AWS RDS Postgres-Kafka-CDC
Turn on Logical Replication
To turn on logical replication in RDS for PostgreSQL, modify a custom parameter group to set rds.logical_replication to 1 and attach rds.logical_replication to the DB instance.
Update the parameter group to set rds.logical_replication to 1 if a custom parameter group is attached to a DB instance. The rds.logical_replication parameter is a static parameter that requires a DB instance reboot to take effect.
When the DB instance reboots, the wal_level parameter is set to logical.
Verify the values for wal_level and rds.logical_replication:
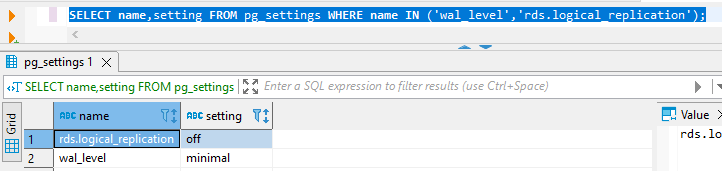
SELECT name,setting FROM pg_settings WHERE name IN ('wal_level','rds.logical_replication');
For turning logical replication on, follow the below steps:
Go to RDS Database > configuration
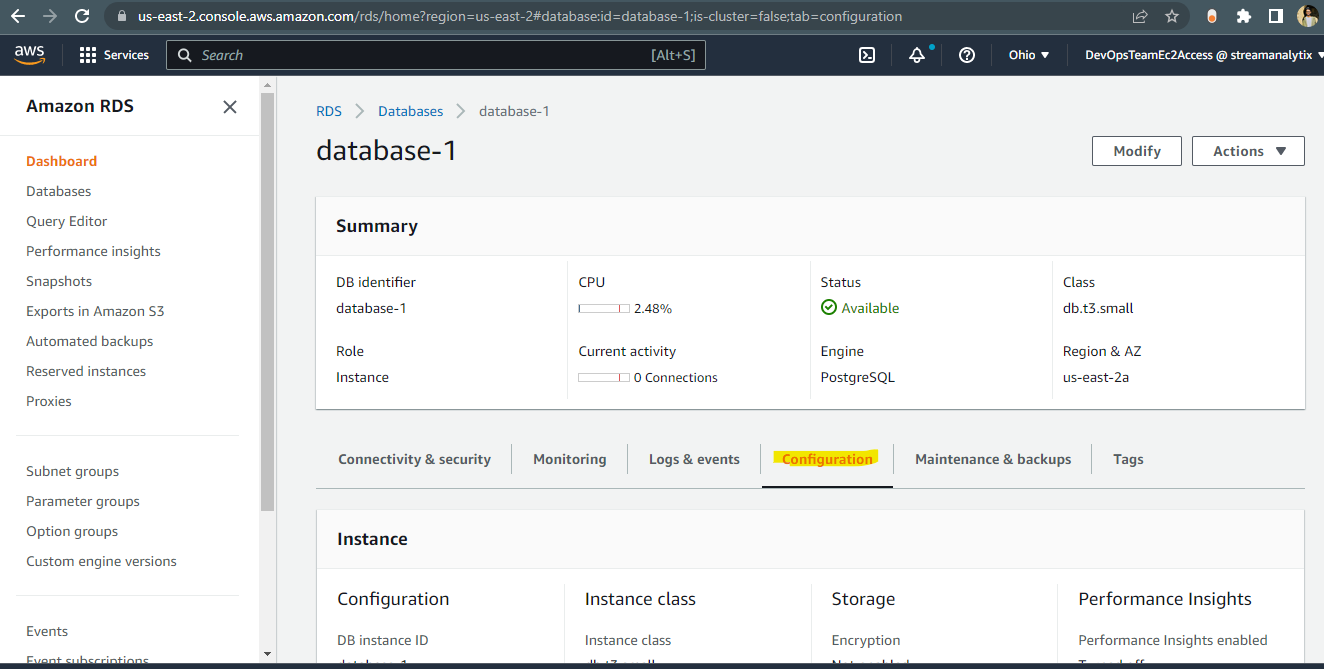
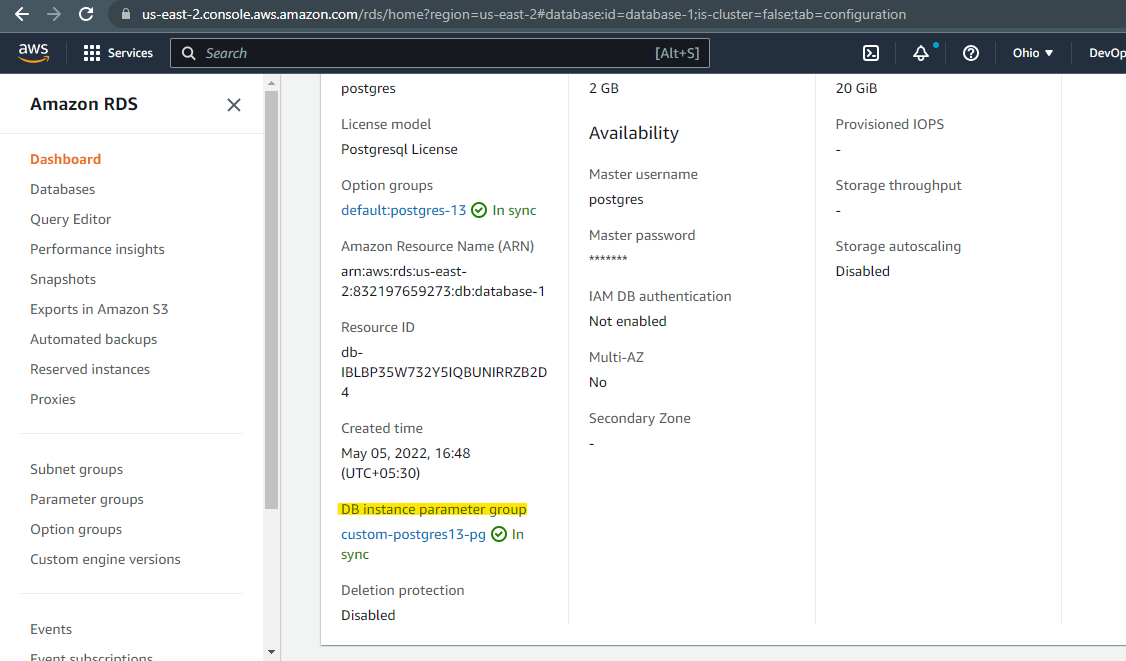
Check for DB instance parameter group and click on parameter group:
Now, search for the below properties and update by clicking on Edit parameters:
rds.logical_replication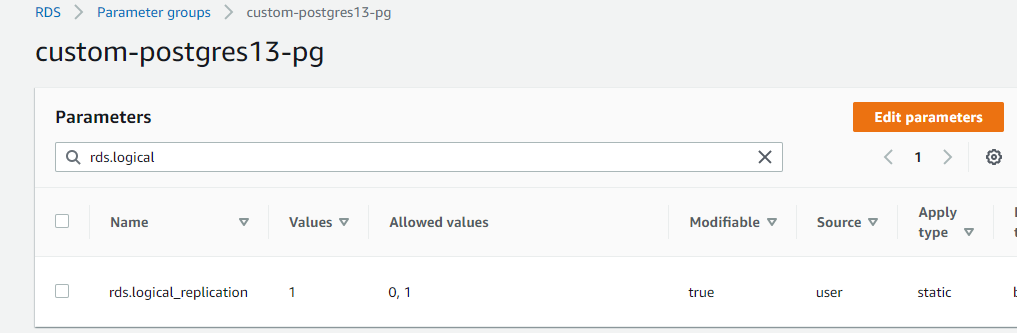
max_wal_senders
wal_sender_timeout
max_replication_slots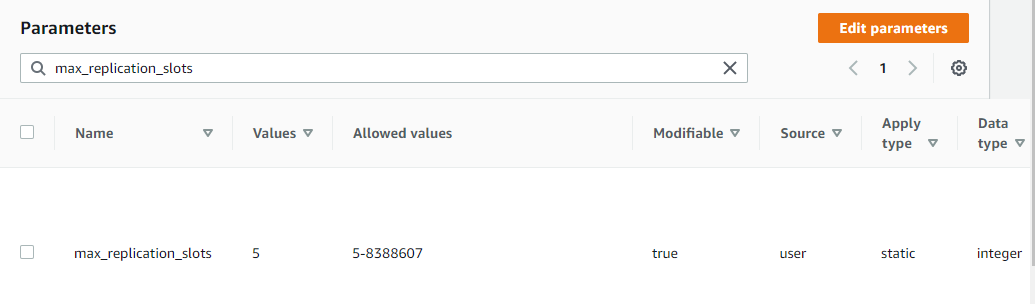
Now restart RDS Database and check parameter group should be in sync.
