ML Models
ML Analytics processor enables you to use predictive models built on top of ML package.
ML provides higher-level API built on top of data frames that helps you to create and tune practical machine learning pipelines.
The documentation of ML Models is divided in the following section:
Training
Prediction (Model Scoring)
Model Training
Models can be trained through Gathr with the help of ML processors. These models will be built on top of an ML package.
Model Training can only be performed on Batch Data.
You can connect multiple models of different or same algorithm and train model on the same message in a single pipeline.
Algorithms
There are eight algorithms under ML that supports Model Training and Scoring:
The data flow for all these models include a wizard-like flow, which is shown in the figure below:

Isotonic Regression
Isotonic Regression belongs to the family of Regression algorithms. It gives an approximate series of one-dimensional observations with a non-decreasing function. Isotonic Regression Analytics processor is used to analyze data using ML Isotonic Regression Model.
To use an Isotonic Regression Model in Data Pipeline, drag and drop the model component to the pipeline canvas and right click on it to configure.
The Configuration window of every ML model is same.
After Configuration tab comes, Feature Selection tab. (which is also same for all the models except K Means).
Once Feature Selection is done, perform Pre-Processing on the data before feeding it to the Model. The configuration settings are same for all the ML models.
Then configure the Model using Model Configuration. Following tabs are generated for this Model:
| Field | Description |
|---|---|
| Label Column | Column name which will be treated as label column while training a model. |
| Feature Column | Column name which will be treated as feature column while training a model. |
| Isotonic | Specifies whether Isotonic is True or False When selected True,isotonic regression is isotonic (monotonically increasing) When selected False, isotonic regression is antitonic (monotonically decreasing). |
After Model Configuration, Post-Processing is done, Model Evaluation can be performed.
Then, apply the Hyper Parameters on the model to enable tuning your configuration; after which you can simply add notes and save the Configuration.
Linear Regression
Regression is an approach for modeling the relationship between a scalar dependent variable and one or more explanatory variables (or independent variables).
Regression Analytics processor is used to analyze data using ML LinearRegressionModel.
To use a Linear Regression Model in Data Pipeline, drag and drop the model component to the pipeline canvas and right click on it to configure.
The Configuration window of every ML model is same.
After Configuration tab comes, Feature Selection tab. (which is also same for all the models except K Means).
Once Feature Selection is done, perform Pre-Processing on the data before feeding it to the Model. The configuration settings are same for all the ML models.
Then configure the Model using Model Configuration. Following tabs are generated for this Model:
| Field | Description |
|---|---|
| Label Column | Column name which will be treated as label column while training a model. |
| Feature Column | Column name which will be treated as feature column while training a model. |
| Prediction Column | Select the columns to be predicted. |
| Num Iterations | Number of iterations of gradient descent to run per update. |
| ElasticNet Parameter | Sets the ElasticNet mixing parameter for the model. For alpha = 0, the penalty is an L2 penalty. For alpha = 1, it is an L1 penalty. For alpha (0, 1), the penalty is a combination of L1 and L2. Default is 0.0, which is an L2 penalty. |
| Regularization Parameter | Regularization parameter for model training. |
After Model Configuration, Post-Processing is done, Model Evaluation can be performed.
Apply the Hyper Parameters on the model to enable tuning your configuration; after which you can simply add notes and save the Configuration.
Decision Tree
Description
Decision trees and their ensembles are popular methods for the machine learning tasks of classification and regression. Decision trees algorithms are easy to interpret, they handle categorical features, extend to the multi-class classification setting, do not require feature scaling, and are able to capture non-linearity and feature interactions.
Decision Tree Analytics processor is used to analyze data using ML’s DecisionTreeClassificationModel and DecisionTreeRegressionModel.
To use a Decision Tree Model in Data Pipeline, drag and drop the model component to the pipeline canvas and right click on it to configure:
The Configuration window of every ML model is same.
After Configuration tab comes, Feature Selection tab. (which is also same for all the models except K Means).
Once Feature Selection is done, perform Pre-Processing on the data before feeding it to the Model. The configuration settings are same for all the ML models.
Then configure the Model using Model Configuration. Following tabs are generated for this Model:
| Field | Description |
|---|---|
| Label Column | Column name that will be treated as label column while training a model. |
| Probability Column | Column name that holds the value of probabilities of predicted output. |
| Prediction Column | Select the columns to be predicted. |
| Feature Column | Column name which will be treated as feature column while training a model. |
| Max Bins | Number of bins used when discretizing continuous features. |
| Max Depth | Maximum depth of the tree that needs to be trained. This should be chosen carefully as it acts as a stopping criteria for model training. |
| Impurity | Parameter which decides the splitting criteria over each node. Available options are Gini Impurity and Entropy for classification and Variance for Regression problems. |
| Minimum Information Gain | Specifies the splitting criteria over each node. Calculated on the basis of Impurity parameter.** |
| Seed | Number used to produce a random number sequence that makes the result of algorithm reproducible. Specify the value of seed parameter that will be used for model training. |
| Thresholds | Threshold parameter for the class range. Number of thresholds should be equal to Number of Output Classes. Mention only in case of Classification problems. |
After Model Configuration, Post-Processing is done, Model Evaluation can be performed.
Apply the Hyper Parameters on the model to enable tuning your configuration; after which you can simply add notes and save the Configuration.
View Model
Decision Tree model support visualization of trained models. View Model feature is available in case of Prediction pipeline.
