Create Datasets
A dataset can be created while configuring a Data Source or Emitters within a data pipeline.
While configuring a Data Source, under Detect Schema, you will get an option to create a dataset. (as shown in image below)
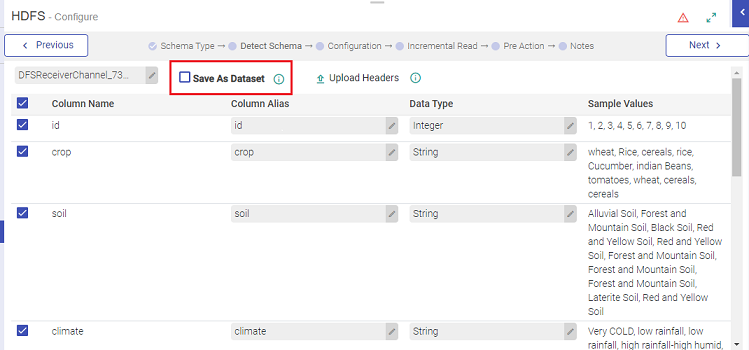
Select, Save As Dataset, and enter a unique name for the Dataset.
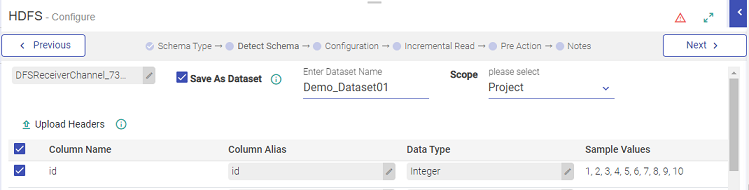
While configuring an Emitter, the option to save a dataset is under Configuration, as shown:
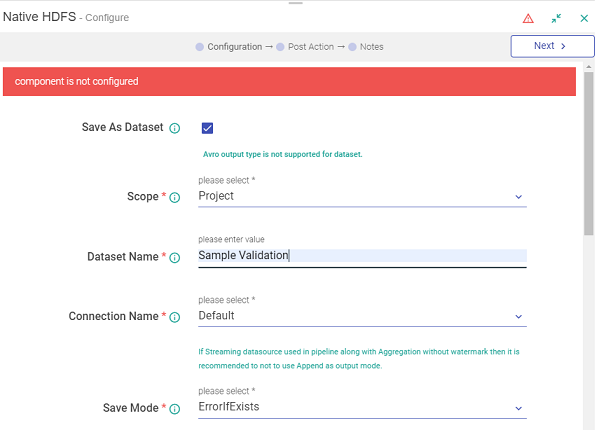
The name of the dataset has to be unique, else an error message is shown, “Dataset name already exists”.
For both Data Source and Emitter, the user has the option to override credentials for the connection field on the configuration tab.
If opted, the user will need to provide any other valid credential details for connection authentication.
Batch DFS Data Source and Batch DFS Emitter
Hive Data Source and Hive Emitter
JDBC Data Source and JDBC Emitter
S3 Data Source
Dataset Version and Disassociation
Whenever a dataset is created, a version is created. If you edit the components (that enabled dataset versioning), a new version is created. The only change you can make in a dataset is that you can edit the rules.
Also, Dataset Versions can be created based on schema and rule changes. The schema, rules and lineage are then listed version-wise.
The following changes will create a new version of a dataset:
Modifying the rules of a dataset will create a new version.
Changing the dataset schema at a pipeline emitter will create a new version. (The dataset is created from the emitter)
Changing the configuration of a dataset at a pipeline emitter will disassociate the dataset.
While you create a Dataset on an existing channel or edit the configuration of the above-mentioned components, the system prompts a relevant warning message before you accidentally overwrite an already created dataset:
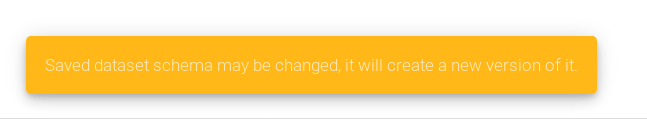
The final confirmation of Dataset creation is reflected in Green:

Once a new version is created, you can view the version list, under View Dataset > Summary. A sub-section opens in the same window with the version list and the Schema details.
