Reuse Datasets
A dataset can be reused using the Reuse option.
You can reuse any dataset, on any channel if the dataset schema matches the channel source schema. Otherwise, a warning and a no-association error message will be displayed.
You can choose any existing dataset from the listed datasets. Once you choose the selected dataset, the schema is automatically applied, and the results are populated during inspect.
For an emitter, only the schema of a dataset should match with the emitter’s output data, otherwise, reuse option will be converted to disassociation. Reuse will associate the dataset to the pipeline which will be reflected in the data lineage window.
How to use an Existing Dataset
To use an existing dataset, you can create a pipeline and while you are configuring the Data Source, choose the option Use Existing Dataset, as shown below:
Example
A pipeline consists of an RMQ Data Source + DFS Data Source > Union Processor > DFS Emitter.
This example covers different possibilities of a data pipeline, where an existing dataset can be used.
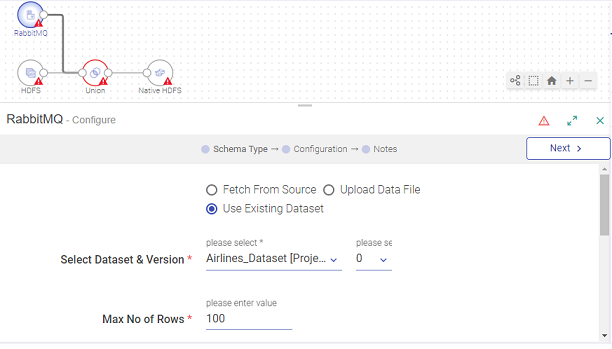
RabbitMQ Data Source: An existing dataset is used.
DFS Data Source: The option to Save as dataset is used.
DFS Data Sink: The option to Save as dataset is used.
Now, using these options a Data Pipeline will be created and those datasets will be listed on the Dataset homepage (dataset list page). While editing the pipeline, the option to reuse the existing dataset will be reflected for the RMQ data source as well.
Under the configuration of the RabbitMQ Data Source, select Use Existing Dataset.
Then select the dataset and version.
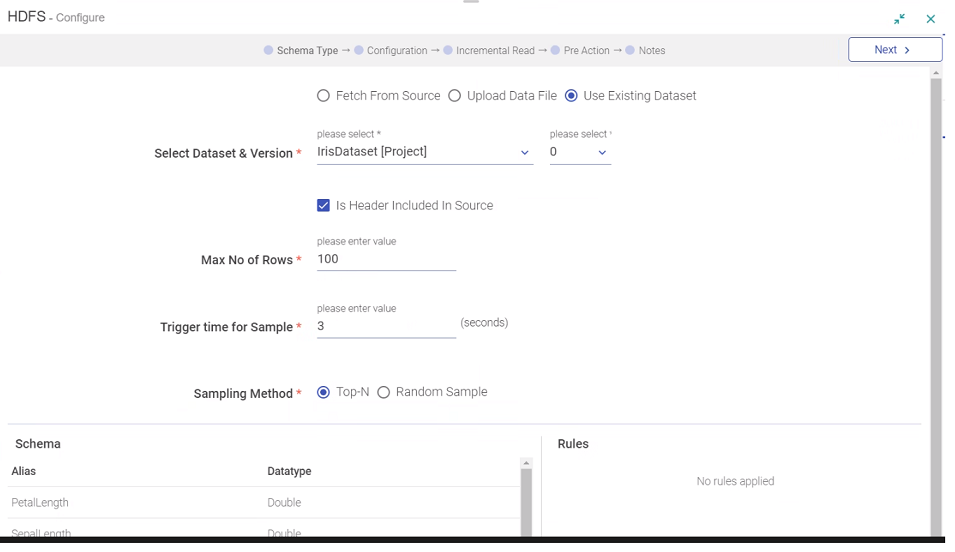
In the Select Dataset section, you can see the selected dataset’s schema and rules to identify advanced dataset details, which would be applied in the Data Source.
Click Next, to continue the configuration of RMQ. Configure RabbitMQ as required and click Next to go to the Detect Schema page; where the schema will be applied.
If the source schema and dataset schema matches or is applied successfully, then you will see the Detect schema results with sample values.
If there is a mismatch in the schema, you will see warning messages on Detect Schema window. As a result, the dataset will not be associated with the pipeline and that pipeline will not be a part of lineage (dataset lineage part is in later implementation). However, you can continue with failed conditions.
After configuring RMQ with a successful match, you can view the inspect results. In the image below, you can see the results with the applied dataset schema as well as rules.
Configure HDFS Data Source:
Under Schema Type, choose Fetch From Source, and then go to the Configuration page.
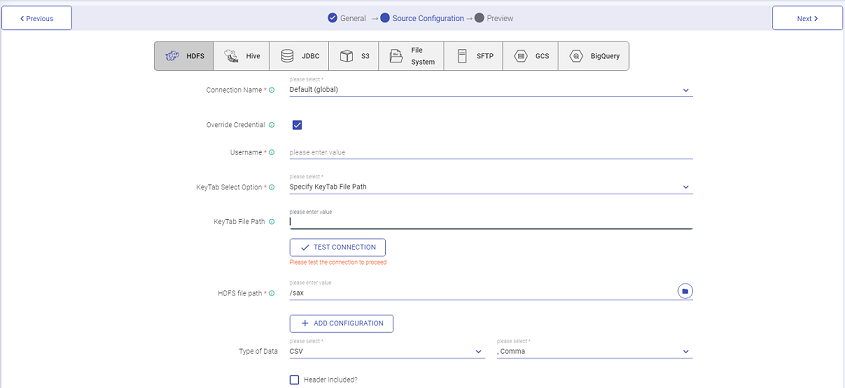
Go to detect schema, you can see the Save As Dataset option, as it is one of the channels where dataset can be created through pipeline.
Check “Save As Dataset” option and provide a name for the dataset (for example, dfs_channel_dataset). Save the channel.
Configure Union, then configure the DFS emitter. You can see Save As Dataset option, as it is one of the emitters where a dataset can be created through pipeline.
Check Save As Dataset option and provide a name for the dataset (for example, dfs_emitter_dataset). Save the emitter.
Now, save the pipeline with a name (for example, pipeline_with_reuse_datasets). Go to the Datasets list. You can see two datasets created, one from the DFS channel and the other from the DFS emitter.

Now, edit the pipeline “pipeline_with_reuse_datasets”.
Open the DFS channel component, you will see “Use Existing Dataset” option selected, new dataset name, its 0-version selected and its details. The reason is, you have saved “dfs_channel_dataset” dataset on channel and now it has become a part of it in the pipeline. The same will be reflected in the lineage association.
Now under the detect schema window (with auto inspect on) of DFS channel, you will not see the “Save As Dataset” option but will see read-only results with applied “dfs_channel_dataset” results. Reason is that currently channel has become “Use Existing Dataset” case.
Now edit the DFS emitter the “Save As Dataset” option will be shown with the saved name. This means the dataset is still associated with the pipeline and will be part of the lineage (later implementation).
Now remove one of the output fields (like matchid) in the DFS emitter, to change its schema. Click Next, you will be warned with message and emitter dataset will be disassociated and will not be a part of lineage (later implementation)
If you have any feedback on Gathr documentation, please email us!