The trained tree model will be visualized as below:
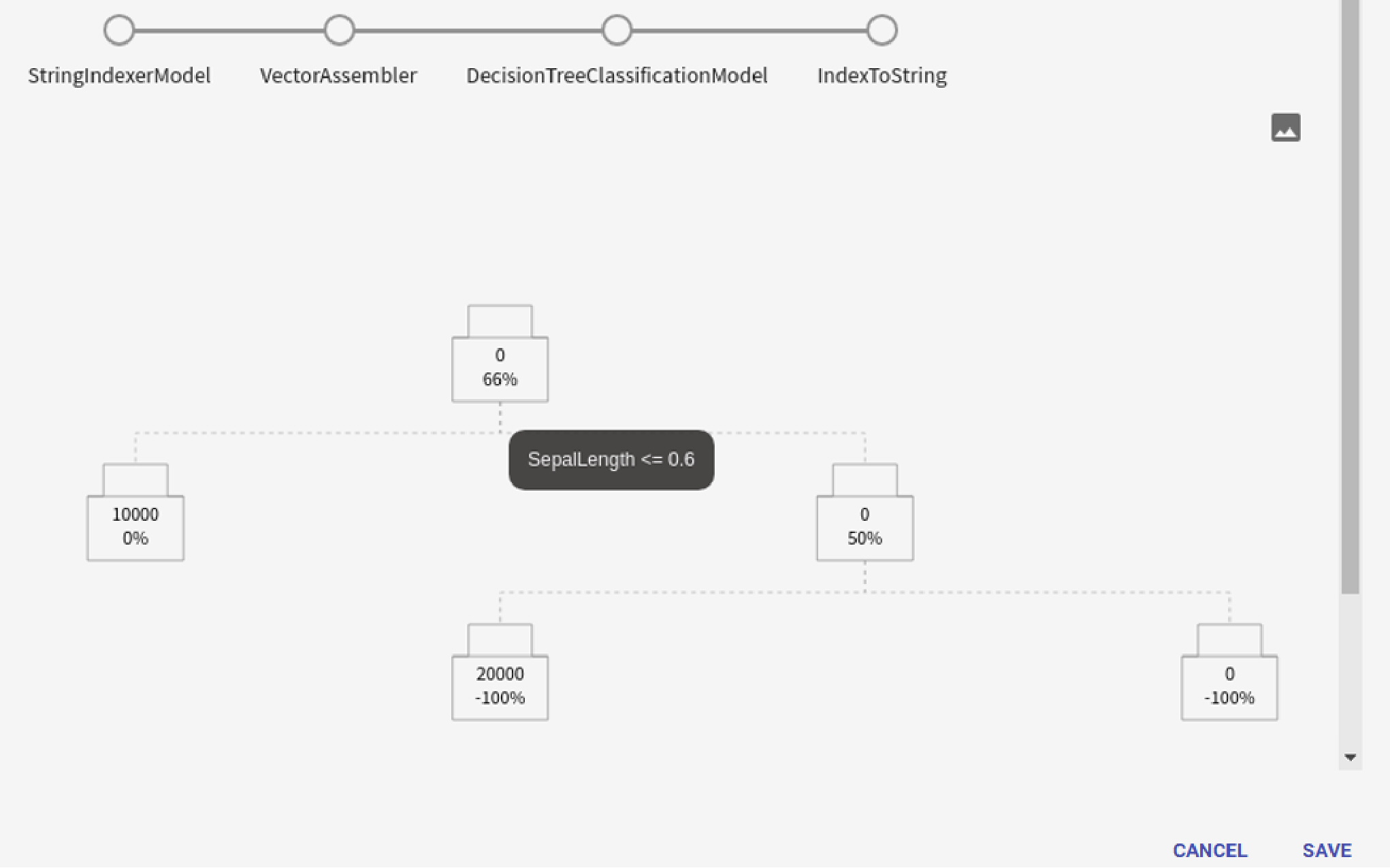
Gradient Boosted Tree
Gradient-Boosted Trees (GBTs) are ensembles of decision trees. GBTs can be used for binary classification and for regression, using both continuous and categorical features.
Gradient-Boosted Trees Analytics processor is used to analyze data using ML’s GBTClassificationModel and GBTRegressionModel.
To use a GBT Model in Data Pipeline, drag and drop the model component to the pipeline canvas and right click on it to configure.
The Configuration window of every ML model is same.
After Configuration tab comes, Feature Selection tab. (which is also same for all the models except K Means).
Once Feature Selection is done, you will have to perform Pre-Processing on the data before feeding it to the Model. The configuration settings are same for all the ML models.
