The objective of this topic is to assist the user to install Gathr on an Azure environment.
Hardware and Software Configurations
Create Azure VM, preferably on the same VNET and Subnet where the Azure Databricks cluster is running with the below minimal specification.
Optional [preferred during the installation. Otherwise, the required software packages and their dependency should be available on Azure VM].
Open the below ports in VM’s NSG:
CIDR range of user: This means that the customer needs to whitelist the IP ranges where the user is trying to access the Web UI of Gathr, RabbitMQ, and Elasticsearch.
CIDR range of Databricks Cluster: This means the customer needs to whitelist the IP ranges of the Databricks cluster on Azure VM.
A virtual machine with the following resources should be available to setup Gathr:
Below details are required to configure Azure Databricks with Gathr
- Azure Databricks instance URL
- Azure Databricks Authentication token
Gathr Installation specific prerequisites
- The SSH access should be available for Azure VM to Setup Gathr.
- The Linux SSH user used for Gathr installation should have the sudo privilege.
- Make sure the Gathr_Setup_bundle (tar.gz) and other artifacts should be downloaded from centralized location provided by the Gathr Support team and make it available on Azure VM.
- Valid Gathr license file should be available during the installation (provided by the Gathr Support team).
- Ensure the connectivity between Gathr VM, Azure Databricks cluster, and any external components (Hadoop, Kafka, Solr, etc.) if required.
The below specified software should be installed on Azure VM as part of the Gathr installation.
RabbitMQ, Elasticsearch components are optional; however, pipeline monitoring and error handling features won’t be provided in Gathr if these are not available.
Note: The Hadoop components (Kafka, HBase, Hive, etc.) are optional and can be installed and configured with Gathr depending upon the use case requirements.
To setup Gathr, you should have sufficient privileges to create and manage the resources (Resource Group, Virtual machines, Virtual Networks, Subnet, Network Security Group, Azure Databricks) in Azure.
Note: Hadoop components are optional; depending upon the requirements. You may need to install the Hadoop services (HDFS, Hive, Yarn, etc.) manually and update the configurations accordingly in Gathr.
Create Virtual Machine
- Type virtual machines in the search.
- Under Services, select Virtual machines.
- Select Create and then click Virtual machine on the Virtual machines page. The Create a virtual machine page opens.
- In the Basics tab, under Project details, make sure that the correct subscription is selected and then create a new resource group. Type myResourceGroup for the name.*.
- Under Instance details, type tomcatVM for the Virtual machine name, and choose CentOS Gen1 for your Image. Leave the other defaults. The default size and pricing are only shown as an example. Size availability and pricing are dependent on your region and subscription.
- Under Administrator account, select Password.
- Under Inbound port rules > Public inbound ports, choose to Allow selected ports and then select SSH (22) and HTTP (80) from the drop-down.
- Leave the remaining defaults and then select the Review + create button at the bottom of the page.
- On the Create a virtual machine page, you can see the details about the VM you are about to create. When you are ready, select Create.
- When the deployment is finished, select Go to resource.
- On the page for your new VM, select the public IP address and copy it to your clipboard.
Below are the ports that need to be opened in VM Security Group
This section describes the steps required to install the prerequisite software on Virtual Machine launched on Cloud.
ssh into the Gathr VM to continue with the following steps
- Install Java 8
This is an optional component. However, it is important as it is used for pipeline error handling in Gathr.
Install this package before installing RMQ:
Download the package: wget https://www.rabbitmq.com/releases/rabbitmq-server/v3.6.10/rabbitmq-server-3.6.10-1.el7.noarch.rpm rpm --import https://www.rabbitmq.com/rabbitmq-release-signing-key.asc
Start using this command:
Enable it with this command:
To check the status, use this command:
Enable the plugins with this command:
To create a test user:
Install Zookeeper 3.5.7 as follows:
Copy the zookeeper tar file either from sax_bundle.
Extract it:
Set the IP and Port in
Start the zookeeper:
Install Postgres 10 as follows:
1. Install Postgres repo as a root user into the system:
2. Install Postgresql10:
3. Initialize PGDATA:
4. Login into Postgres: su - postgres -c "psql"
5. Change the Postgres password
Login as a Postgres user: su – postgres.
Add the IPs in IP4 to allow the permission:
Edit the postgresql.conf and replace listen_address from localhost to *.