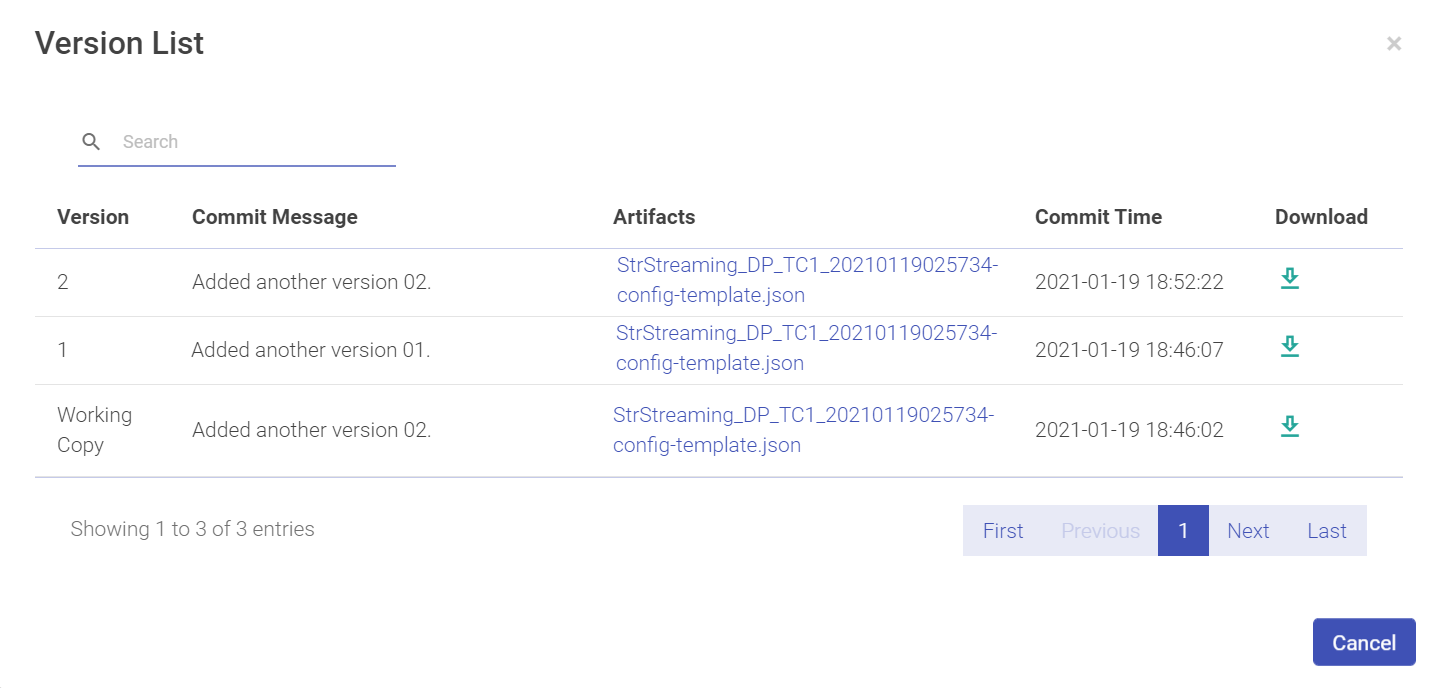
Schema Details consist of Alias and Datatype.
Alias is the name of the field and Datatype is the data type of the field value, as shown in the above screen shot.
- Dataset names should be unique all over the workspace.
External Dataset
A dataset is a combination of schema and a set of rules on the schema. You can create and reuse a dataset so that the pipeline runs with a pre-defined schema and a set of rules that are already configured in the dataset.
You can create a dataset externally from the Dataset option within a project.
An external dataset helps get insights into the data and analysis on each attribute of the dataset. This dataset can further be used in the desired pipelines.