Then configure the Model using Model Configuration. Following tabs are generated for this Model:
| Field | Description |
|---|---|
| Label Column | Column name that will be treated as label column while training a model. |
| Feature Column | Column name which will be treated as feature column while training a model. |
| Probability Column | Column name that holds the value of probabilities of predicted output. |
| Max Bins | Specify the value of max bins parameter for model training. |
| Max Depth | Specify the maximum depth of the tree that needs to be trained. This should be chosen carefully as it acts as a stopping criteria for model training. |
| Impurity | Parameter with the help of which split criteria is decided over each node. Available options are Gini Impurity and Entropy for classification problems and Variance for regression problems. |
| Minimum Information Gain | Calculated on the basis of Impurity parameter. Specifies actually the splitting criteria over each node. Information gained using any feature column over a particular node should be more than this parameter value, so that tree can be split** on the basis of that feature on that node. |
| Seed | Specify seed parameter value. This value will be used for model training. |
| Loss Type | Loss function which GBT tries to minimize. Supported options are “squared” (L2) and “absolute” (L1) for regression problems and logistic for classification problems. |
| Max Iterations | Number of Iterations for building ensemble of trees. Number of Output trees is equal to the max iterations specified. This acts as one of the stopping criteria for model training. |
| subSamplingRate | Specifies the size of the dataset used for training each tree in the forest, as a fraction of the size of the original dataset. The default (1.0) is recommended, but decreasing this fraction can speed up training. |
| Step Size | Defines the learning rate. This determines the impact of each tree model on the outcome. GBT works by starting with an initial estimate that is updated using the output of each tree. The learning parameter controls the magnitude of this change in the estimates. Lower values are generally preferred as they make the model robust to the specific characteristics of tree and thus allowing it to generalize well. Lower values would require higher number of trees to model all the records and will be computationally expensive. |
After Model Configuration, Post-Processing is done, Model Evaluation can be performed.
Apply the Hyper Parameters on the model to enable tuning your configuration; after which you can simply add notes and save the Configuration.
Random Forest Tree
Random forests are ensembles of decision trees. Random forests combine many decision trees to reduce the risk of over fitting. Random forests can be used for binary and multi-class classification and for regression, using both continuous and categorical features.
Random Forest Tree Analytics processor is used to analyze data using ML’s RandomForestClassificationModel and RandomForestRegressionModel.
To use a Random Forest Tress Regression Model in Data Pipeline, drag and drop the model component to the pipeline canvas and right click on it to configure.
The Configuration window of every ML model is same.
After Configuration tab comes, Feature Selection tab. (which is also same for all the models except K-Means).
Once Feature Selection is done, perform Pre-Processing on the data before feeding it to the Model. The configuration settings are same for all the ML models.
Then configure the Model using Model Configuration. Following tabs are generated for this Model:
| Field | Description |
|---|---|
| Label Column | Column name that will be treated as label column while training a model. |
| Probability Column | Column name that holds the value of probabilities of predicted output. |
| Feature Column | Column name which will be treated as feature column while training a model. |
| Max Bins | Specify the value of max Bins parameter for model training. |
| Max Depth | Specify the depth of the tree that needs to be trained. This should be chosen carefully as it acts as a stopping criteria for model training. |
| Impurity | Parameter that decides the splitting criteria over each node. Available options are Gini Impurity and Entropy for classification and Variance for regression problems. |
| Minimum Information Gain | Calculated based on Impurity parameter. Specifies actually the splitting criteria over each node. Information gained using any feature column over a particular node should be more than this parameter value, so that tree can be split** based on that feature on that node. |
| Seed | Number used to produce a random number sequence that makes the result of algorithm reproducible. Specify the value of seed parameter that will be used for model training. |
| Thresholds | Specify the threshold parameter for class range. Number of thresholds should be equal to number of output classes. Required only in case of Classification problems |
| Number of Trees | Number of trees in the forest. Increasing the number of trees will decrease the variance in predictions, improving the model’s test-time accuracy. Training time increases roughly linearly in the number of trees. |
| Feature Subset Strategy | Number of features to use as candidates for splitting at each tree node. The number is specified as a fraction or function of the total number of features. Decreasing this number will speed up training, but can sometimes impact performance if too low. |
| Sub Sampling Rate | Size of the dataset used for training each tree in the forest, as a fraction of the size of the original dataset. The default (1.0) is recommended, but decreasing this fraction can speed up training. |
After Model Configuration, Post-Processing is done, Model Evaluation can be performed.
Apply the Hyper Parameters on the model to enable tuning your configuration; after which you can simply add notes and save the Configuration.
Logistic Regression
Logistic regression is a popular method to predict a categorical response. A special case of generalized linear models predicts the probability of the outcomes. It can be used for both binary and multi-class classification problems.
Logistic Regression Analytics processor is used to analyze data using ML’s LogisticRegressionModel.
To us e a Logistic Regression Model in Data Pipeline, drag and drop the model component to the pipeline canvas and right-click on it to configure.
The Configuration window of every ML model is same.
After Configuration tab comes, Feature Selection tab. (which is also same for all the models except K-Means).
Once Feature Selection is done, perform Pre-Processing on the Model. The configuration settings are same for all the ML models.
Then configure the Model using Model Configuration. Following tabs are generated for this Model:
| Field | Description |
|---|---|
| Label Column | Column name that will be treated as Label column while training a model. |
| Probability Column | Column name that holds the value of probabilities of predicted output. |
| Feature Column | Column name which will be treated as feature column while training a model. |
| Thresholds | Specify the threshold parameter for class range. Number of thresholds should be equal to Number of Output Classes. |
| ElasticNet Param | Specify the value for ElasticNet Parameter for model training |
| Regularization Parameter | Specify the value for Regularization Parameter for model training |
| Max Iterations | Number of Iterations for building ensemble of trees. Number of Output trees is equal to the max iterations specified. This acts as one of the stopping criteria for model training. |
| Fit Intercept | Whether to fit an intercept term or not. |
After Model Configuration, Post-Processing is done, Model Evaluation can be performed.
Apply the Hyper Parameters on the model to enable tuning your configuration; after which you can simply add notes and save the Configuration.