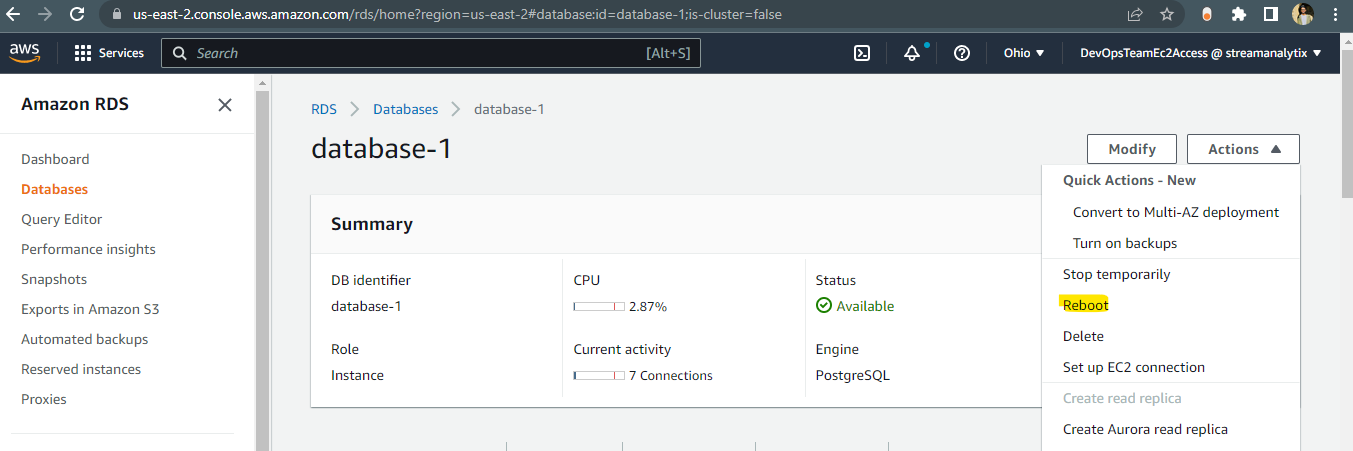
Login to RDS Postgres host from DBeaver/terminal and check the logical replication status:
SELECT name,setting FROM pg_settings WHERE name IN ('wal_level','rds.logical_replication');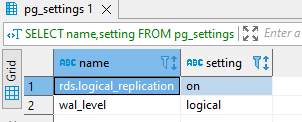
Check replication slot status:
SELECT * FROM pg_replication_slots;It is blank as no slot has taken over.
Now, go to Postgres DB and create one table with atleast one primary key:
CREATE TABLE rdsemployee (id int NOT NULL, name varchar(255) NOT NULL, age int, PRIMARY KEY (id)); INSERT INTO rdsemployee(id,name,age) values(1,'Anubhav',23);Now, login to Kafka machine and goto
$KAFKA_HOME/configand createrds_postgres_connect.propertiesfile:Update the below properties as per requirement:
plugin.name=pgoutput name=rdspostgres connector.class=io.debezium.connector.postgresql.PostgresConnector database.user=postgres database.history.kafka.bootstrap.servers=10.80.72.69:9092 database.history.kafka.topic=postgresrds table.whitelist=public.rdsemployee database.server.name=postgres database.port=5432 database.hostname=database-1.clbumsdjcznc.us-east-2.rds.amazonaws.com database.password=postgres database.dbname=postgres security.protocol=SSL producer.security.protocol=SSL consumer.security.protocol=SSL database.history.producer.security.protocol=SSL database.history.consumer.security.protocol=SSL ssl.truststore.location=/etc/ssl/certs/truststore.jks ssl.truststore.password=**** ssl.keystore.location=/etc/ssl/certs/keystore.jks ssl.keystore.password=**** ssl.key.password=****Now, Start connector with command:
nohup $KAFKA_HOME/bin/connect-standalone.sh config/connect-standalone.properties $KAFKA_HOME/config/rds_postgres_connect.properties &
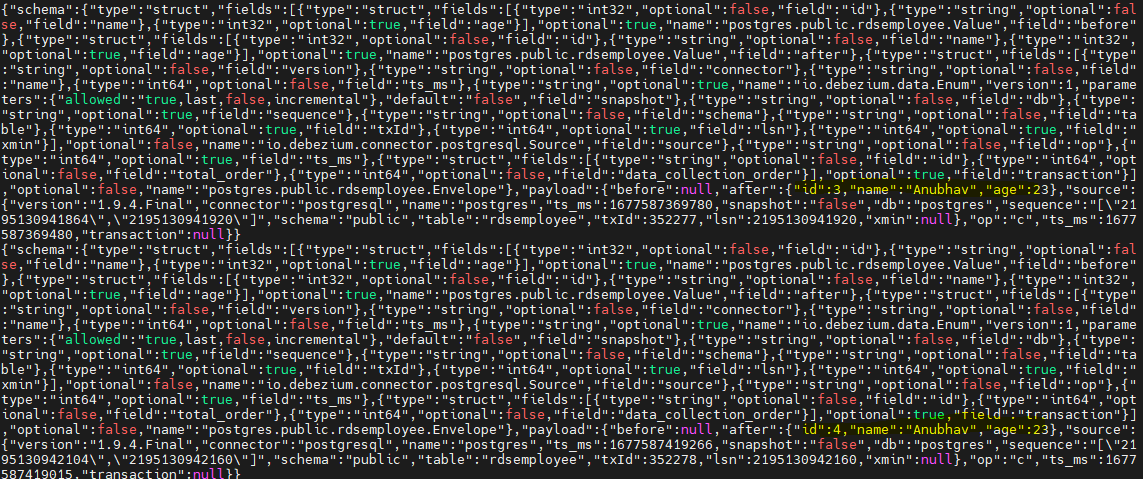
You can check the replication slot now, it will be occupied with the debezium slot.
SELECT * FROM pg_replication_slots;
