Auto Schema
You can define the schema while loading the data with Auto Schema feature.
First load data from a source, then infer schema, modify data types and determine the schema on the go. This feature helps design the pipeline interactively.
Data can be loaded in the form of CSV/TEXT/JSON/XML/Fixed Length/Binary/Avro/ORC/Binary and Parquet file or you can fetch data from sources such as Kafka, JDBC and Hive.
Auto schema enables the creation of schema within the pre-built operators and identifies columns in CSV/JSON/TEXT/XML/Fixed Length/Binary (Kinesis supports Avro Binary format) and Parquet.
Gathr starts the inference by ingesting data from the data source. As each component processes data, the schema is updated (as per the configuration and the logic applied). During the process, Gathr examines each field and attempts to assign a data type to that field based on the values in the data.
All of Gathr’s components (data sources) have auto schema enabled.
To add a Data Source to your pipeline, drag the Data Source to the canvas and right-click on it to configure.
There are three tabs for configuring a component.
Schema Type
Configuration
Incremental Read
Add Notes
Schema Type
Schema Type allows you to create a schema and the fields. On the Schema Type tab, select either of the below mentioned options:
Fetch from Source
Upload Data File
Use Existing Dataset
Whether the data is fetched from the source or uploaded, the following configuration properties remain the same:
| Field | Description |
|---|---|
| Type Of Data | Input format of Data. |
| Is Header Included in Source | Option to enable header in source data. |
| Enable PII Masking | Option to enable PII (Personally Identifiable Information) masking. To know more, see PII Masking → processor. |
| Max no. of Rows | Maximum no. of the rows. Sample to pull from Streaming Source. |
| Trigger time for Sample | Minimum wait time before system fires a query to fetch data. Example: If it is 15 Secs, then the system will first wait for 15 secs and will fetch all the rows available and create dataset out of it. |
| Sampling Method | Dictates how to extract sample records from the complete data fetched from the source. Following are the ways: -Top N: Extract top n records using limit() on dataset. -Random Sample: Extract Random Sample records applying sample transformation and then limit to max number of rows in dataset. |
Fetch from Source
Fetch data from any data source.
Depending on the type of data, determine the Data Source you want to use, then recognize the type of data (or data format) and its corresponding delimiters.
These are types of data formats supported by Gathr to extract schema from them; Avro, CSV, JSON, TEXT, XML, Fixed Length, ORC, Binary and Parquet.
Once you choose a data type, you can edit the schema and then configure the component as per your requirement.
Fetch from Source > Configuration > Schema > Add Notes
CSV
The data that is being fetched from the source is in the CSV format. From within the CSV, the data columns that will be parsed, will be accepting the following delimiters.
Tab
, Comma
: Colon
; Semi Colon
| Pipe
The default delimiter is comma (,).
If the data is fetched from the source, after uploading a CSV/TEXT/JSON/Parquet, next tab is the Configuration, where the Data Sources are configured and accordingly the schema is generated. Then you can add notes, and save the Data Source’s configuration.
JSON
Select JSON as your Type of Data. The data that is being fetched from the source is in JSON format. The source will read the data in the format it is available.
XML
The System will fetch the incoming XML data from the source.
Select XML as your Type of Data and provide the XML XPath value.
XML XPath - It is the path of the tag of your XML data to treat as a row. For example, in this XML <books> <book><book>…</books>, the appropriate XML Xpath value for book would be /books/book.
The Default value of XML XPath is ‘/’ which will parse the whole XML data.
Fixed Length
The System will parse the incoming fixed length data. Select ‘Fixed Length’ as your Type of Data and Field Length value.
The Field length value is a comma separated length of each field.
Example:
If there are 3 fields f1,f2,f3 and their max length is 4,10 & 6 respectively.Then the field length value for this data would be 4,10,6.
Binary
Gathr supports reading of binary data from various sources including HDFS, S3, ADLS, GCS, SFTP and Kafka. You can either upload a binary file or use the Fetch From Source option to read the source. During runtime the pipeline should be able to process data in batch and streaming mode.
Parquet
Select Parquet as your Type of data. The file that is being fetched from the source is in parquet format. The source will read the data in the format it is available.
Text
Text message parser is used to read data in any format from the source, which is not allowed when csv, json etc. parsers are selected in configuration. Data is read as text, a single column dataset.
When you select the TEXT as “Type of Data” in configuration, data from the source is read by Gathr in a single column dataset.
To parse the data into fields append the Data Source with a Custom Processor → where custom logic for data parsing can be added.
Upload Data File
Upload your data either by using a CSV, TEXT, JSON, XML, Fixed Length, Avro, Parquet, OCR file.
Once you choose either data type, you can edit the schema and then configure the component as per your requirement:
Upload Data File > Detect Schema > Configuration > Add Notes
CSV
You can choose the data type as CSV and the data formats are as follows:
Comma
Tab
Colon
Semi Colon
Pipe
A CTRL+A
You need to specify the format of the data source. For this a few sample records need to be provided such as Max no of Rows, Trigger time for Sample, Sampling method.
Upon selecting CSV option as Type of data, follow below instructions for specific scenarios.