Naive Bayes
Naive Bayes are a family of simple probabilistic classifiers based on applying Bayes’ theorem with strong (naive) independence assumptions between the features. Currently, it supports both multinomial Naive Bayes and Bernoulli Naive Bayes.
Naive Bayes Analytics processor is used to analyze data using ML’s NaiveBayesModel.
To use a Naïve Bayes Model in Data Pipeline, drag and drop the model component to the pipeline canvas and right-click on it to configure.
The Configuration window of every ML model is same.
After Configuration tab comes, Feature Selection tab. (which is also same for all the models except K Means).
Once Feature Selection is done, perform Pre-Processing on the data before feeding it to the Model. The configuration settings are same for all the ML models.
Then configure the Model using Model Configuration. Following tabs are generated for this Model:
| Field | Description |
|---|---|
| Label Column | Column name which will be treated as label column while training a model. |
| Probability Column | Column name which holds the probability value of the predicted output. |
| Feature Column | Column name which will be treated as feature column while training a model. |
| Model Type | Model Type for Naïve Bayes Classifier default is multinomial. Other model type supported is Bernoulli |
| Thresholds | Specify the threshold parameter for class range. Number of thresholds should be equal to Number of Output Classes. |
| Max Iterations | Number of Iterations for building ensemble of trees. Number of Output trees is equal to the max iterations specified. This acts as one of the stopping criteria for model training |
After Model Configuration, Post-Processing is done, Model Evaluation can be performed.
Apply the Hyper Parameters on the model to enable tuning your configuration; after which you can simply add notes and save the Configuration.
K-Means
K-Means is one of the most commonly used clustering algorithms that clusters the data points into a predefined number of clusters. K-Means Analytics processor is used to analyze data using ML’s K-means Model.
To use a K-Means Model in Data Pipeline, drag and drop the model component to the pipeline and right click on it to configure.
The Configuration window of every ML model is same.
After Configuration tab comes, Feature Selection tab. (which is also same for all the models except K Means).
Once Feature Selection is done, perform Pre-Processing on the data before feeding it to the Model. The configuration settings are same for all the ML models.
Then configure the Model using Model Configuration. Following tabs are generated for this Model:
| Field | Description |
|---|---|
| Max Iterations | Number of Iterations for building ensemble of trees. Number of Output trees are equal to the max iterations specified. This acts as one of the stopping criteria for model training. |
| Init Step | Parameter for the number of steps for the k-means |
| Feature Column | Column name which will be treated as feature column while training a model. |
| Seed | Specify seed parameter value. This value will be used for model training. |
| Tol | Set the convergence tolerance of iterations. Smaller value leads to higher accuracy with the cost of more iterations. |
| Number of Clusters | Sets the number of clusters. Must be > 1. |
| Init Mode | Parameter for the initialization algorithm. This can be either “random” to choose random points as initial cluster centers, or “k-means |
Configuration Section
The configuration page is common for all the ML Models except Tree based, Naive Bayes and Logistic Regression models. For rest of the models, following are the properties with screenshot:
| Field | Description |
|---|---|
| Operation | Type of operation to be performed by Analytics processor: Training: Select the option training, if you want to train new models. Prediction: Select the option prediction, if you want to give predictions over existing model. |
| Message Name | The name for the message configuration which acts as a metadata for the actual data. |
| Model Name | Name of the model to be used in the data pipeline. |
| Description | Summary or a brief description of the model. |
| Tags | Tags to be associated with the model. |
| Version Comments | A note about the model version. |
| Algorithm Type | Specifies whether the current algorithm is used for solving a classification problem or regression. Select the required algorithm from the drop-down list. |
| Classification Type | Type of Classification- Binary or Multiclass. |
| Save Model On | Enables to save model on HDFS or Gathr database. When selected HDFS, specify HDFS connection and path. When selected Gathr database, model will be saved to database. |
Feature Selection
For using analytics processor in both training and prediction mode, you have to explicitly specify Input Labels and Variables such as Continuous, Categorical and Text.
| Field | Description |
|---|---|
| Input Label | Input Label signifies the incoming message field, which will be considered as a label field for model training. |
| Features | User can provide all the continuous, categorical and text variables within the features field. |
| Drop Null Records | All the null records within the selected columns will get dropped here. |
Pre-Processing
In Pre-Processing, the data is transformed or consolidated so that the resulting mining process is more efficient, and the patterns found are easier to understand.
Once features are selected on Features selection tab, you can apply various transformations using Pre-Processing tab.
All ML models require feature column to be Vector Data type. For transforming raw input fields into type Vector, use Pre-Processing transformations.
Following are the descriptions of all the transformations/algorithms supported by Gathr over various analytics processor.
Binarizer
Binarizer thresholds numerical features to binary (0/1) features. Feature values greater than the threshold are binarized to 1.0; values equal to or less than the threshold are binarized to 0.0.
Enter values in the following parameters:
| Field | Description |
|---|---|
| Input Columns | Input column name over which Binarizer transformation is to be applied. To apply algorithm on multiple columns, apply Vector Assembler transformation before the algorithm. |
| Output Column | Name of the output column which will contain the transformed values after Binarizer transformation is applied. |
| Threshold | Threshold value to be used for binarization. Features greater than the threshold, will be binarized to 1.0. The features equal to or less than the threshold, will be binarized to 0.0. Default: 0.0 |
| Output Size Hint | Mention the size of the output Vector which will be generated after transformation is applied |
| Output Size Handle Invalid | Parameter for handling invalid vectors. Invalid vectors include nulls and vectors with the wrong size. The options are “skip” (filter out rows with invalid vectors), “error” (throw an error) and “optimistic” (do not check the vector size, and keep all rows). Default is “error” |
Bucketizer
Bucketizer transforms a column of continuous features to a column of feature buckets.