Below are the steps to create and view datasets externally:
Create an External Dataset
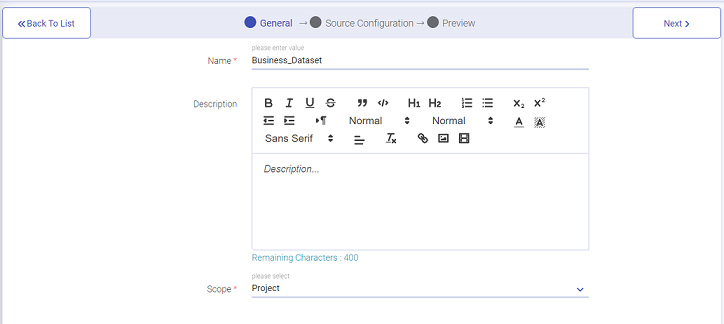
To create a new dataset, click the plus icon on the top right screen.

Enter the name of the dataset to be created under General, followed by the Description and click Next (as shown below).
- The dataset name has to be unique.
Source Configuration
You can create an external Dataset through the below mentioned data sources: HDFS, Hive, JDBC, S3, File System or SFTP, ADLS.
Create a Dataset through ADLS
Provide values for the following properties:
| Field | Description |
|---|---|
| Source | Option to select the source. Available options in the drop down list are: ADLS, BigQuery, File System, GCS, HDFS, Hive, JDBC, S3, SFTP. The source for which dataset is to be created, i.e., ADLS. |
| Connection Name | Connections are the service identifiers. Select the connection name from the available list of connections from where you would like to read the data. |
| Override Credentials | Select the override credentials option check-box for overriding the credentials. |
| Authentication Type | Azure ADLS authentication type. |
| Account Name | Provide a valid Azure ADLS account name. |
| Account Key | Provide a valid account key. You have an option to test the connection by clicking at the TEST CONNECTION button. |
| Container | ADLS data name from which the connection should be read. |
| ADLS Directory Path | Provide directory path for ADLS file system. |
| File Filter | Provide a file pattern. File filter is used to only include files with file names matching the pattern. For e.g *.pdf or *emp *.csv |
| Recursive File Lookup | Check the option to retrieve the files from current/sub-folder(s). |
| Type of Data | Data can be fetched in the form of CSV/TEXT/JSON/XML/Fixed Length, Avro, Binary, ORC and Parquet file. |
| Header Included | Check mark this option to include the header. |
Create a Dataset through HDFS
Enter values for the following properties.
| Field | Description |
|---|---|
| Source | Option to select the source. Available options in the drop down list are: ADLS, BigQuery, File System, GCS, HDFS, Hive, JDBC, S3, SFTP. The source for which dataset is to be created here is HDFS. |
| Connection Name | Connections are the service identifiers. Select the connection name from the available list of connections, from where you would like to read the data. |
| Override Credential | Option to override existing connection credentials. This option is unchecked by default. If check-marked, the user will need to provide any other valid credential details for the below mentioned fields through which the HDFS data source connection can be authenticated: Username, KeyTab Select Option and KeyTab File Path. Make sure to provide valid credentials if Override Credentials option is chosen. |
| HDFS File Path | HDFS path from where data is read. |
| File Filter | Provide a file pattern. File filter is used to only include files with file names matching the pattern. For e.g *.pdf or *emp *.csv |
| Recursive File Lookup | Check the option to retrieve the files from current/sub-folder(s). |
| Type of Data | Data can be fetched in the form of CSV/TEXT/JSON/XML/Fixed Length/Binary,Avro and Parquet file. |
Create a Dataset through Hive
Proceed with entering values for the below properties.