The user can provide their own custom delimiter while selecting or uploading a .csv file. There are a few use cases where user needs to specifically provide some special ASCII characters for the system to detect those characters. For an example while providing a backslash/double quote/delimiter which is a part of the value itself, you need to provide the special ASCII characters as explained below:
If a Delimiter is part of any Value, then the respective value needs to be quoted with double quotes.
For an example: Hash(#) is the Delimiter and the provided value is @$"#"$^&#*( which is having # as a value therefore in this scenario en-quote this value with ““, so that the value appears as “@$”#"$^&#*("
In this case the complete row will appear as- “@$”#"$^&#*("#“2017-07-23”#“Kayle Duffill”#“Furniture”#“Female”#“Cash”#"+1 (717) 934-4029"
If Double Quote is part of the value, then the double quotes in the value needs to be replaced by placing another quote with the actual value as mentioned in the below example:
“@$”#"$^&#*(" there are two double quotes present in value, so both should be preceded by another quote which means our final value of column will be - “@$”"#”"$^&#*(”,
The quotes surrounding the complete column value which you add to escape delimiter{#) should not be double quoted, only the double quote which is in the value should be double quoted.If user requires to use a backslash () as a single delimiter value then in that case, the actual delimiter value that has to be provided by the user has to be a double backslash (\) for the system to read it as a single backslash value.
Likewise, in case double backslash (\) value is to be provided in the value, then the user will be required to provide four backslash values (\\) for the system to read it as double backslashes.
Example of a sample test data:
“name”"age""phone"
“virat”"23""987653451"
“yuvraj”"37""
“sachin”"23""98765345245431"
“saurav”"40""9876523sdf"
“dhoni”"40""987653451"
channel used :=blob batch
upload file, select csv as file type and enter \ as delimiter
In the subsequent step you can validate the schema of the incoming source. For example: after CSV/TEXT/JSON/XML Fixed Length is uploaded, next tab is the Detect Schema, which can be edited by overriding the automatically detected schema.Next is the Configuration tab, where the Data Sources are configured as per the schema. Then you can add notes, and save the Data Source’s configuration.
Detect Schema
The following fields in the schema are editable:
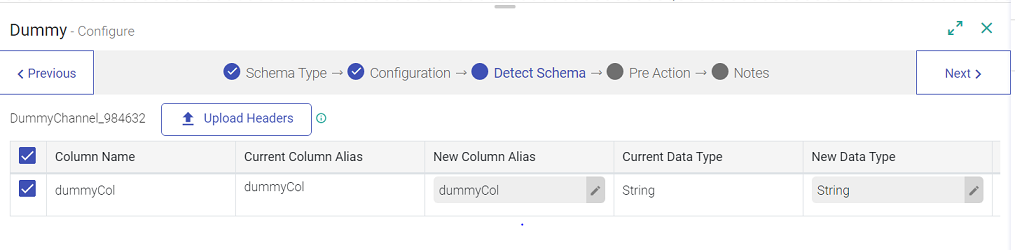
Schema Name: Name of the Schema can be changed.
Column Alias: Column alias can be renamed.
Date and Timestamp: Formats of dates and timestamps can be changed.
Gathr has migrated from spark 2 to spark 3.0.For further details on supported timestamp formats in Spark 3.0, click here.
Data Type: Field type can be any one of the following and they are editable:
String
Integer
Long
Short
Double
Float
Byte
Boolean
Binary
Vector
JSON
When you select JSON as your type of data, the JSON is uploaded in the Detect Schema tab, where you can edit the Key-Value pair.
After the schema is finalized, the next tab is configuration of Data Source (Below mentioned are the configurations of every Data Source).
In case of Hive → and JDBC →, the configuration tab appears before the Detect schema tab.
TEXT
The Text files can be uploaded to a source when the data available requires customized parsing. Text message parser is used to read data in any format from the source, which is not allowed when CSV, JSON, etc. parsers are selected in configuration.
To parse the data into fields append the Data Source with a Custom Processor → where custom logic for data parsing can be added.
XML
The system will parse the incoming XML data from the uploaded file. Select XML as your Type of Data and provide the XML XPath of the XML tag. These tags of your XML files are reflected as a row.
Example: In XML <books> <book><book>…</books>, the output value would be /books/book
You can also provide / in XML X path. It is generated by default.
‘/’ will parse the whole XML
Fixed Length
The system will parse the incoming fixed length data. If the field has data in continuation without delimiters, you can separate the data using Fixed Length data type.
Separate the field length (numeric unit) by comma in the field length.
Parquet
When Parquet is selected as the type of data, the file is uploaded in the schema and the fields are editable.
Parquet is only available in HDFS → and Native DFS Receiver →
Auto schema infers headers by comparing the first row of the file with other rows in the data set. If the first line contains only strings, and the other lines do not, auto schema assumes that the first row is a header row.
After the schema is finalized, the next tab is configuration. Once you configure the Data Source, you can add notes and save the Data Source’s configuration.
Use Existing Dataset
Along with fetching data from a source directly and uploading the data on the data source; you can also, use an existing dataset in the data source RabbitMQ and DFS.
To know more, see the topic, How to use an Existing Dataset in the Dataset Section.
If you have any feedback on Gathr documentation, please email us!