For configuration of Bucketizer Transformation, select algorithm Bucketizer.
Enter values in the following parameters:
| Field | Description |
|---|---|
| Input Columns | Input column name over which Bucketizer transformation is to be applied. To apply algorithm on multiple columns, apply Vector Assembler transformation before the algorithm. |
| Output Column | Name of the output column which will contain the transformed values after Binarizer transformation is applied. |
| Splits | Splits are used to define buckets. With n+1 splits, there are n buckets. Splits should be strictly increasing. Use –inf for negative infinity and +inf for positive infinity. |
| Handle Invalid | With this parameter, one can decide what to do with the invalid records. The three options available are Keep/Skip/Error. Keep will keep the invalid value and put it in any of the buckets, Skip will skip that particular record and Error will raise an exception if invalid record is inputted for transformation. |
Imputer
The Imputer transformer completes missing values in a dataset, either using the mean or the median of the columns in which the missing values are located. Imputer doesn’t support categorical features. By default, all null values in the input columns are treated as missing, and so are also imputed. The input columns should be of decimal type.
| Field | Description |
|---|---|
| Input Columns | Input column name over which Imputer transformation is to be applied. You can select multiple Input Columns. |
| Output Column | Name of the output columns. In the output column missing values will be replaced by the surrogate value for the relevant column. You can select multiple columns in Output Column too. However the Input Column and Output Column will be mapping the first input column with first output column and so on and so forth. |
| Strategy | The imputation strategy. Available options are “mean” and “median”. If “mean” is selected, then all the occurrences of missing values will be replaced with using the mean value of the column. If “median” is selected, then all the missing values will be replaced using the approximate median value of the column. Default is mean |
| Missing Value | The placeholder for the missing values. All occurrences of missingValue will be imputed. Note that null values are always treated as missing. |
CountVectorizer
CountVectorizer aim to help convert a collection of text documents to vectors of token counts.
| Field | Description |
|---|---|
| Input Columns | Name of the input column over which Bucketizer transformation is to be applied |
| Output Column | Name of the output columns. Each output column will contain CountVector for the respective input column. |
| Vocabulary Size | Max size of the vocabulary. CountVectorizer will build a vocabulary that only considers the top vocabSize terms ordered by term frequency across the corpus. |
| Minimum Document Frequency | Specifies the minimum number of different documents a term must appear to be included in the vocabulary. If this is an integer >= 1, this specifies the number of documents the term must appear in and if this is a double in [0,1], then this specifies the fraction of documents |
| Minimum Term Frequency | Filter to ignore rare words in a document. For each document, terms with frequency/count less than the given threshold are ignored. If this is an integer >=1, then this specifies a count (of times the term must appear in the document) and if this is a double in [0,1], then this specifies a fraction (out of the document’s token count). |
| Output Size Hint | Mention the size of the output Vector which will be generated after transformation is applied |
| Output Size Handle Invalid | Parameter for handling invalid vectors. Invalid vectors include nulls and vectors with the wrong size. The options are “skip” (filter out rows with invalid vectors), “error” (throw an error) and “optimistic” (do not check the vector size, and keep all rows). Default is “error” |
HashingTF
HashingTF is a transformer which takes sets of terms and converts those sets into fixed-length feature vectors.
| Field | Description |
|---|---|
| Input Columns | Name of the input column over which HashingTF transformation is to be applied |
| Output Column | Name of the output columns. Each output column will contain CountVector for the respective input column. |
| Number of Features | Should be > 0. (default = 2^18) |
| Output Size Hint | Mention the size of the output Vector which will be generated after transformation is applied |
| Output Size Handle Invalid | Parameter for handling invalid vectors. Invalid vectors include nulls and vectors with the wrong size. The options are “skip” (filter out rows with invalid vectors), “error” (throw an error) and “optimistic” (do not check the vector size, and keep all rows). Default is “error” |
IDF
The IDFModel takes feature vectors (generally created from HashingTF or CountVectorizer) and scales each column. Intuitively, it down-weights columns which appear frequently in a corpus.
| Field | Description |
|---|---|
| Input Columns | Name of the input column over which idf transformation is to be applied. |
| Output Column | Name of the output columns. Each output column will contain CountVector for the respective input column. |
| Output Size Hint | Mention the size of the output Vector which will be generated after transformation is applied |
| Output Size Handle Invalid | Parameter for handling invalid vectors. Invalid vectors include nulls and vectors with the wrong size. The options are “skip” (filter out rows with invalid vectors), “error” (throw an error) and “optimistic” (do not check the vector size, and keep all rows). Default is “error” |
MaxAbsScaler
MaxAbsScaler transforms a dataset of Vector rows, rescaling each feature to range [-1, 1] by dividing through the maximum absolute value in each feature. It does not shift/center the data, and thus does not destroy any sparsity.
