This topic presents the side navigation panel, referred as the main menu and its features that can be used to perform several administrative tasks in Gathr. The illustration of the main menu is given below and the tasks that can be performed with these features are explained further in detail.
Note: The main menu is only displayed for the Superusers (System Admin) login.
gathr provides multi-tenancy support through Workspaces.
Superuser can create multiple workspaces and add users to a workspace. One user can be mapped to multiple workspaces.
A superuser can create number of workspaces.
Below are the steps to create a workspace.
1. Go to Manage Workspace and click on Create New Workspace. (The plus sign on the top right corner)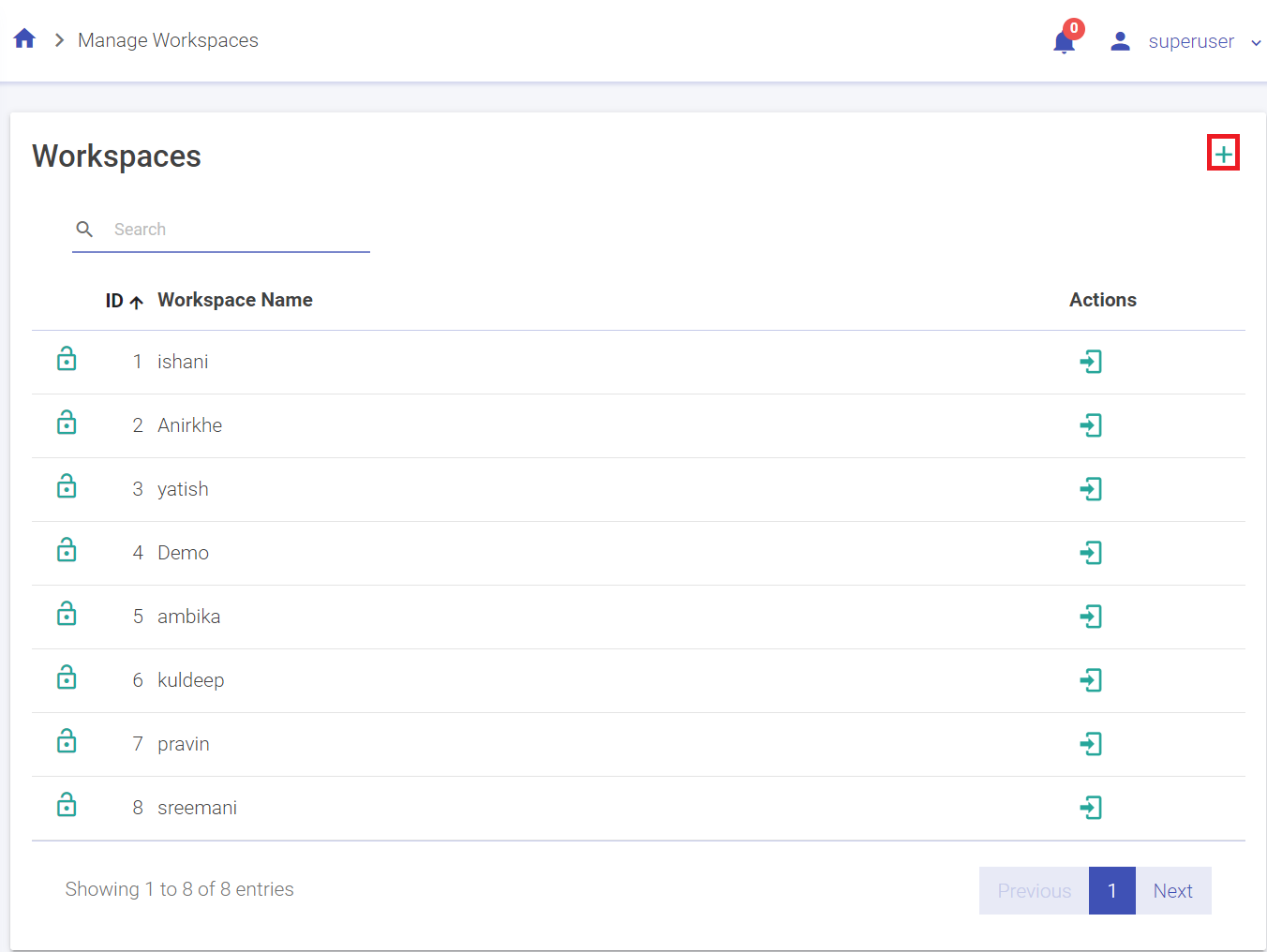
2. Enter the details in the following tab.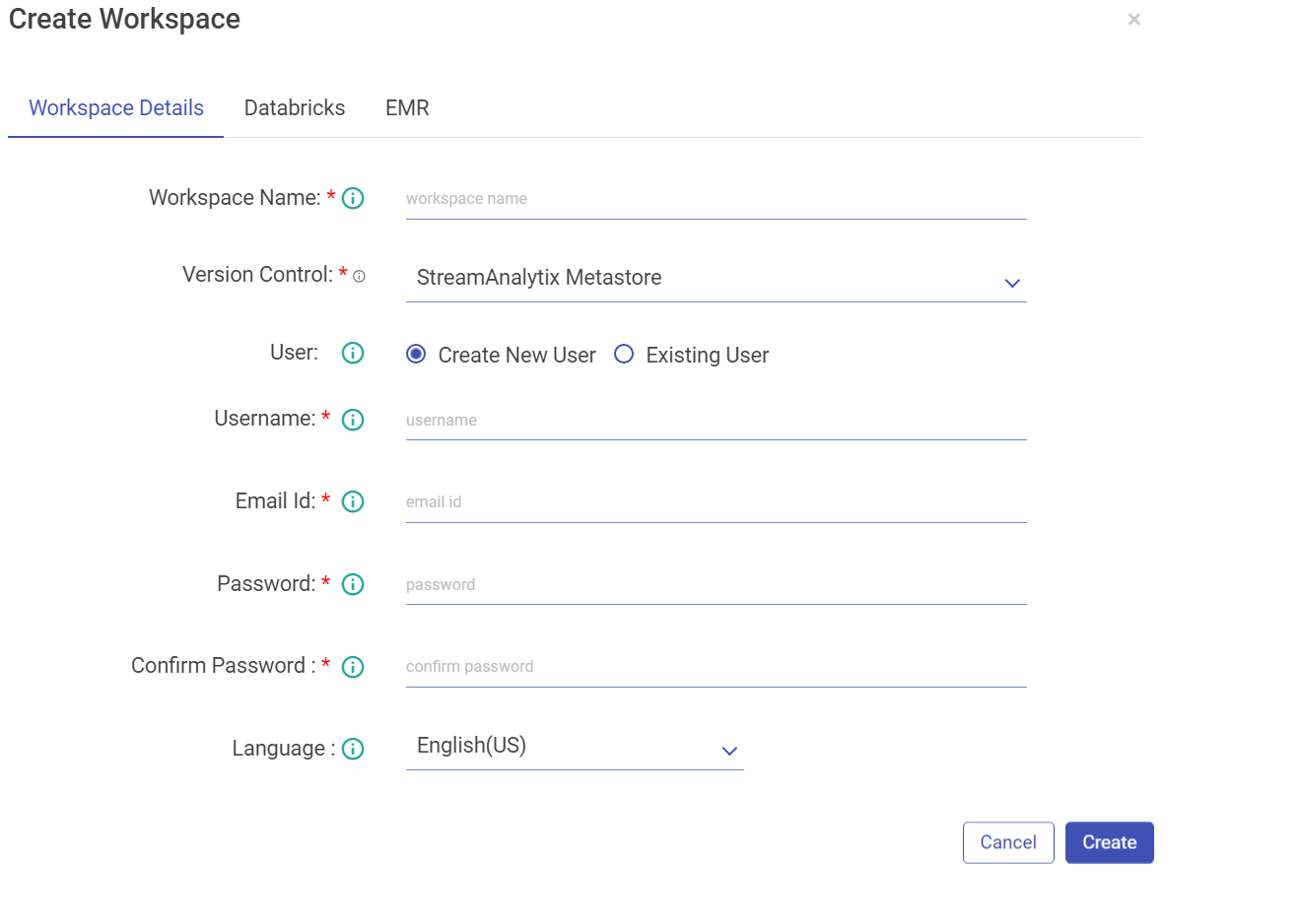
While creating the workspace, configure Databricks Token details and credentials.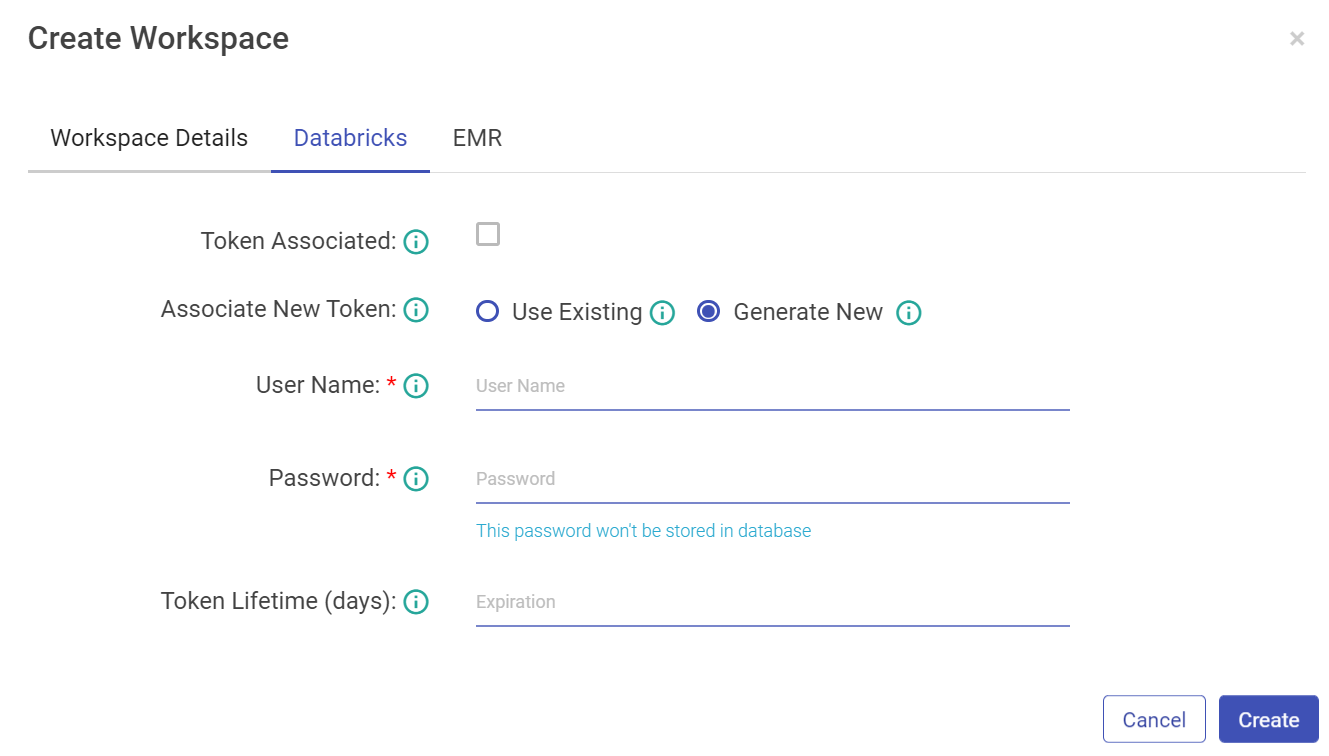
For EMR, you can configure using AWS keys or the Instance Profile.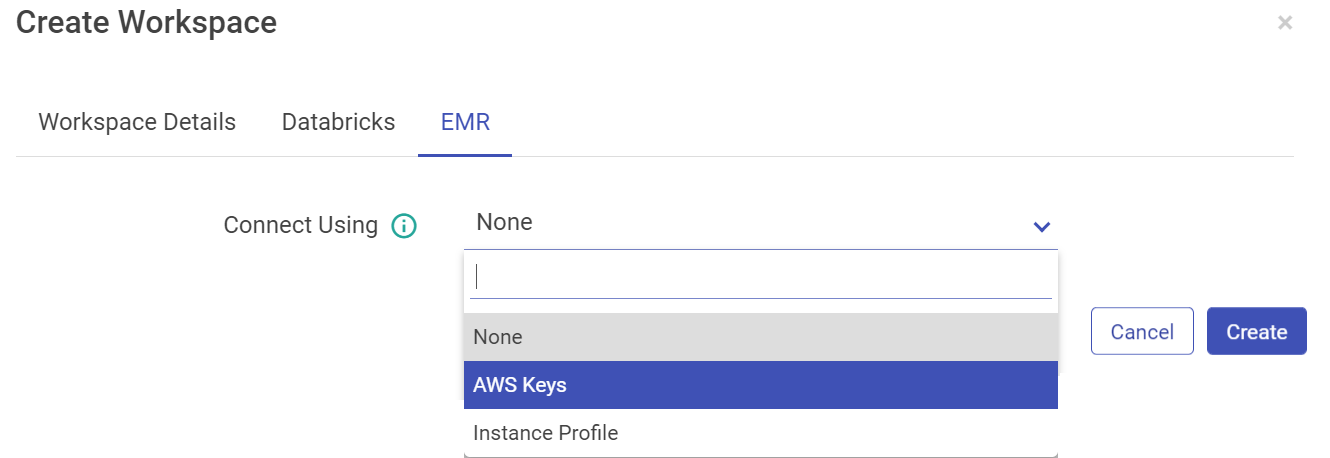
