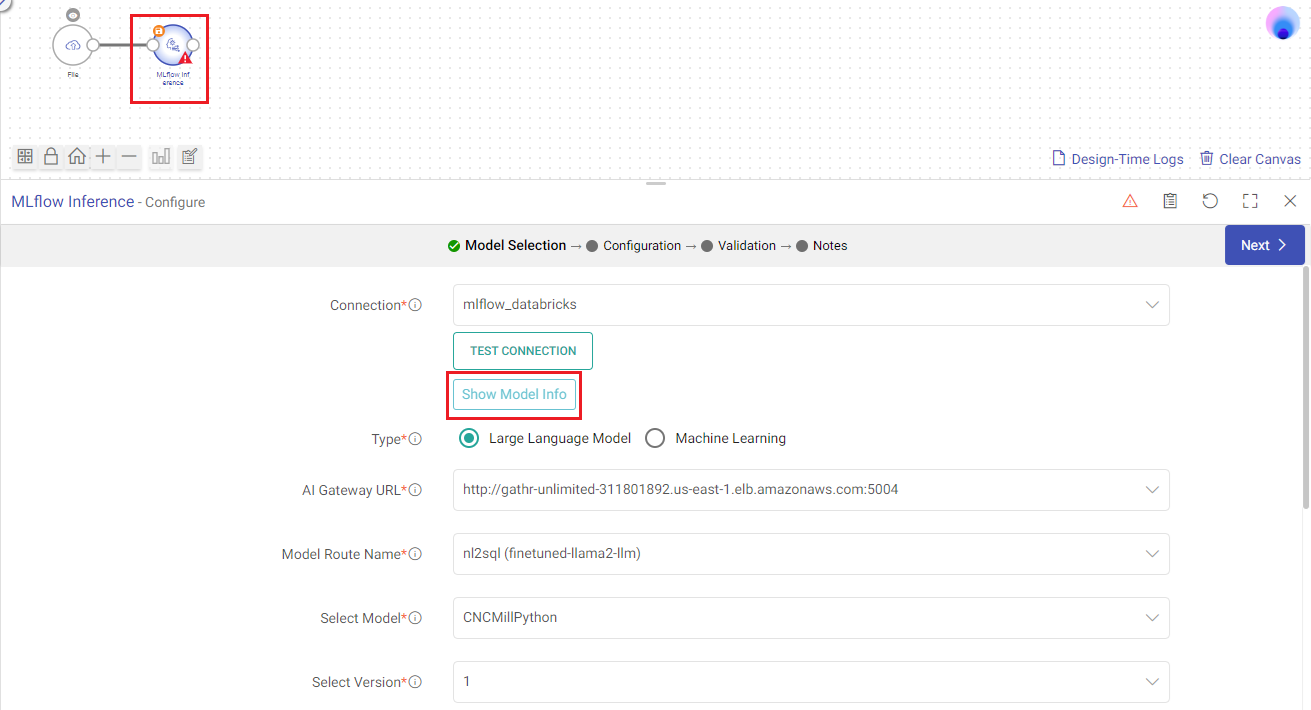
Populate the last stored details of a model version to be used in the processor.

Based on type of model for which you stored the details, all fields will be auto-populated.
You can also choose to manually update the configuration settings.
Connection
Select the MLflow connection that you created in Gathr.
Type
Type of the model to be used, Machine Learning (ML) or Large Language Model (LLM).
AI Gateway URL
Applicable for LLM models. The URL for the MLFlow AI gateway service.
Model Route Name
Applicable for LLM models. Followed by AI Gateway, the model route name directs the MLflow Inference processor’s inference requests to the appropriate service responsible for executing the model and generating predictions.
Model Serving URL
Applicable for ML models. The REST endpoint URL where the model is deployed.
Select Model
The MLflow model to be used. Model details will be shown below for reference.
Select Version
The model version to be used.
Model Configuration
Configure the processor parameters as explained below.
Prompt
A prompt is a concise instruction or query in natural language provided to the MLflow Inference processor to guide its actions or responses.
In the Prompts section, you have the flexibility to:
Load Existing Prompts: Discover a set of ready-to-use sample prompts that can kickstart your interactions with the MLflow Inference processor. Customize prompts to suit your specific needs.
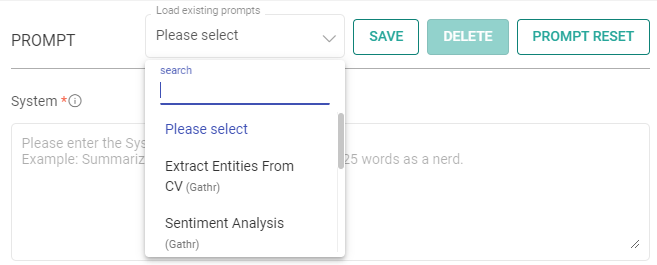
Save Prompts: Store your preferred prompts for future use.
Delete Prompts: Remove prompts that are no longer necessary.
Reset Prompt: To reset the prompt, clear the details in the prompt field, restoring it to its default state.