MaxAbsScaler computes summary statistics on a data set and produces a MaxAbsScalerModel. The model can then transform each feature individually to range [-1, 1].
| Field | Description |
|---|---|
| Input Columns | Name of the input column over which IndexToString transformation is to be applied |
| Output Column | Name of the output columns. Each output column will contain CountVector for the respective input column. |
| Output Size Hint | Mention the size of the output Vector which will be generated after transformation is applied |
| Output Size Handle Invalid | Parameter for handling invalid vectors. Invalid vectors include nulls and vectors with the wrong size. The options are “skip” (filter out rows with invalid vectors), “error” (throw an error) and “optimistic” (do not check the vector size, and keep all rows). Default is “error” |
MinMaxScaler
MinMaxScaler transforms a dataset of Vector rows, rescaling each feature to a specific range (specified by parameter-min/max).
| Field | Description |
|---|---|
| Input Columns | Name of the input column over which MinMaxScaler transformation is to be applied |
| Output Column | Name of the output columns. Each output column will contain CountVector for the respective input column. |
| Minimum Value | Lower bound after transformation, shared by all features. |
| Maximum Value | Upper bound after transformation, shared by all features. |
| Output Size Hint | Mention the size of the output Vector which will be generated after transformation is applied |
| Output Size Handle Invalid | Parameter for handling invalid vectors. Invalid vectors include nulls and vectors with the wrong size. The options are “skip” (filter out rows with invalid vectors), “error” (throw an error) and “optimistic” (do not check the vector size, and keep all rows). Default is “error” |
OneHotEncoder
One-hot encoding maps a column of label indices to a column of binary vectors, with at most one single value. This encoding allows algorithms which expect continuous features, such as Logistic Regression, to use categorical features.
| Field | Description |
|---|---|
| Input Columns | Input column name over which One-Hot Encoder transformation is to be applied. You can add multiple input columns. |
| Output Column | Name of the output columns. Each output column will contain one-hot-encoded vector for the respective input column. You can select multiple columns in Output Column too. However the Input Column and Output Column will be mapping the first input column with first output column and so on and so forth. |
| Drop Last | Whether to drop the last category in the encoded vector. Default value is true |
| Handle Invalid | Parameter for handling invalid values encountered during the transformation. Available options are “keep” (invalid data presented as an extra categorical feature) or “error” (throw an error). Default is “error”. |
| Output Size Hint | Mention the size of the output Vector which will be generated after transformation is applied |
| Output Size Handle Invalid | Parameter for handling invalid vectors. Invalid vectors include nulls and vectors with the wrong size. The options are “skip” (filter out rows with invalid vectors), “error” (throw an error) and “optimistic” (do not check the vector size, and keep all rows). Default is “error” |
NGram
NGram takes as input a sequence of strings (e.g. the output of a Tokenizer). The parameter n is used to determine the number of terms in each n-gram. The output will consist of a sequence of n-grams where each n-gram is represented by a space-delimited string of n consecutive words. If the input sequence contains fewer than n strings, no output is produced.
| Field | Description |
|---|---|
| Input Columns | Name of the input column over which NGram transformation is to be applied. |
| Output Column | Name of the output columns. Each output column will contain CountVector for the respective input column. |
| N-Gram Param | Minimum n-gram length, >= 1. Default value is 2. |
Normalizer
Normalizer is a transformer that transforms a dataset of Vector rows, normalizing each Vector to have unit norm. It takes parameter p, which specifies the p-norm used for normalization. (p=2 by default.) This normalization can help standardize your input data and improve the behavior of learning algorithms.
| Field | Description |
|---|---|
| Input Columns | Name of the input column over which Normalizer transformation is to be applied |
| Output Column | Name of the output columns. Each output column will contain CountVector for the respective input column. |
| Norm | Normalize a vector to have unit norm using the given p-norm. P-norm value is given by this norm Param |
| Output Size Hint | Mention the size of the output Vector which will be generated after transformation is applied |
| Output Size Handle Invalid | Parameter for handling invalid vectors. Invalid vectors include nulls and vectors with the wrong size. The options are “skip” (filter out rows with invalid vectors), “error” (throw an error) and “optimistic” (do not check the vector size, and keep all rows). Default is “error” |
PCA
PCA is a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components. A PCA class trains a model to project vectors to a low-dimensional space using PCA.
| Field | Description |
|---|---|
| Input Columns | Name of the input column over which PCA transformation is to be applied. |
| Output Column | Name of the output columns. Each output column will contain CountVector for the respective input column. |
| Number of Principal Components | Number of principal components. |
| Output Size Hint | Mention the size of the output Vector which will be generated after transformation is applied. |
| Output Size Handle Invalid | Parameter for handling invalid vectors. Invalid vectors include nulls and vectors with the wrong size. The options are “skip” (filter out rows with invalid vectors), “error” (throw an error) and “optimistic” (do not check the vector size, and keep all rows). Default is “error”. |
StandardScaler
StandardScaler transforms a dataset of Vector rows, normalizing each feature to have unit standard deviation and or zero mean.
| Field | Description |
|---|---|
| Input Columns | Name of the input column over which StandardScaler transformation is to be applied. |
| Output Column | Name of the output columns. Each output column will contain CountVector for the respective input column. |
| With Std Dev | Whether to scale the data to unit standard deviation or not. |
| With Mean | Whether to center the data with mean before scaling or not. |
| Output Size Hint | Mention the size of the output Vector which will be generated after transformation is applied |
| Output Size Handle Invalid | Parameter for handling invalid vectors. Invalid vectors include nulls and vectors with the wrong size. The options are “skip” (filter out rows with invalid vectors), “error” (throw an error) and “optimistic” (do not check the vector size, and keep all rows). Default is “error” |
StopWordsRemover
Stop words are words which should be excluded from the input, characteristically because the words appear frequently and do not carry much meaning.