Configure with EMR cluster using AWS Keys: Select AWS Keys from the drop-down if you want to configure EMR cluster using AWS Key ID and Secret Access Key. AWS Key that will be used for all the communication with AWS.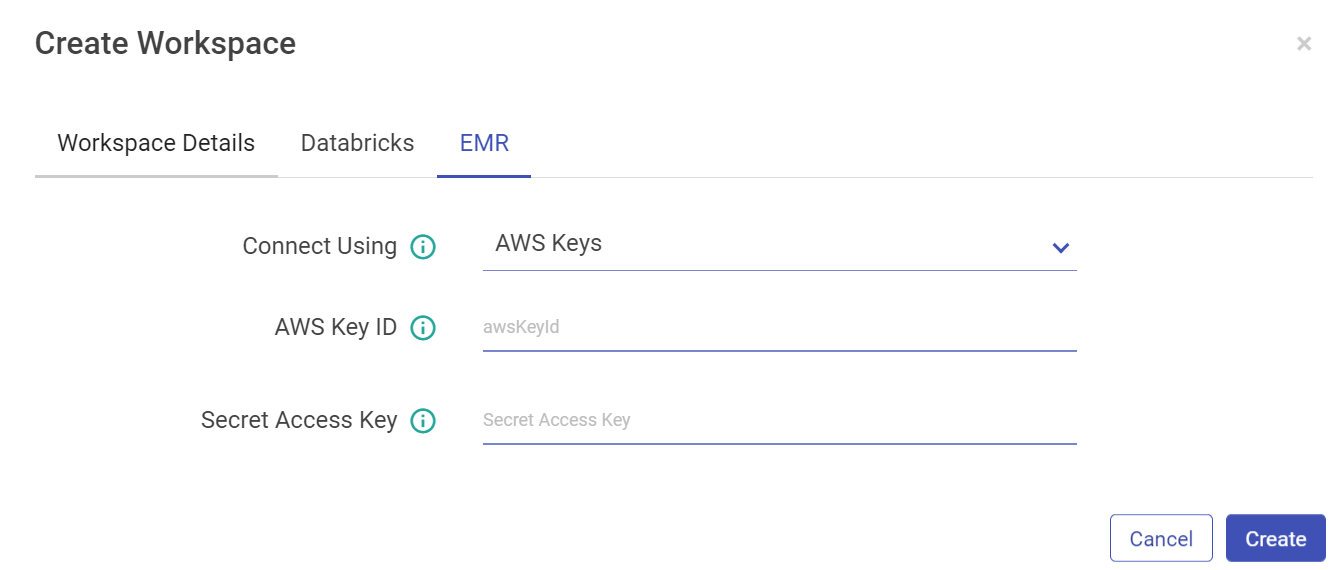
Configure with EMR cluster using Instance Profile option: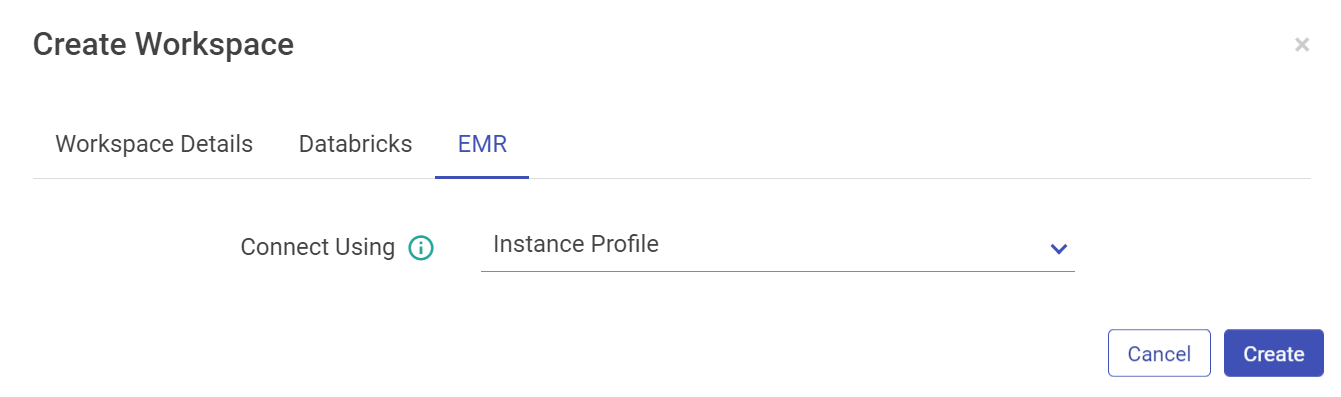
Note: Users creation is based on Databricks and EMR access as well. There may be users that won’t have access to create a Databricks users, for them the Databricks tabs will be not be accessible and so will be the case for EMR users.