| Field | Description |
|---|---|
| Source | Option to select the source. Available options in the drop down list are: ADLS, BigQuery, File System, GCS, HDFS, Hive, JDBC, S3, SFTP. The source for which dataset is to be created, i.e., Hive. |
| Connection Name | Connections are the service identifiers. Select the connection name from the available list of connections, from where you would like to read the data. |
| Override Credential | Option to override existing connection credentials. This option is unchecked by default. If check-marked, the user will need to provide any other valid credential details for the below mentioned fields through which the Hive data source connection can be authenticated: Username, KeyTab Select Option and KeyTab File Path. Make sure to provide valid credentials if Override Credentials option is chosen. |
| Query | Write a Hive compatible SQL query to be executed in the component. |
| Refresh Table Metadata | If you want to refresh table metadata or sync updated dfs partition files with metastore. |
Create a Dataset through JDBC
Create a dataset through JDBC by selecting JDBC and below mentioned properties.
| Field | Description |
|---|---|
| Source | Option to select the source. Available options in the drop down list are: ADLS, BigQuery, File System, GCS, HDFS, Hive, JDBC, S3, SFTP. The source for which dataset is to be created, i.e., JDBC. |
| Connection Name | Connections are the service identifiers. Select the connection name from the available list of connections, from where you would like to read the data. |
| Override Credential | Option to override existing connection credentials. If check-marked, the user will need to provide any other valid credential details for the below mentioned fields through which the JDBC data source connection can be authenticated: Username and Password. Make sure to provide valid credentials if Override Credentials option is chosen. |
| Query | Write a JDBC compatible SQL query to be executed. |
| Enable Query Partitioning | Tables will be partitioned and loaded in RDDs if this check-box is checked. This enables parallel reading of data from the table. |
Create a Dataset through S3
To create a dataset through S3 Source.
| Field | Description |
|---|---|
| Source | Option to select the source. Available options in the drop down list are: ADLS, BigQuery, File System, GCS, HDFS, Hive, JDBC, S3, SFTP. The source for which dataset is to be created, i.e., S3. |
| Connection Name | Connections are the service identifiers. Select the connection name from the available list of connections, from where you would like to read the data. |
| Override Credential | Option to override existing connection credentials. If check-marked, the user will need to provide any other valid credential details for the below mentioned fields through which the S3 data source connection can be authenticated: AWS KeyId and Secret Access Key. Make sure to provide valid credentials if Override Credentials option is chosen. |
| S3 Protocol | Protocols available are S3, S3n, S3a |
| Bucket Name | Buckets are storage units used to store objects, which consists of data and meta-data that describes the data. |
| Path | File or directory path from where data is to be read. |
| File Filter | Provide a file pattern. File filter is used to only include files with file names matching the pattern. For e.g *.pdf or *emp *.csv |
| Recursive File Lookup | Check the option to retrieve the files from current/sub-folder(s). |
| Type of Data | Data can be fetched in the form of CSV/TEXT/JSON/XML/Fixed Length/Binary/Parquet/ORC, Avro file. |
| Is Header Included | Is header included in the CSV file. |
Create a Dataset through File System
Create a dataset through the File System option. Upload a file and select the Type of Data.
Create a Dataset through SFTP
Create a dataset through the SFTP option.