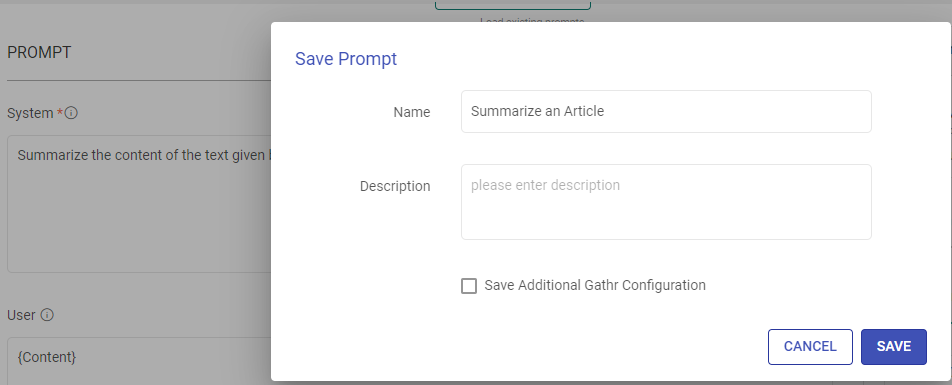
System
Provide high-level instructions and context for the MLflow model, guiding its behavior and setting the overall tone or role it should play in generating responses.
Note: <|endoftext|> is a document separator that the model sees during training, so if a prompt is not specified, the model will generate a response from the beginning of a new document.
The placeholder {some_key} represents a variable that can be replaced with specific column data. You can map this key to a column in the next section using “EXTRACT INPUTS FROM PROMPT”.
User
The user prompt is a specific instruction or question provided by the user to the MLflow model, directing it to perform a particular task or provide a response based on the user’s request.
Note: <|endoftext|> is a document separator that the model sees during training, so if a prompt is not specified, the model will generate a response from the beginning of a new document.
The placeholder {some_key} represents a variable that can be replaced with specific column data. You can map this key to a column in the next section using “EXTRACT INPUTS FROM PROMPT”.
Input
The placeholders {__} provided in the prompt can be mapped to columns to replace its value with the placeholder keys.
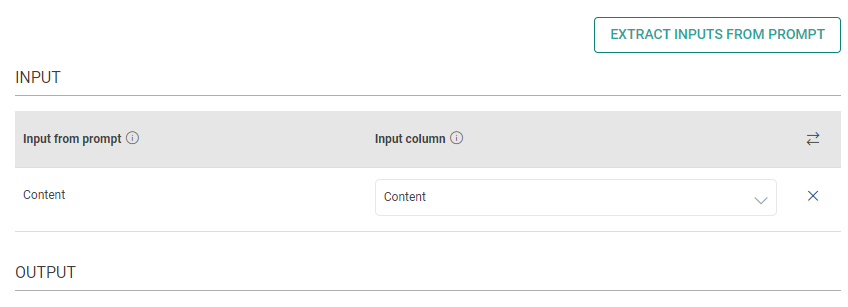
Input from prompt
All the placeholders {__} provided in the prompt fields above are extracted here to map them with the input column.
Input column
Select the column name to replace its value with the placeholder keys.
Output
The output column to emit data.
Model Parameters
The parameters described below are configuration settings that govern the behavior and performance of models, influencing how they respond to prompts and generate outputs.
Model
Name of the model will be shown.
Temperature
The sampling temperature to be used between 0 and 1. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic.
Max New Token
The maximum number of tokens to generate. The total length of input tokens and generated tokens is limited by the model’s context length.
Please note that it also affects the total tokens consumed per minute, potentially limiting the number of requests you can make. For example, if you set Max Tokens per request to 1500 and the model supports 90,000 tokens per minute, you can only make approximately 40 requests per minute.
Do Sample
Determines whether a model should use random sampling (enabled) or deterministic greedy decoding (disabled) when generating outputs.
Sampling introduces randomness for diverse outputs, while greedy decoding selects the most probable tokens for more predictable results.
Number of Beams
Controls the number of diverse sequences or “beams” generated during decoding. Increasing the number of beams can lead to a broader exploration of potential outputs, enhancing diversity but requiring more computation.
Repetition Penalty
Adjusts how much penalty a model assigns to repeated tokens in its generated sequences.
Higher penalties discourage repetitive outputs, promoting more varied and coherent text generation.
This parameter is useful in tasks like dialogue generation or summarization to improve the quality and diversity of generated content by reducing redundancy.
The repetition penalty ranges from 0 to 1:
A value of 0 indicates no penalty for repeated tokens. The model is free to repeat tokens as much as it finds appropriate.
A value of 1 implies a neutral penalty where the model neither penalizes nor rewards repeated tokens.
Values between 0 and 1 introduce a penalty for repeated tokens. The closer the value is to 0, the stronger the penalty for repetition. For example, a repetition penalty of 0.5 would moderately penalize repeated tokens, encouraging the model to diversify its outputs.
Adjusting the repetition penalty allows you to fine-tune how varied and natural the model’s responses should be, balancing between coherence and diversity in the generated text.
Validation
Validate the output according to your needs. Choose the rows you want to validate.
Top 3 Rows: Quickly validate the first three rows of the output. This is good for a rapid overview.
Custom Rows: For more precise validation, you can manually select specific rows to validate. Simply click on the rows you want to include.
Random Rows: Comprehensively validate random rows in the output.
Validation Process
Once you’ve made your selection, click the Validate button to initiate the validation process.
The processor will perform the validation according to your chosen rows.
Review and Confirm
Thoroughly review the validation results to confirm if they align with the desired outcome.
Adjust and Revalidate (If Necessary)
If you identify any errors or inconsistencies, you can go back to the MLflow Inference processor’s configuration section and make adjustments as needed.
Once you’re satisfied with the validation results, you can proceed to the next step and save the configurations.
Optionally add notes in the next section.
Click Done to save the configuration.
If you have any feedback on Gathr documentation, please email us!