3. Click Create to save the changes and the new Workspace will be listed in the Manage Workspaces page.
To enter a workspace, click on the enter icon.
Note: There is no provision to edit or delete a workspace.
Once the user enters into a Workspace, similar components will appear on the Workspace landing page as explained earlier in the Getting Started topic.
To know more about the Workspace menu, see Projects, Manage Workspace Connections and Manage Workspace Users.
To navigate to the Workspace Connections page, the user can click on the Connections feature which is available in the workspace menu.
The user can create new connections at the workspace level in the same manner as it is explained in the manage superuser connections topic.
- Unique names must be used to create new connections inside a Workspace for similar component types. User will get notified in the UI if the specified connection name already exists.
- The visibility of default connections and the connections created by Superuser at any Workspace level is controlled by the Superuser.
- The connections created in a Workspace can be differentiated by the Workspace name in the list. The superuser created connections will appear in the list with the Workspace name as Superuser.
- Connections listed in a workspace can be used to configure features like Datasets, Pipelines, Applications, Data Validations, Import Export Entities & Register Entities inside a Project. While using the connections for above listed features, the superuser connections can be differentiated from other workspace created connections by the workspace name.
- Connections will not be visible and cannot be consumed outside of the workspace in which they are created.
A developer user can be created for a Workspace.
A developer user can perform unrestrictive operations within a workspace, such as operations of a DevOps role along with pipeline creation, updating and deletion.
To create a new Workspace User, go to Manage Users and select Create New User.
Following are the properties for the same: Only a Developer user can be created from within the Workspace. Enter a username that will be used to log in the Application. Enter an email id that will be used for any communication with the user.
Also, there will be options to configure the AWS Databricks and EMR as explained earlier.
Click the workspace icon in the upper right corner of the page to view a drop-down list of the workspaces. Choose the workspace from the list you wish to enter.
NOTE: There is no provision to delete any workspace.
User can manage the AWS Databricks and EMR clusters with this option.
All the existing clusters for Databricks and EMR will be listed in the Cluster List View page.
User has options to create interactive clusters, perform actions like start, refresh, edit and delete clusters, view logs and redirect to spark UI.
Given below is an illustration of the Databricks Interactive Clusters page followed by the steps to create a cluster. 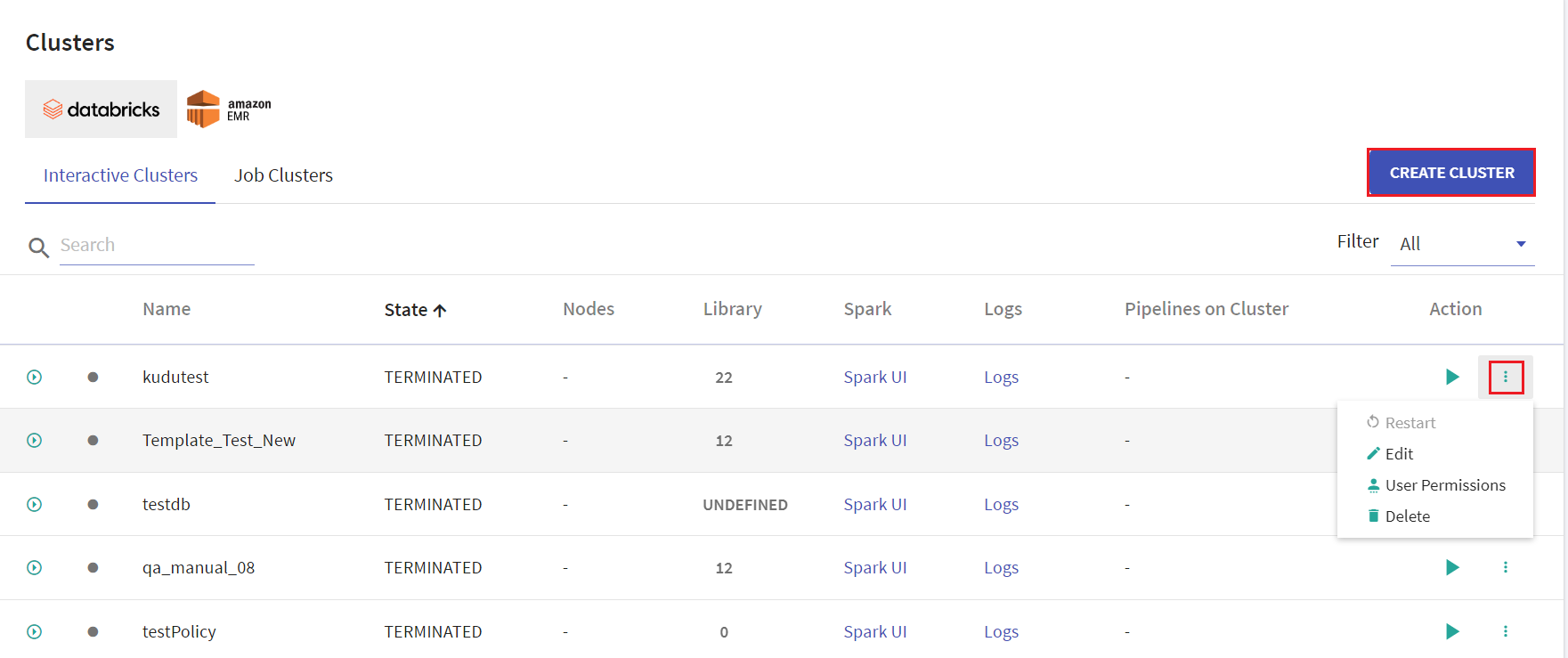
On the listing page under Action tab, user has options to start the cluster. Upon clicking the ellipses, under Action tab the available options are: Restart, Edit, User Permissions and Delete.
