Neo4j
This component is supported in Gathr on-premise.
| Field | Description |
|---|---|
| Connection Name | Connection name of the created connection for Neo4j. |
| Batch Read | Check the option to enable the batch processing. |
| Database Name | Name of the database from which data will be read. |
| Read Mode | Select one of the below option to fetch the records from Neo4j database. The available options are explained below. |
| Cypher Query | Options to provide a cypher query. Example: CREATE (n:Person {fullName: event.name + event.surname}). |
| Nodes | You can read nodes by specifying a single label, or multiple labels. Label list can be specified with starting colon. Example, :Person:Customer |
Upon selecting Relationship option, the below fields are available:
| Relationship | Option to define type of relationship. Specify the mapping detail, the source node, and the target node label as explained below. |
| Mapping | Check the option to control the result format by the mapping option. The result format can be controlled by the relationship.nodes.map Default is false. When it is set to false, source and target nodes properties are returned in separate columns prefixed with source or target. (i.e., source.name, target.price). When it is set to true, the source and target nodes properties are returned as Map[String, String] in two columns named source and target. |
| Source Nodes | Provide source nodes column. Example: MATCH (source:Person)-[rel: BOUGHT]->(target:Product) RETURN source, rel, target. Here, source:Person. |
| Target Nodes | Provide target nodes column. Example: MATCH (source:Person)-[rel: BOUGHT]->(target:Product) RETURN source, rel, target. Here target:Product. |
Remaining common fields are as below:
| Schema Flatten Limit | Number of records to be used to create the schema. |
| Schema Strategy | Strategy used by the connector in order to compute the schema definition for the dataset. Possible values are String and Sample. |
| Partitions | This defines the parallelization level while pulling data from Neo4j. |
| ADD CONFIGURATION | Option to add further configurations by providing the key-value pair. |
If you have unchecked Batch option, the below fields will appear in case of streaming dataset case:
| Streaming From | This option is used to trigger the connector from where to send data to the stream. You can select NOW (Starts reading from the current timestamp.) or All (Sends all the data to the database to the stream before reading the data). |
| Incremental Read Property | The timestamp property name used for incremental reading. |
You have an option to add Environment parameters as mentioned below:
ENVIRONMENT PARAMS
| ADD PARAMS | Option to add further environment parameters by providing the key-value pair. |
Rename Column Name
In certain scenarios if the Column Name has special characters, you can use the Rename processor available in gathr.
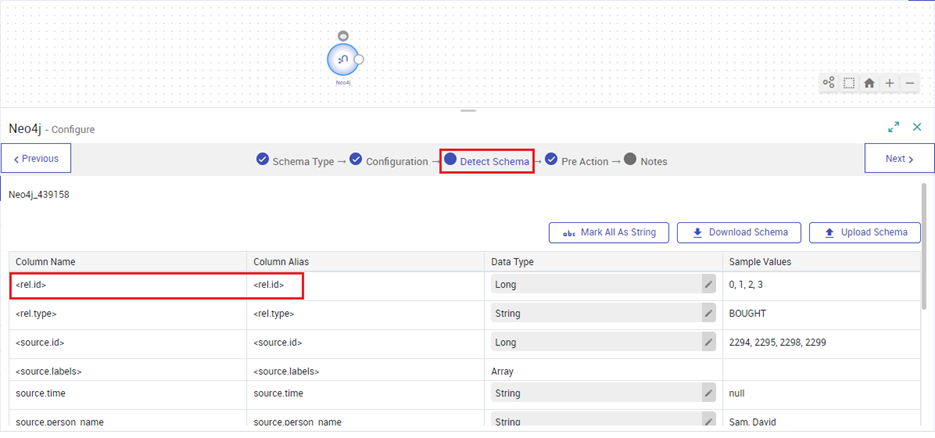
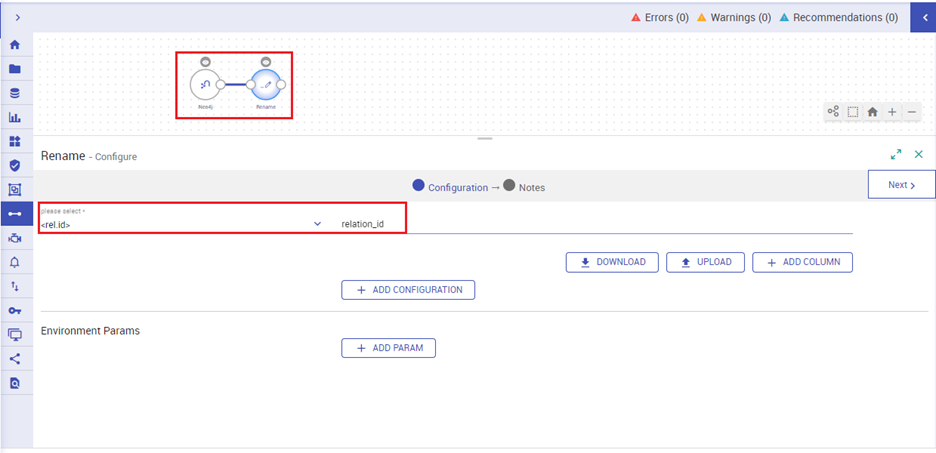
Under the Detect Schema screen, select the Rename processor and join it with Neo4j source. Configure it by providing the desired column name as against the existing column name that contains special characters. Click Next for to see the renamed column name.
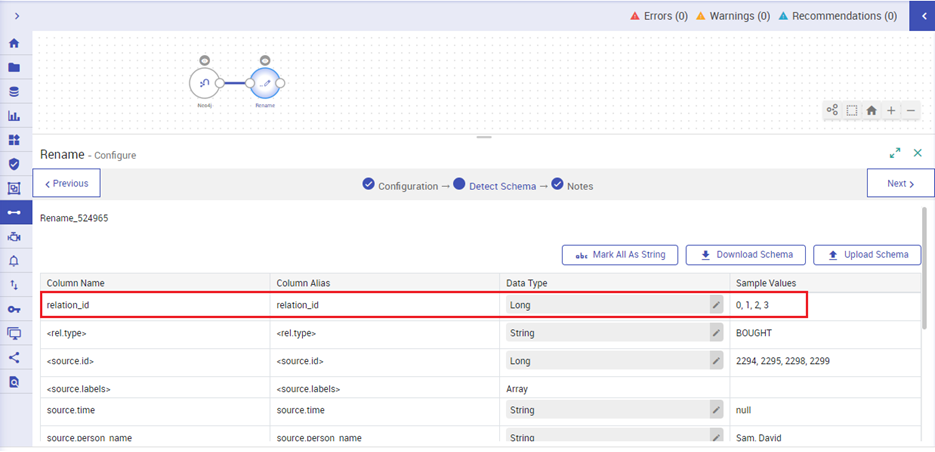
As shown below, the column name is updated.
If you have any feedback on Gathr documentation, please email us!