Azure OpenAI Processor
The Azure OpenAI Processor is a versatile, cutting-edge solution that empowers users to perform a wide range of data-related tasks, all through intuitive and natural language instructions.
Whether you need classification, data extraction, summarization, sentiment analysis, or more, this processor makes it all possible, eliminating the need for complex coding.
With the power of Azure OpenAI, this processor can understand your instructions in plain, conversational language and execute them on your input data.
Unlock the potential of your data with the Azure OpenAI Processor.
Processor Configuration
Configure the processor parameters as explained below.
Connection Name
A connection name can be selected from the list if you have created and saved connection details for Azure OpenAI earlier. Or create one as explained in the topic - Azure OpenAI Connection →
Prompt
A prompt is a concise instruction or query in natural language provided to the Azure OpenAI processor to guide its actions or responses.
In the Prompts section, you have the flexibility to:
Choose Predefined Sample Prompts: Discover a set of ready-to-use sample prompts that can kickstart your interactions with the Azure OpenAI processor.
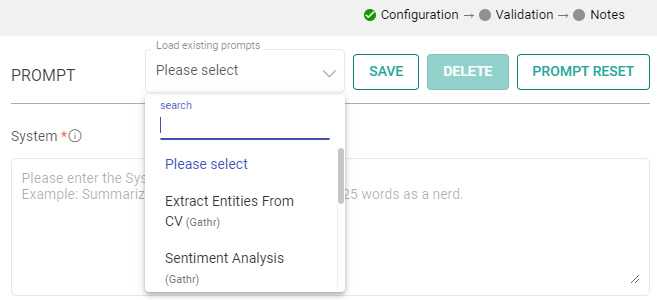
Configuration Options: Customize prompts to suit your specific needs.
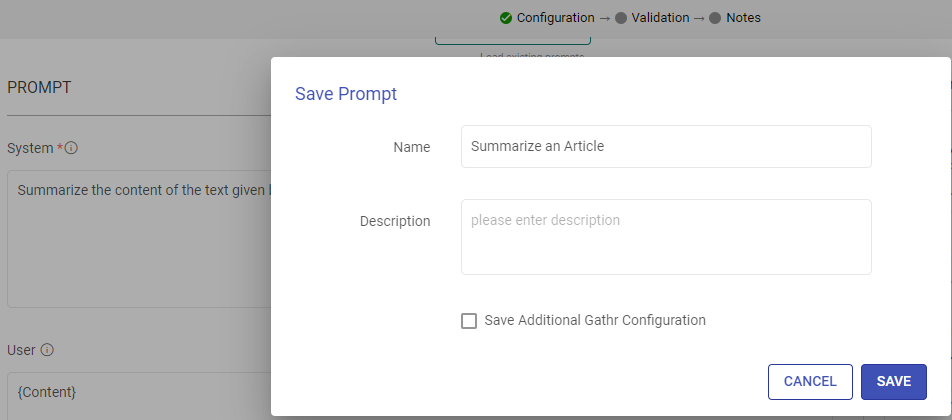
Save Prompts: Store your preferred prompts for future use.
Delete Prompts: Remove prompts that are no longer necessary.
Prompt Reset: To reset the prompt, clear the details in the prompt field, restoring it to its default state.
System
Provide high-level instructions and context for the AI model, guiding its behavior and setting the overall tone or role it should play in generating responses.
Note: <|endoftext|> is a document separator that the model sees during training, so if a prompt is not specified, the model will generate a response from the beginning of a new document.
The placeholder {some_key} represents a variable that can be replaced with specific column data. You can map this key to a column in the next section using “EXTRACT INPUTS FROM PROMPT”.
User
The user prompt is a specific instruction or question provided by the user to the AI model, directing it to perform a particular task or provide a response based on the user’s request.
Note: <|endoftext|> is a document separator that the model sees during training, so if a prompt is not specified, the model will generate a response from the beginning of a new document.
The placeholder {some_key} represents a variable that can be replaced with specific column data. You can map this key to a column in the next section using “EXTRACT INPUTS FROM PROMPT”.
Input
The placeholders {__} provided in the prompt can be mapped to columns to replace its value with the placeholder keys.