User has option to manage permissions of the existing Databricks clusters. Upon clicking User Permissions, the below screen will open: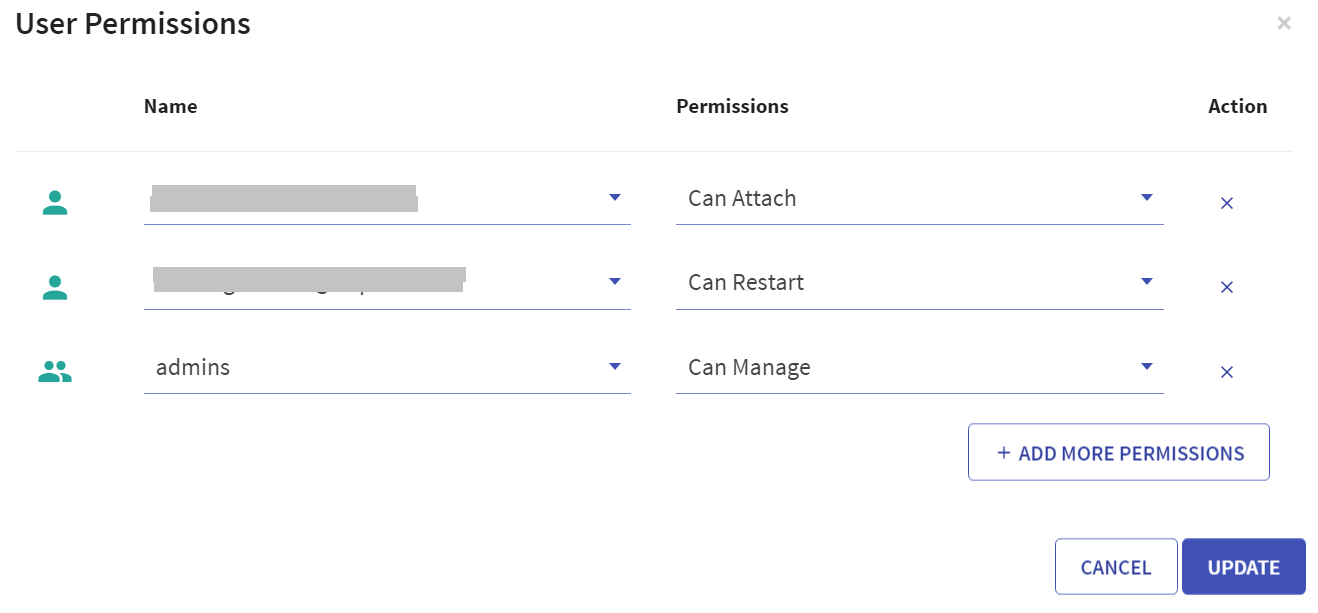
There are four permission levels for a cluster: No Permissions, Can Attach To, Can Restart, and Can Manage thereby enabling the cluster to be accessed by a set of users with specific permissions.
Note: User must comply with the below mentioned prerequisites for User Permissions in Databricks account:
- Admin to enable below mentioned toggles for the workspace in its settings:
- Under Access Control, 'Control Jobs, and pools Access Control' toggle must be enabled.
- Under Access Control, 'Cluster Visibility Control' option must be enabled to allow listing of only those clusters to the user for which it has any permission.
- Access control is available only in the Premium plan.
On the listing page, click CREATE CLUSTER to create Databricks cluster. Provide the below fields:
Databricks Interactive Clusters
Given below is an illustration of the Databricks Interactive Clusters page followed by the steps to create a cluster. 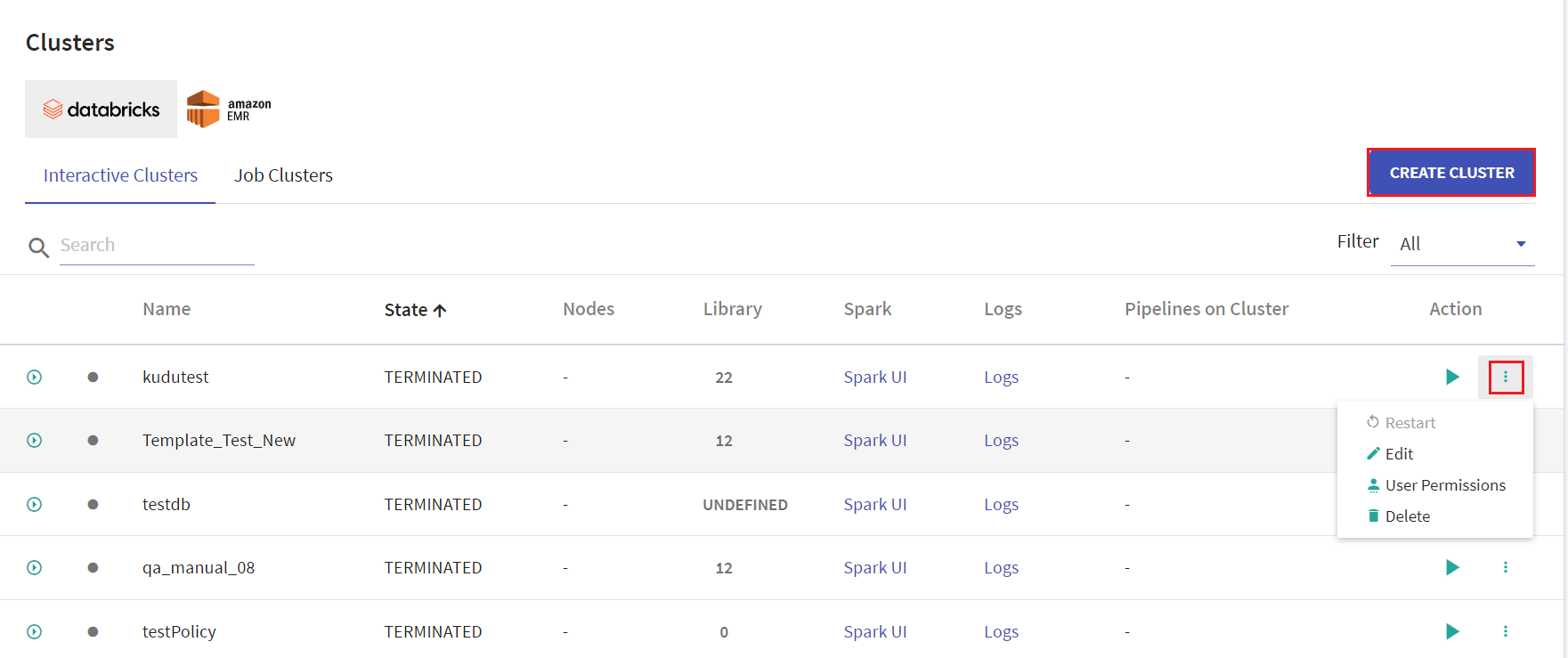
Click CREATE CLUSTER to create Databricks cluster. Provide the below fields:
Given below is an illustration of the Databricks Job Clusters page.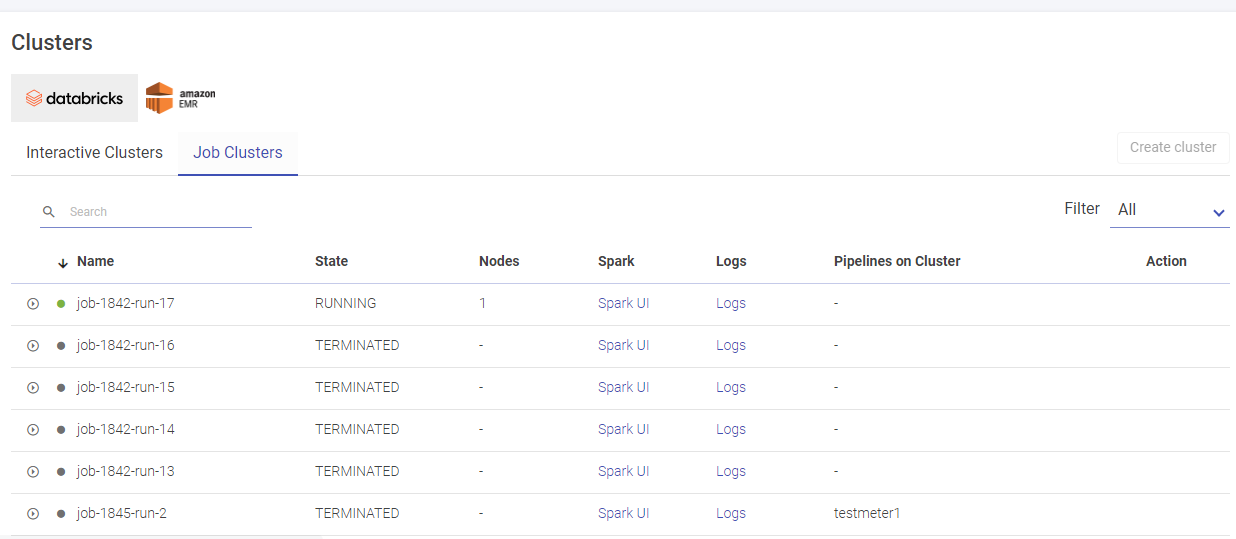
User has options to create long running clusters, fetch clusters from AWS, perform actions like start, edit and delete clusters, view logs and redirect to spark UI.
Given below is an illustration of the EMR Long Running Clusters page.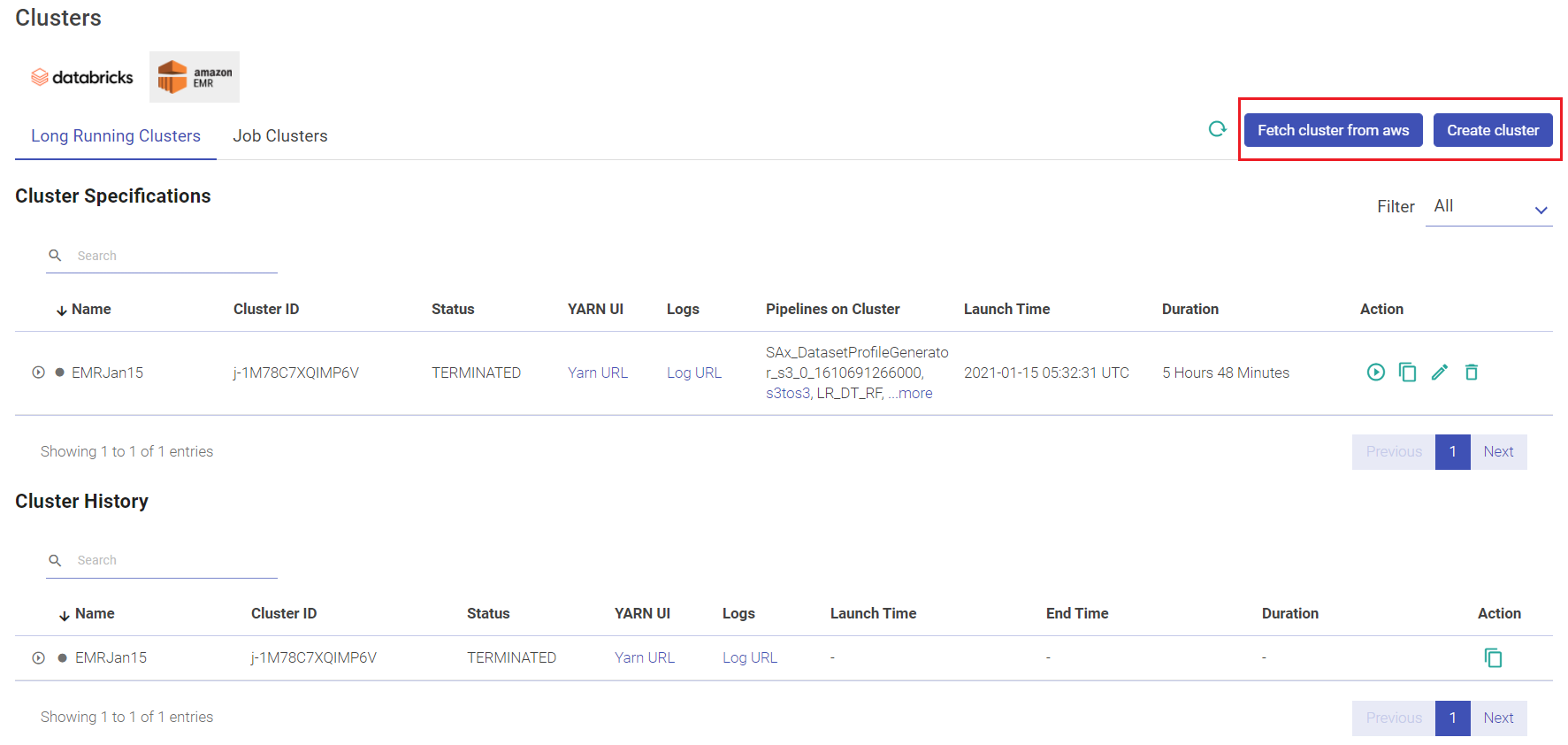