StopWordsRemover takes as input a sequence of strings (e.g. the output of a Tokenizer) and drops all the stop words from the input sequences. The list of StopWords is specified by the StopWords parameter.
| Field | Description |
|---|---|
| Input Columns | Name of the input column over which StandardScaler transformation is to be applied. |
| Output Column | Name of the output columns. Each output column will contain CountVector for the respective input column. |
| Load Default Stop Words | When you check this checkbox it asks for input language of which you want to pick default stop words to be removed by StopWordsTransformer. Some of the options include English, French, Spanish etc. |
| Language | English |
| Case Sensitive | Whether stop words are case sensitive or not |
Tokenizer
Tokenization is the process of taking text (such as a sentence) and breaking it into individual terms (usually words). A simple Tokenizer class provides this functionality.
| Field | Description |
|---|---|
| Input Columns | Name of the input column over which Tokenizer transformation is to be applied. |
| Output Column | Name of the output columns. Each output column will contain CountVector for the respective input column. |
| Pattern | Regex pattern used to match delimiters if [[gaps]] is true or tokens if [[gaps]] is false. |
| Gaps | Indicates whether regex splits on gaps (true) or matches tokens (false). |
VectorAssembler
VectorAssembler is a transformer that combines a given list of columns into a single vector column.
| Field | Description |
|---|---|
| Input Columns | Input column name over which VectorAssembler transformation is to be applied |
| Output Column | Name of the output columns. Each output column will contain CountVector for the respective input column. |
VectorIndexer
VectorIndexer helps index categorical features in datasets of Vectors. It can both automatically decide which features are categorical and convert original values to category indices.
For Configuration of VectorIndexer Transformation one has to select as algorithm VectorIndexer on the transformations tab. It asks for various configuration fields. Their description is as below:
| Field | Description |
|---|---|
| Input Columns | Name of the input column over which VectorIndexer transformation is to be applied. |
| Output Column | Name of the output columns. Each output column will contain CountVector for the respective input column. |
| Max Categories | Threshold for the number of values a categorical feature can take. If a feature is found to have > maxCategories values, then it is declared continuous. Must be >= 2. |
| Output Size Hint | Mention the size of the output Vector which will be generated after transformation is applied |
| Output Size Handle Invalid | Parameter for handling invalid vectors. Invalid vectors include nulls and vectors with the wrong size. The options are “skip” (filter out rows with invalid vectors), “error” (throw an error) and “optimistic” (do not check the vector size, and keep all rows). Default is “error” |
Word2Vec
Word2Vec maps each word to a unique fixed-size vector.
For configuration of Word2Vec Transformation, one has to select as algorithm Word2Vec on the transformations tab. It asks for various configuration fields. Their description is as below:
| Field | Description |
|---|---|
| Input Columns | Name of the input column over which Word2Vec transformation is to be applied. |
| Output Column | Name of the output columns. Each output column will contain CountVector for the respective input column. |
| Vector Size | The dimension of the code that you want to transform from words. Default value is 100. |
| Window Size | The window size (context words from [-window, window]) default 5 |
| Step Size | The step size. |
| Min Count | The minimum number of times a token must appear to be included in the word2vec model’s vocabulary. Default value is 5. |
| Max Iteration | The max iteration. |
| Max Sentence Length | Set max sentence lengt.h |
| Output Size Hint | Mention the size of the output Vector which will be generated after transformation is applied. |
| Output Size Handle Invalid | Parameter for handling invalid vectors. Invalid vectors include nulls and vectors with the wrong size. The options are “skip” (filter out rows with invalid vectors), “error” (throw an error) and “optimistic” (do not check the vector size, and keep all rows). Default is “error”. |
StringIndexer
StringIndexer encodes a string column of labels to a column of label indices. The indices are in [0, numLabels), ordered by label frequencies, so the most frequent label gets index 0. The unseen labels will be put at index numLabels if user chooses to keep them. If the input column is numeric, we cast it to string and index the string values.
For configuration of StringIndexer Transformation, one has to select as algorithm StringIndexer on the transformations tab. It asks for various configuration fields. Their description is as below:
| Field | Description |
|---|---|
| Input Columns | Name of the input column over which StringIndexer transformation is to be applied |
| Output Column | Name of the output columns. Each output column will contain CountVector for the respective input column. |
| Handle Invalid | With this parameter, one can decide what to do with the invalid records. The three options available are Skip/Error. Skip will skip that particular record and Error will raise an exception if invalid record is inputted for transformation. |
Feature Hasher
Feature Hasher projects a set of categorical or numerical features into a feature vector of specified dimension. This is done using a hashing trick to map features to indices in the feature vector. Null (missing) values are ignored (implicitly zero in the resulting feature vector).
