Cloud SQL
Data can be emitted using the Cloud SQL component. You can select this component from the components panel and join it with the pipeline to configure.
Configuring Cloud SQL Emitter
Under the configuration tab the below details are available:
| Field | Description |
|---|---|
| Connection Name | Connections are the Service identifiers. Select the connection name from the drop-down list. |
| Override Credential | Select the override credentials option check-box for overriding the credentials. |
| Username | Provide the database username that has access to data. |
| Password | Provide the database user password. Click TEST CONNECTION button to test the connection. |
| Message Name | The name for the message configuration that will act as a metadata for the actual data from source. |
| Schema Name | Select the table name from the dropdown to show the table properties. |
| Table Name | Existing table name for the specified database. |
| Is Batch Enabled | Enable parameter to batch multiple parameters to improve the write performance. Option available are TRUE/FALSE. |
| Batch Size | Provide value for batch size that would determine the rows to be inserted per round trip. This can help performance on JDBC drivers. This option is application only on writing. Default value is 1000. |
| Connection Retries | The number of retries for component connection. Possible values are -1, 0 or positive number where -1 signifies multiple retries. |
| Delay Between Connection Retries | This option lets you define the retry delay interval (milliseconds) for component connection. |
| Save Mode | Save mode specifies how to handle existing data (if present) in case of batch source. Save Mode is used to specify the expected behavior of saving data to a data sink. Available options are: Append: When persisting data, if data/table already exists, contents of the Schema are expected to be appended to existing data. Overwrite: When persisting data, if data/table already exists, existing data is expected to be overwritten by the contents of the Data. ErrorifExist: When persisting data, if the data already exists, an exception is expected to be thrown. Ignore: When persisting data, if data/table already exists, the save operation is expected to not save the contents of the Data and to not change the existing data. Update: Output Mode in which only the rows that were updated in the streaming data will be written to the sink every time there are some updates. |
| Update Only | This option can be used if Output Mode is selected as Update since it updates the existing data with the help of primary key. |
| Ignore Values | Enable the check-box to ignore the value for incoming data. |
| Priority | This option let you decide the priority to execute orders for emitters. |
| ADD CONFIGURATION | Click the ADD CONFIGURATION button to add further configurations as key-value pair. |
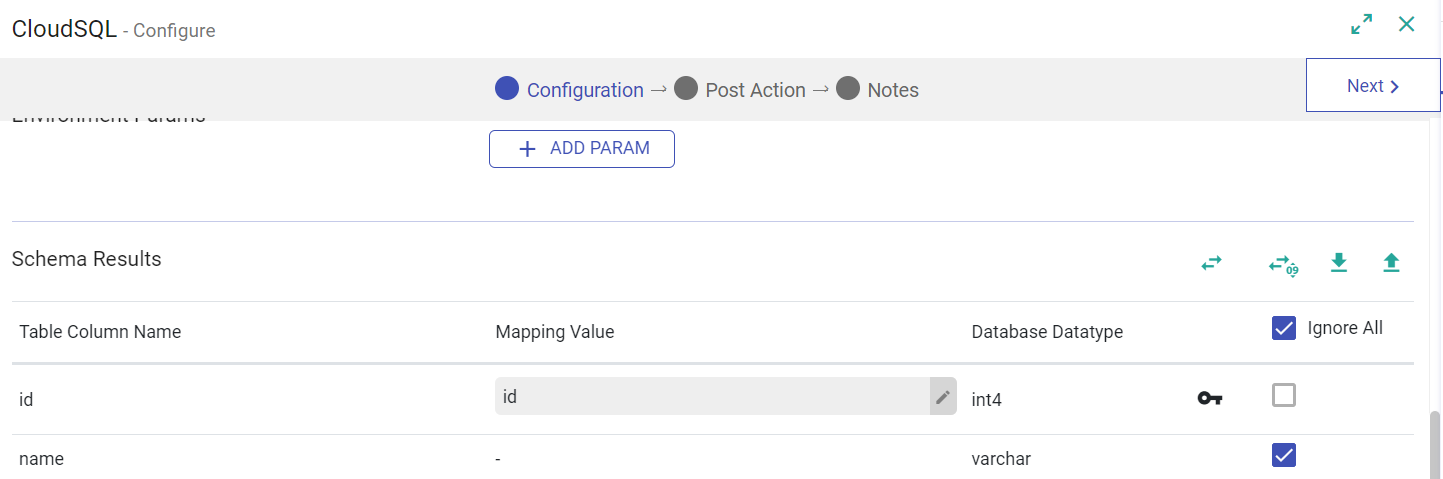
| Environment Params | Click the ADD PARAMS option to add further parameters as key-value pair. |
| Schema Results | Under the Schema Results you can see Table Column Name, Mapping Value, Database Datatype exampe: varchar, int etc., Ignore All. You have an option to ignore a particular column by clicking at the check-box. If you click Ignore All then the first column remains unchecked since a minimum of one column mapping is required. Other options available are: Auto Fill, Auto Fill Sequentially, Download Mapping and Upload Mapping as shown in the image below. |
If you have any feedback on Gathr documentation, please email us!