Given below is an illustration of the EMR Job Clusters page.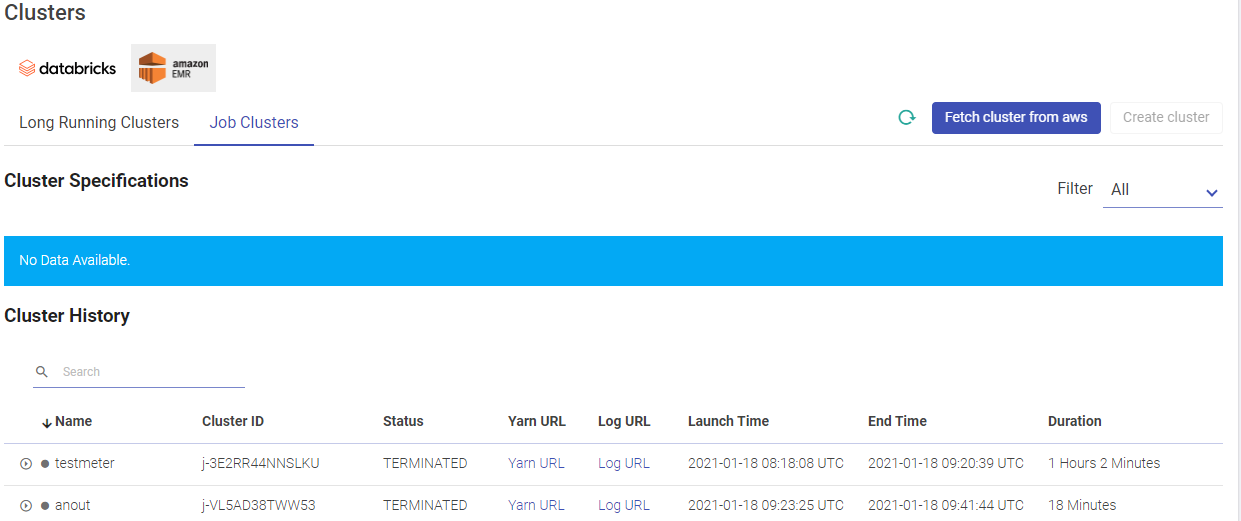
Click CREATE CLUSTER to create a fresh cluster. Provide the below fields for creating a new cluster.
Click FETCH CLUSTER FROM AWS option to fetch an existing cluster by selecting the cluster ID from the drop-down list.
To navigate to the Workspace Connections page, the user can click on the Connections feature which is available in the workspace menu.
The users with privilege to create connections can create new connections at the workspace level.
- Unique names must be used to create new connections inside a Workspace for similar component types. User will get notified in the UI if the specified connection name already exists.
- The visibility of default connections and the connections created by Superuser at any Workspace level is controlled by the Superuser.
- The connections created in a Workspace can be differentiated by the Workspace and Owner name in the list. The superuser created connections will appear in the list with the Workspace and Owner name as Superuser.
- Connections listed in a workspace can be used to configure features like Datasets, Pipelines, Applications, Data Validations, Import Export Entities & Register Entities inside a Project. While using the connections for above listed features, the superuser connections can be differentiated from other workspace created connections by a suffix, “global” which is given after the connection name.
- Connections will not be visible and cannot be consumed outside of the workspace in which they are created.
This option will only be visible if the containerEnabled property is enabled in the Sandbox configuration settings.
The user can register a desired cluster by utilizing the Register Cluster option. It can be done either by uploading a valid embedded certificate within a config file, or by uploading config file and certificates separately during registration process. The cluster once registered can be utilized across all workspaces while configuring a sandbox.
Currently, only Kubernetes clusters can be registered on Gathr.
On the Cluster Configuration listing page the existing clusters will be listed. Timestamp information about the cluster since the time it is up. The user can Edit/Unregister the registered cluster(s) information.
The user can register a cluster by clicking at the top right + icon.
Configure the cluster by providing the following details:
The user can TEST the cluster configuration and SAVE.
Upon successful registration, the registered cluster will get added in the listing page.
The option to register Container Images within Gathr are provided in the main menu as well as the workspace menu. It will only be visible if the containerEnabled property is enabled in the Sandbox configuration settings.
When user registers a container image, it will be visible as drop-down options in the sandbox configuration page inside project. These container images (sandbox) can be launched on the preferred container (for example, Kubernetes) to access the desired integrated development environments (Examples: Jupyter Lab, Visual Studio Code, Custom and Default) of the user’s choice on the sandbox.