| Field | Description |
|---|---|
| Source | Option to select the source. Available options in the drop down list are: ADLS, BigQuery, File System, GCS, HDFS, Hive, JDBC, S3, SFTP. The source for which dataset is to be created, i.e., SFTP. |
| Connection Name | Connections are the service identifiers. Select the connection name from the available list of connections, from where you would like to read the data. |
| Override Credential | Select the override credentials option check-box for overriding the credentials. |
| Username | Provide the username that has access to the data. |
| Password | Provide the user password. |
| Select PEM Options | Specify PEM file path or upload a PEM file. |
| PEM File Location | If you specify the PEM file path then provide the PEM File Location. |
| PEM Password | Provide PEM password. |
| File Path | Provide the file path of SFTP file system. |
| Incremental Read | Select the checkbox to read data incrementally. Reads latest file incase of folder. |
| Parallelism | Number of parallel threads run to download file from SFTP. |
| Is Compressed | Select for file format * .zip, * .tar, * .tar.gz |
| File Filter | Provide a file pattern. File filter is used to only include files with file names matching the pattern. For e.g *.pdf or *emp *.csv |
| Recursive File Lookup | Check the option to retrieve the files from current/sub-folder(s). |
| Type of Data | Data can be fetched in the form of CSV/TEXT/JSON/XML/Fixed Length/Binary file. |
| Header Included? | Option available if CSV is selected as Type of Data. |
You can add further configurations as key-value pair by clicking at the ADD CONFIGURATION button. (Optional)
Create a Dataset through GCS
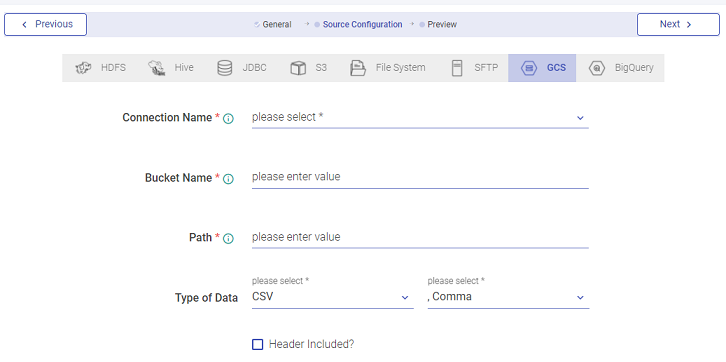
Create a dataset by selecting GCS Source:
| Field | Description |
|---|---|
| Source | Option to select the source. Available options in the drop down list are: ADLS, BigQuery, File System, GCS, HDFS, Hive, JDBC, S3, SFTP. The source for which dataset is to be created, i.e., GCS. |
| Connection Name | Connections are the service identifiers. Select the connection name from the available list of connections, from where you would like to read the data. |
| Override Credential | Select the override credentials option check-box for overriding the credentials. |
| Service Account Key File | Upload GCP service account key file. |
| Bucket Name | Provide Google storage bucket name. |
| Path | Select the meta data file. End path with * in case of directory. For example: outdir.* |
| File Filter | Provide a file pattern. File filter is used to only include files with file names matching the pattern. For e.g *.pdf or *emp *.csv |
| Recursive File Lookup | Check the option to retrieve the files from current/sub-folder(s). |
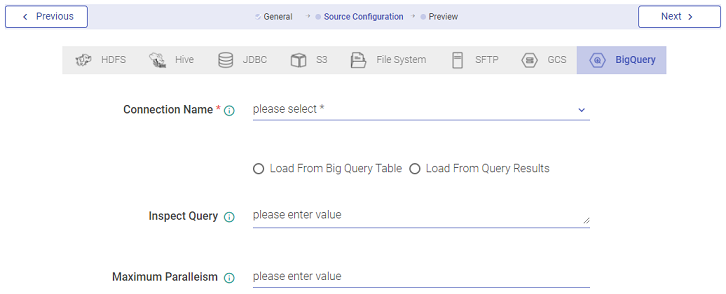
Create a Dataset through BigQuery
Detect Schema
After the source is configured, the data from the source is represented as a Schema. This process is called detect schema. The schema is then divided in Columns with Column Name, Column Alias, Data Type and Sample Values.
Column Alias and Data Type is editable at this page.
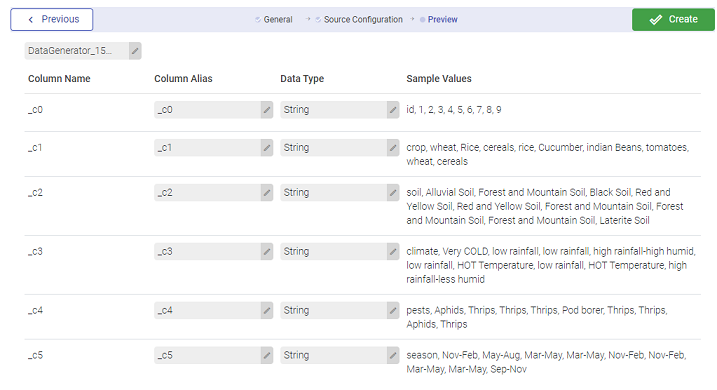
Once the schema is detected, you can click on Create from the top right corner of the UI, as shown in the image above. You will be notified that the Dataset has been successfully created.