For configuration of Feature Hasher, one has to select the algorithm on the transformations tab. It asks for various configuration fields. The description is as below:
| Field | Description |
|---|---|
| Input Columns | Name of the input column over which Feature Hasher transformation is to be applied |
| Output Column | Name of the output column which will contain the transformed feature vector. |
| Num Features | Number of features. Should be greater than 0. (default = 2^18^) |
| Categorical Columns | Numeric columns to treat as categorical features. By default only string and boolean columns are treated as categorical, so this param can be used to explicitly specify the numerical columns to treat as categorical. Note, the relevant columns must also be set in inputCols. |
| Output Size Hint | Mention the size of the output Vector which will be generated after transformation is applied |
| Output Size Handle Invalid | Parameter for handling invalid vectors. Invalid vectors include nulls and vectors with the wrong size. The options are “skip” (filter out rows with invalid vectors), “error” (throw an error) and “optimistic” (do not check the vector size, and keep all rows). Default is “error” |
Post-Processing
The post-processing tab enables you to perform transformations on model output before displaying the final result.
Currently, Gathr supports only one algorithm i.e IndexToString for post-processing.
IndexToString
IndexToString maps a column of label indices back to a column containing the original labels as strings. A common use case is to produce indices from labels with StringIndexer, train a model with those indices and retrieve the original labels from the column of predicted indices with IndexToString. However, you are free to supply your own labels.
| Field | Description |
|---|---|
| Input Columns | Name of the input column over which IndexToString transformation is to be applied |
| Output Column | Name of the output columns. Each output column will contain CountVector for the respective input column. |
| Labels | Labels to be used for transforming inputs indices into String. There are two options for doing this either user can reuse labels created in the pipeline earlier while any of the StringIndexer Transformations or it can specify new labels over here only. |
| Select StringIndexer | Select the StringIndexer from the transformation chain on which IndexToString algorithm needs to be applied. |
Model Evaluation
Evaluate models on the metrics available for the ML algorithm.
Model Evaluation is configured using the following three properties:
| Field | Description |
|---|---|
| Enable Model Evaluation | Select the box for Enabling the model for evaluation. |
| Train Ratio | Ratio in which incoming data will be split for training and testing. Value should be between 0 and 1. Example – 0.7 (70% data will be used for training and 30% for testing) |
| Select Metric | The metric on which user wants to evaluate the model. |
Hyper Parameters
Using this tab, you are able to optimize hyper parameters of algorithms used in the transformation chain.
| Field | Description |
|---|---|
| Execute Tuning | When selected, enables model tuning and evaluation. |
| Validation Type | Tools used for tuning the model: Cross validation: In cross-validation, you make a fixed number of folds (or partitions) of the data, run the analysis on each fold, and then average the overall error estimate. Train Validation Split: Train Validation Split creates a single dataset pair. When Train Validation Split is selected, specify value for Train Validation Ratio. Note: If Enable Model Evaluation is checked under Model Evaluation tab, then Train Ratio parameter is not available, since you are already added train ratio in Model Evaluation Tab. |
| Number of Folds | Specifies the number of folds for cross validation. Must be greater than or equal to two. Default value is three. |
| Tuned Model Name | Name of the Model created after applying Hyper Parameter Training. |
| Description | Summary or short description of the model. |
| Tags | Tags to be associated with the model. |
| Version Comments | A note about the model version. |
| Metric for evaluation | Select the metric to be used for model evaluation. |
| Train Ratio | Ratio between train and validation data. Must be between zero and 1. Default is 0.75 |
| Tuned Model Name | Model created after Hyper Parameter model training. |
| Connection Name | All HDFS connections will be listed here. Select the HDFS connection where model is to be saved. |
| HDFS Path | Specify HDFS path for saving the model. |
Enter the notes in the specified area.
Click on the SAVE button after entering all the information.
Prediction/Model Scoring
Using Models Trained in Gathr
Once the model is trained using training pipelines, it is registered to be used for scoring in any pipeline.
To use a trained model in a pipeline for scoring, drag and drop the analytics processor and change the mode of analytics processor from training to prediction.
| Field | Description |
|---|---|
| Operation | Type of operation to be performed by Operator. It could be Training or Prediction operation. |
| Algorithm Type | Select the Model Class, it could be Regression or Classification. |
| Model Name | Name of the model to be created when the training model is activated or the model name to be used for the prediction when the prediction mode is activated. |
| Message Name | Name of the message that will be used in the pipeline. |
| Detect Anomalies | Select to detect anomalies in the input data. |
| Anomaly Threshold | This is the threshold distance between a data point and a centroid. If any input data point’s distance to its nearest centroid exceeds this value then that data point will be considered as an anomaly. |
| Is Anomaly Variable | Input message field that will contain the result of anomaly test i.e. it will be true if a data record is an anomaly or false otherwise. |
Note:
Operations, Message Name Model Name- Common for models
Anomaly options are only available for K means and Algorithm Type is available for Decision Tree, GBT ands Random Forest models.
Save the analytics processor and connect an emitter, for verifying the output.
Once the pipeline is saved, run it for predicting the output.
Using Externally Trained Models
For using externally trained model into Gathr, register the model from Register Models → tab.
Registering Trained Models
For registering a model, do as follows:
Click on the Register Models option on the left pane.
Click on the (+) icon shown in the top-right corner of register models page.
A new window will open, enter model related parameters such as name of the model, whether pipeline model or not, API used for creating model and the algorithm type of the model.
In case of Tree Ensemble based models, select, if the model is for classification problem or regression one.
After configuring the above fields, upload model for registration or provide HDFS path wherein the model is saved.
Validate the model by clicking validate model button, if it fails then the trained model is incorrect and if it is valid, register the model for prediction by clicking on the register model button.
Once the model is registered, you can use it for Prediction.
If you have any feedback on Gathr documentation, please email us!