Restart the postgres: systemctl restart postgresql-10.service
This is an optional component; however, it is important as it will be used for monitoring Gathr pipelines.
Install Elasticsearch 6.4.1 as follows
- Copy Elasticsearch from sax_bundle.
- Open /elasticsearch-6.4.1/conf/elasticsearch.yaml and make these changes:
1. max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
2. max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
For 1. Add this line in /etc/security/limits.conf
Note: Sax is the user from which you are starting elasticsearch.
For 2. Run this command: sudo sysctl -w vm.max_map_count=262144
Start Elasticsearch in the background: nohup ./elasticsearch &
Install and run in embedded mode. Copy the Gathr tar file to the Virtual Machine. Extract the tar.
Run this command to start StreamAnalytix in embedded mode:
Note: Logs are located in <GathrInstallationDir>/logs and <GathrInstallationDir>/server/tomcat/logs directories.
You can check the log files in these directories for any issues during the installation process.
To open Gathr use the below command:
Accept the End User License Agreement and hit the Next button.
The Upload License page opens.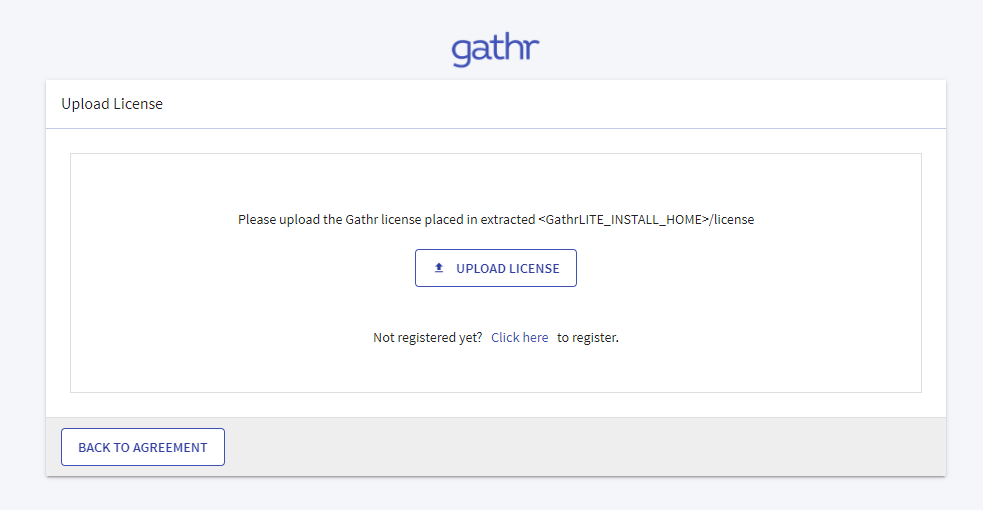
Upload the license and confirm.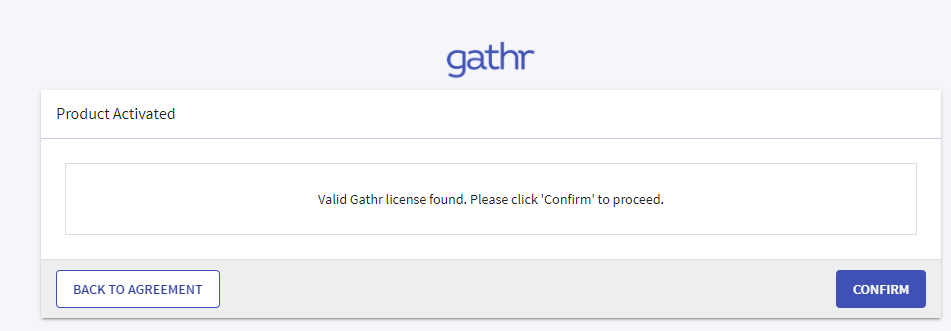
Note: Now, the user will need to switch Gathr from embedded to cluster mode.