As soon as you click on Create, you are navigated to the Data window under Explore (View Dataset page), where the schema is listed on the RULES window.
Rules
The Rules displayed under the DATA window show all the records of the dataset, as shown below.
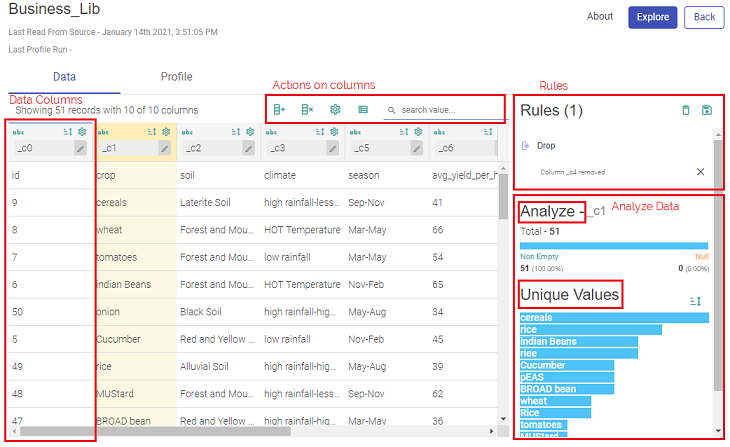
The above screen is divided into these sections:
Columns of Data
Actions on Columns
Rules
Analyze
Statistics
Unique Values
Let us go through each section in detail.
Columns
A column is divided into four parts. Every column has the following sections and you can sort the data by using the operations.
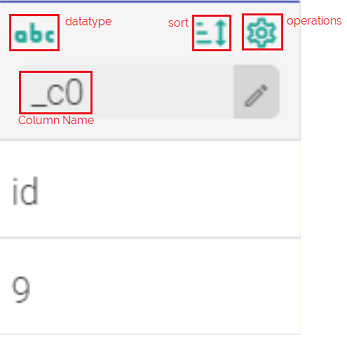
Data Type:
Supported data types are:
Date and Timestamp
Numeric
String
Boolean
For example, in the image shown above, the supported data type is denoted by abc for String data type.
Operations
This option is at the top right of the column. The gear icon, which opens a slide window with the following operations that can be performed on the respective column of the schema.
Whenever any operation is applied on a column (s), a set of Rules is created and reflected in the right section of Rules.
a. Filter the values
Filter the values based on either of the shown filters, such as Equals, defining a range in Range, and so on. The Custom filter can be used for a custom value.
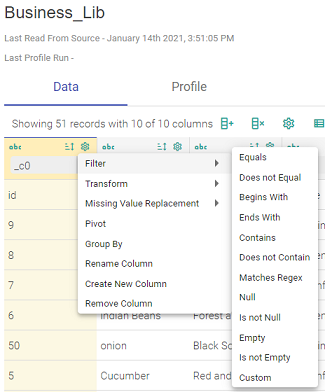
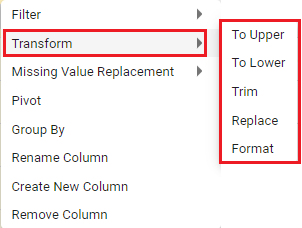
b. Transform
Transform filter can be applied to transform and filter the data based on Uppercase, Lowercase, Trim the values, and so on, as shown in the image below.
