Deploy a Pipeline
Configure Job brings you to deploy the pipeline on cloud clusters.
For an AWS platform you can deploy pipelines on Databricks and EMR.
After a pipeline is created, you have two options, either deploy the pipeline on any of the existing clusters from Databricks or EMR, the second option is to deploy the pipeline on a job cluster. However this depends on the type of job that your will run.
You can choose the if the pipeline will be deployed on the Job Clusters or a Long Running or Interactive Clusters. When you want to deploy a pipeline on a Job cluster, the rule is that the job ends as soon as the pipeline is completed. However for an Interactive and Long running jobs, you can deploy the pipelines on the clusters created for Databricks and EMR.
To understand the Pipeline Clusters, you can also refer the Cluster List View section of the Administration Guide.
To deploy a pipeline, configure the same on Databricks or EMR.
Once you click on Configure Job, you will be redirected to the Job Configuration Page.
Configure Job on Databricks
Under Databricks, following are the properties that you would need to configure.
Databricks has two types of clusters: Interactive and Job.
Configuration of a Databricks cluster is divided in six categories: Cluster, Schedule, Alerts, Runs, Timeout and Retries.
Interactive clusters (Long-running cluster)
Interactive clusters are used to analyze data collaboratively with interactive notebooks.
All the Interactive clusters associated with pre-configured Databricks instance appear here. These clusters will be running even after the jobs running on them are finished; user has to manually terminate these cluster.
Databricks will allow you to deploy your pipeline on an existing Interactive cluster.
Job clusters (New cluster)
Job clusters are associated with a particular pipeline and these clusters will be active as long as the pipeline is running. These clusters will be terminated as soon as the pipeline is stopped.
Configure Job on EMR
Under EMR, following are the properties that you would need to configure.
EMR has two types of clusters: Interactive and Job.
Interactive clusters
Interactive clusters are used to analyze data collaboratively with interactive notebooks.
All the Interactive clusters associated with pre-configured EMR instance appear here. These clusters will be running even after the jobs running on them are finished; you will have to manually terminate these Cluster.
EMR will allow you to deploy your pipeline on an existing Interactive Cluster.
Job Clusters (New Cluster)
Job Clusters are associated with a particular pipeline and these will be active as long as the pipeline is running. These clusters will be terminated as soon as the pipeline is stopped.
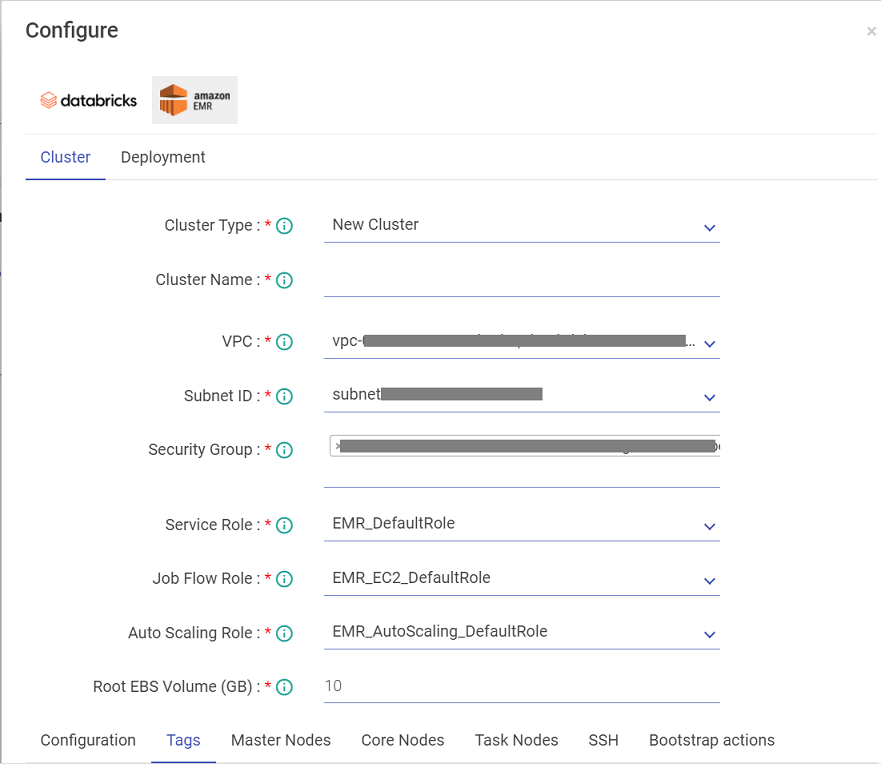
User can now create tags by giving some key value pairs. Once added, they will get associated with the EMR Cluster which can be seen on the Instance page.It can be added for both, the job cluster and the long running cluster.
If you have any feedback on Gathr documentation, please email us!