Follow the sections given below to switch Gathr from embedded to cluster mode:
Login to Gathr using the default username & password.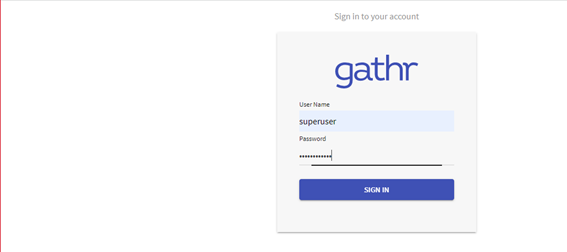
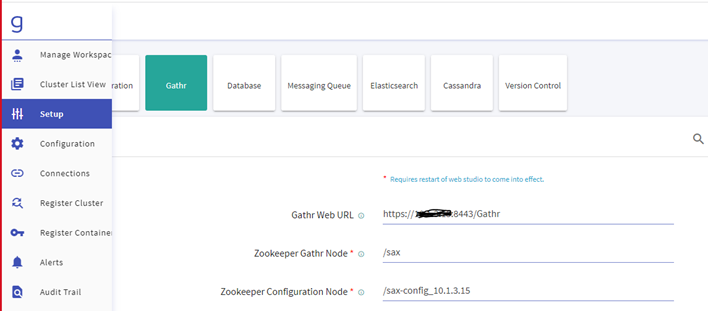
Navigate to the Setup >> Gathr and update the below details:
- Zookeeper Configuration Node
Navigate to the Setup >> Database and update the below details.
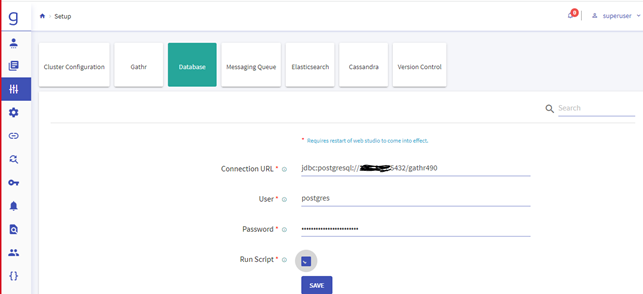
Note: Check the Run Script and click on Save. It will execute the DDL & DML in Gathr Metastore.
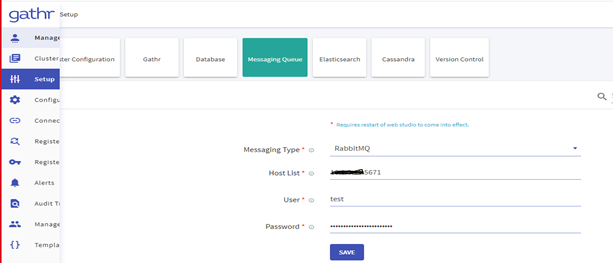
Navigate to the Setup >> Messaging Queue and update the below details:
Navigate to the Setup >> Elasticsearch and update the below details:
- Elasticsearch Connection URL
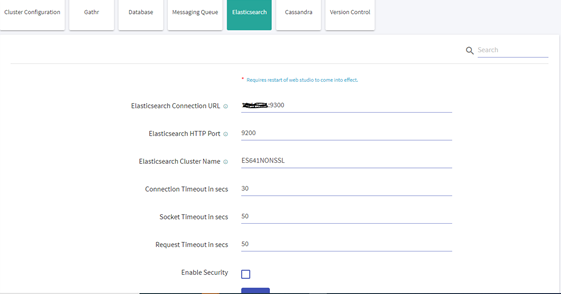
After updating the details, restart Gathr with -config.reload=true.
Copy Cloud Vendor-specific war
Copy Cloud Vendor-specific war file into tomcat
For Azure-Databricks: cp <Gathrinstallationlocation>/lib/clusterMediator.war <Gathrinstallationlocation>/server/tomcat/webapps/
The war will get extracted in server/tomcat/webapps. Now stop tomcat and configure application files.
For Azure-Databricks:
Configure Cloud Vendor-specific details in YAML
Configure Databricks details in yaml File: (<Gathrinstallationlocation>/Gathr /conf/yaml/env-config.yaml) dbfs.jar.uploadPath: "/sax-databricks-jars " mediator.address: "http://<GathrPrivateIP>:8090/cluster-mediator/"
Copy jar & init-scripts on DBFS
Restart in Cluster Mode and upload license
In case there are any updates to be done in configurations, you can restart Gathr by providing the below commands
1. Stop/Kill the Bootstrap Process.
2. Delete Gathr installation directory and its dependencies (like RMQ, ZK etc)