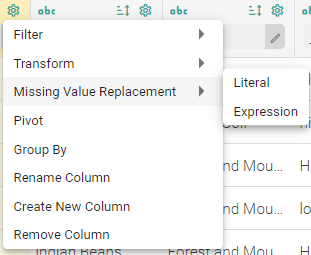
c. Missing Value Replacement:
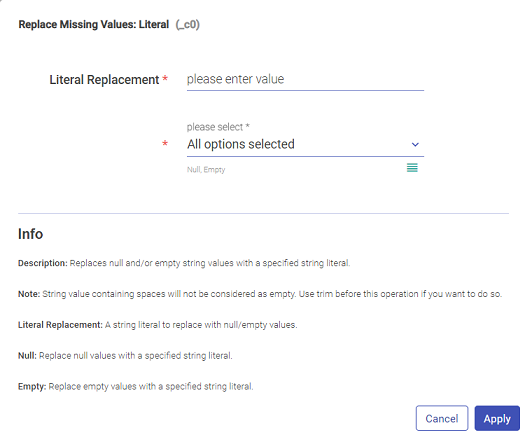
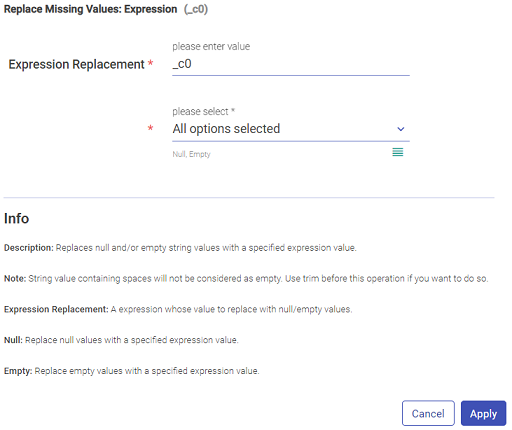
Replace the missing or null values with either the Literal or Expression value.
Literal: Replaces Null and/or empty string values with a specified string literal
Expression: Replaces Null and/or empty string values with a specified expression value.
d. Pivot
Pivot the columns, where PIVOT is a relational operator that converts data from row level to column level.
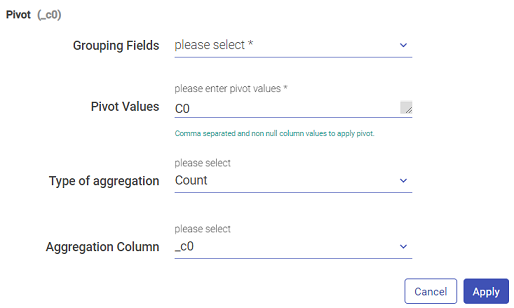
e. Group By
To group the columns together, this filter can be used.
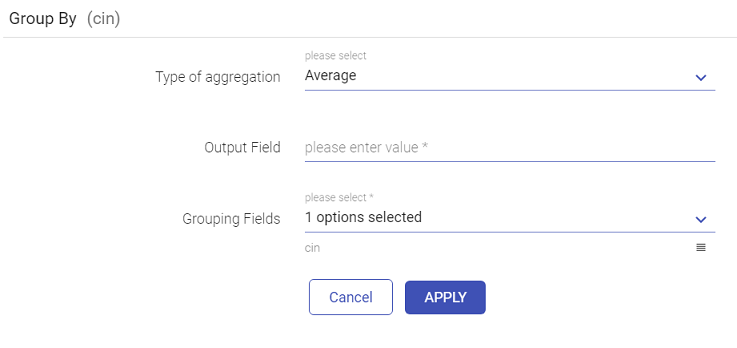
f. Rename Column
Rename the column name.
g. Create New Column
Create a new column using this filter.