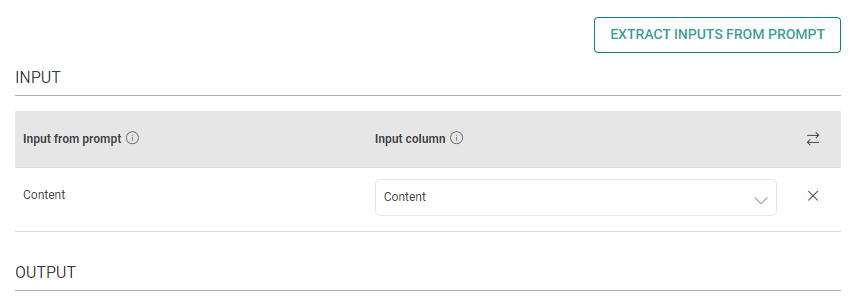
Input from prompt
All the placeholders {__} provided in the fields above are extracted here to map them with the column.
Input column
Select the column name to replace its value with the placeholder keys.
Output
The output can be configured to emit data received from input. This configuration includes utilizing Prompts, which can be interpreted as input columns via placeholders, and allows for emitting output either by specifying a column name or parsing it as JSON.
Process Response
Please provide the response format. Text/JSON
Json Key in Response
Add the JSON keys instructed to the model and map them with the corresponding output column names.
Output Column as JSON
Please type the column name for the data corresponding to the JSON keys instructed to the model.
Output Column as TEXT
Please type the column name for the data to be emitted.
Open AI Parameters
The parameters described below are configuration settings that govern the behavior and performance of Azure OpenAI models, influencing how they respond to prompts and generate outputs.
Deployment Name
Enter or select your Azure Cognitive Service deployment name. If you’ve configured the management API, deployment names and base models will be auto-listed; otherwise, enter them manually. Deployment means making your models or apps available on Azure OpenAI Service by setting up the hosting infrastructure.
Base Model
Choose your base model for deployment. If you’ve set up the management API, base models are auto-listed; otherwise, enter them manually. The base model is the foundation for your models or apps on Azure OpenAI Service.
Max Token
The maximum number of tokens to generate in the chat completion.
The total length of input tokens and generated tokens is limited by the model’s context length.
Please note that it also affects the total tokens consumed per minute, potentially limiting the number of requests you can make. For example, if you set Max Tokens per request to 1500 and the model supports 90,000 tokens per minute, you can only make approximately 40 requests per minute.
Temperature
The sampling temperature to be used between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic.
It is generally recommended to alter this or top_p but not both.
Advanced Configuration
Stop Sequence
Up to 4 sequences where the API will stop generating further tokens. The returned text will not contain the stop sequence.
Top P
An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So, 0.1 means only the tokens comprising the top 10% probability mass are considered.
It is generally recommended to alter this or temperature, but not both.
Frequency Penalty
Number between -2.0 and 2.0. Positive values penalize new tokens based on whether they appear in the text so far, increasing the model’s likelihood to talk about new topics.
Presence Penalty
Number between -2.0 and 2.0. Positive values penalize new tokens based on their existing frequency in the text so far, decreasing the model’s likelihood to repeat the same line verbatim.
RATE CONTROL
Choose how to utilize the Azure OpenAI’s services:
Make Concurrent Requests with Token Limit: You can specify the number of simultaneous requests to be made to Azure OpenAI, and each request can use up to the number of tokens you provide.
This option is suitable for scenarios where you need larger text input for fewer simultaneous requests.
OR
Rate-Limited Requests: Alternatively, you can make a total of specified number of requests within a 60-second window.
This option is useful when you require a high volume of requests within a specified time frame, each potentially processing smaller amounts of text.
Enable retry requests
Enabling retry requests allows for automatic resubmission of failed or incomplete requests, enhancing data processing reliability.
No. of Retries
The number of times a request will be automatically retried if the response from Azure OpenAI is not in JSON format or does not have all the entities.
When
Please select the criteria for retry. Select “Any output key is missing” if all keys are mandatory. Else, select the mandatory keys.
Include previous response
Please mark if a previous incorrect response should be added to the retry request messages prompt. Else, leave it unchecked.
Additional User Prompt
Please type prompt text to be considered while retrying the request.
If you have any feedback on Gathr documentation, please email us!