# yum install VirtualBox-6.0 Please install the Linux kernel "header" files matching the current kernel for adding new hardware support to the system. The distribution packages containing the headers are probably: # /usr/lib/virtualbox/vboxdrv.sh setupSimply execute the following command to start it from the terminal or use the launcher from the menu to start.
# VirtualBoxIdentify the container database and the pluggable database in your environment.
Follow the below steps to configure the Logminer:
sqlplus sys/oracle@orcl12c as sysdba shutdown immediate; startup mount; alter database archivelog; alter database open; ALTER SESSION SET CONTAINER=ORCL; CREATE USER inventory IDENTIFIED BY oracle; GRANT CONNECT TO inventory; GRANT CONNECT, RESOURCE, DBA TO inventory; CREATE TABLE inventory.customers(id number(10),first\_name varchar2(20),last\_name varchar2(20),email varchar2(20),modified\_date time-stamp); ALTER SESSION SET CONTAINER=cdb$root; ALTER DATABASE ADD SUPPLEMENTAL LOG DATA; ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS; ALTER SYSTEM SWITCH LOGFILE; ALTER SYSTEM SET db\_recovery\_file\_dest\_size = 50G SCOPE=BOTH SID='\*'; CREATE USER c##cdc IDENTIFIED BY oracle CONTAINER=all; GRANT create session, alter session, set container, select any dictionary, log¬mining, execute\_catalog\_role TO c##cdc CONTAINER=all; ALTER SESSION SET CONTAINER=ORCL; GRANT select on inventory.customers TO c##cdc; ALTER SESSION SET CONTAINER=cdb$root; EXECUTE DBMS\_LOGMNR\_D.BUILD(OPTIONS=> DBMS\_LOGMNR\_D.STORE\_IN\_REDO\_LOGS); sqlplus sys/oracle@orcl as sysdba INSERT INTO inventory.customers VALUES (1,'NN','MM','nn@te',CURRENT\_TIME-STAMP); INSERT INTO inventory.customers VALUES (2,'NN','MM','nn@te',CURRENT\_TIME-STAMP); commit; DELETE FROM inventory.customers; commit;After completing the above steps, go to the Gathr UI and configure a new Oracle connection.
If you have any feedback on Gathr documentation, please email us!