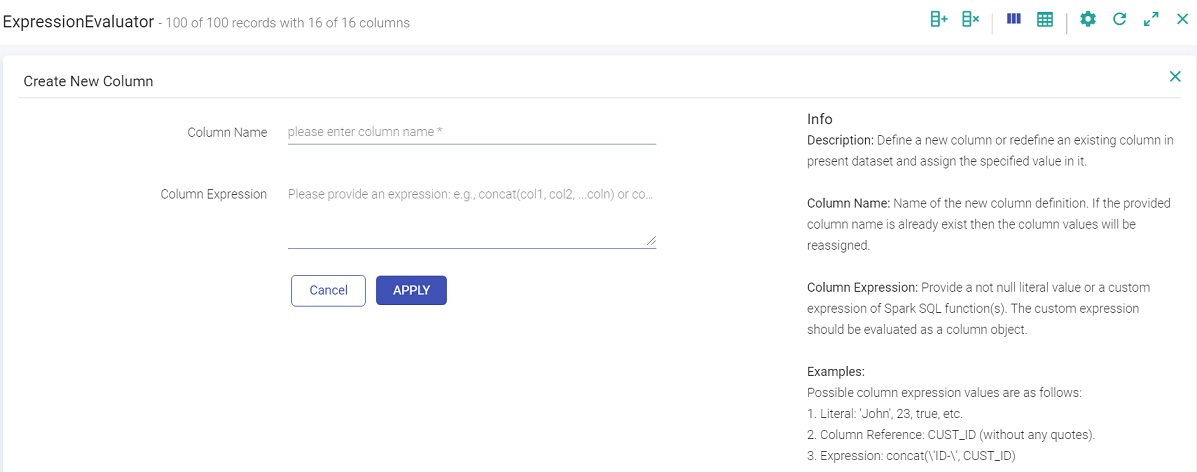
h. Remove Column
Remove the selected column.
Sort
Along with Filters, you can also sort the columns Alphabetically, from A to Z or Z to A.
Actions on Columns
The actions that can be performed on all the columns together are as follows:

Create Column: Create a column using this icon.
Keep/Remove Columns: Keep or remove a column in the schema.
Display Columns: Display the selected columns in the schema (Note that the hidden columns will be still a part of the schema, just not displayed.)
Toggle Rules: Toggle the list of the displayed rules.
Search Value: Search for a value in the schema.
Rules
Rules are conditions/actions applied on the columns to modify dataset as per the requirements. You can view the Rules applied in the right navigation panel.
The first time a dataset is created, the version of the dataset is version 0.
As soon as you create a rule and save the changes, the version keeps going n+1.
Once you have applied the changes in the rules, click on the Save icon in the Rules navigation bar to save the changes.
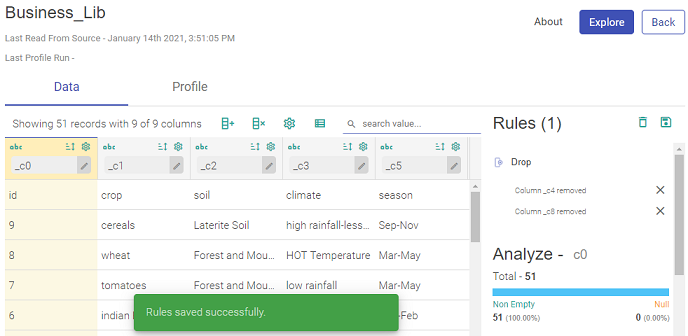
To edit an existing dataset, open the dataset and click the Explore button, you can configure new rules or reconfigure the existing rule.
For example, in the below image, you can see the two rules applied with two sub-sections: Analyze and Unique Values.
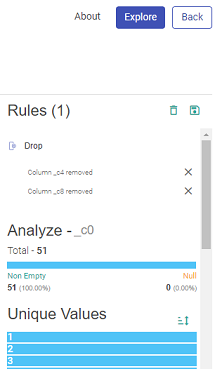
The two applied rules are:
Selling Price less than 5
Profit Percentage greater than 1
These rules can be deleted by clicking on the cross, next to each rule.
All the rules can be deleted by clicking on the Delete icon above Rules.
As per the rules applied to the Columns, the Analyze window and Unique Values window also change their values.
Under Analyze, you can view the Null values of the column on which the last rule was applied.
Under Statistics, you can view the mathematical statistic/value of the entire column in the form of:
Minimum
Maximum
Mean
Median
Standard Deviation
Mode
Distinct
Sum
Range
Under Unique Values, you will get the unique values in the column and when you hover your mouse on either bar, it will show the count of the unique value.
You can also sort the count in Descending, Ascending, or alphabetically.

After applying the changed rules, a new version of the Dataset will be created.
- The data from HDFS will be fetched in all cases by using Fetch From Source (hidden property).
If you have any feedback on Gathr documentation, please email us!