Default IDE option will only be visible when the Register Container Image option is accessed by superuser via the main menu.
The container images that are registered from the main menu by the superuser can be utilized across all workspaces. Whereas, the container images that are registered from the workspace menu remain private to the specific workspace where it is registered.
Registered Container Images Listing
The container images that are registered will appear on the Registered Images page.
The information and actions displayed for the listed Container Images are explained below:
URI registered on container registry and accessible to the cluster. The user can Edit/Unregister the registered container image(s).
Steps to Register Container Image
The user can register a container image by clicking at the top right + icon.
Configure the container image by providing the following details:
Consider the below points for YAML file upload:
• Upload file with .zip extension.
• It should directly contain the valid YAML files.
• Use below expressions to populate YAML fields at runtime during sandbox configuration:
"@{<kind>:<field path>}" - The expression used to refer the specified field from any other YAML file.
Example: In "@{deployment:metadata.name}" expression, the first part "deployment" is kind (i.e., type of YAML) and the next part "metadata.name" is the field that is supposed to be fetched from the specified YAML type.
${value:"<default-value>",label:"<field label>"} - The expression used to display a dynamic field label along with a default value, which is editable.
${value:"sandbox-<<UUID>>",label:"Enter Sandbox Name"}
Field label will be: Enter Sandbox Name and default value will be: sandbox-A123.
"<<UUID>>" - This expression is used to generate a unique ID for a specific field.
In the above YAML configuration snippet, the BASE_PATH will always have a unique value generated via the "/<<UUID>>" expression.
Click REGISTER to complete the process. The registered image will appear in the listing page.
SETUP section is defined in Installation Guide. This section defines the properties of- Cluster Configuration, gathr settings, Database, Messaging Queue, Elasticsearch, Cassandra and Version Control.
Under SETUP, the user has an option to manage Version Control.
Configuration page enables configuration of gathr properties.
Note: Some of the properties reflected are not feasible with Multi-Cloud version of gathr. These properties are marked with **
Each sub-category contains configuration in key-value pairs. You can update multiple property values in single shot.
Update the values that you want then scroll down to bottom and click on Save button.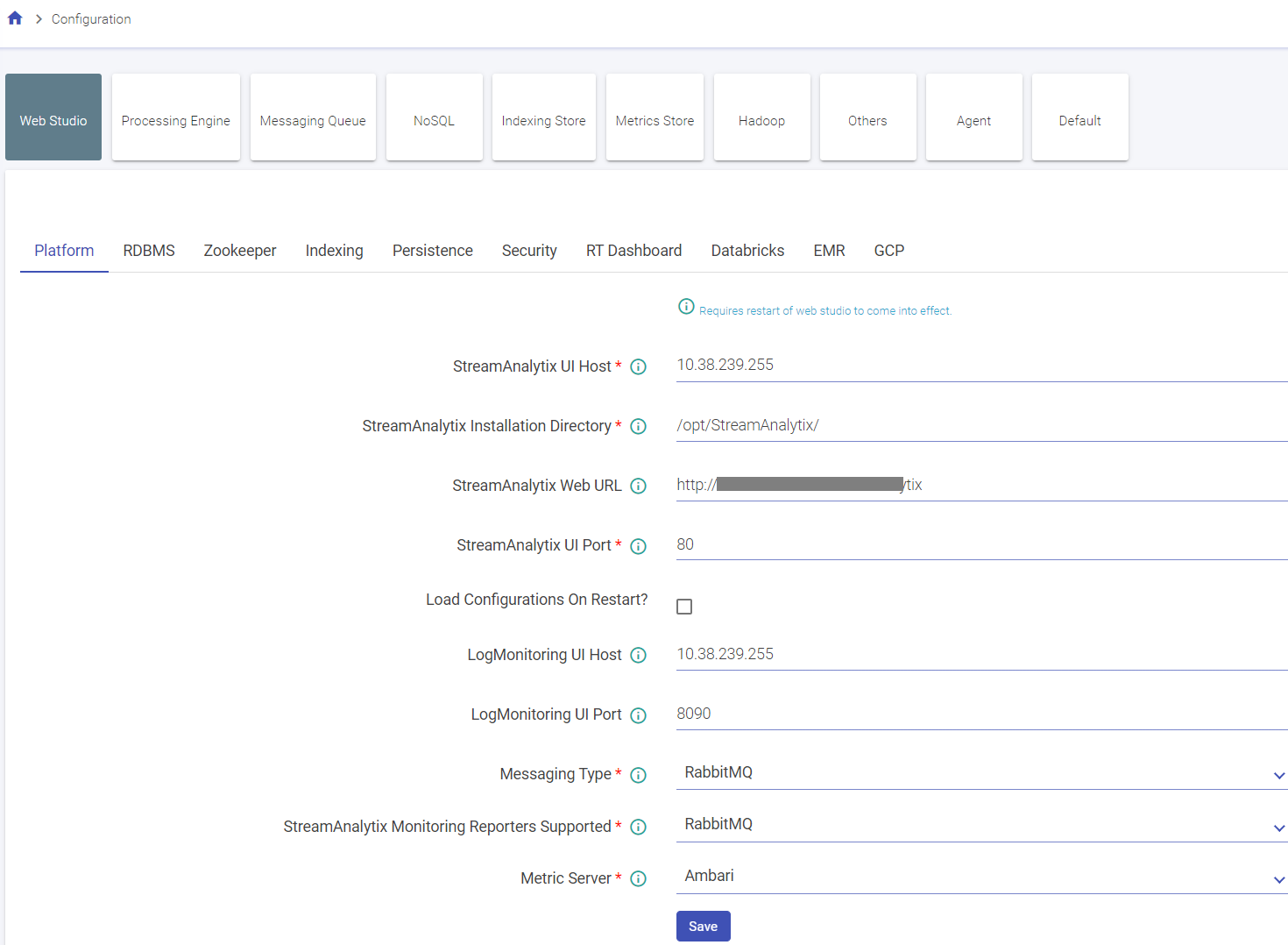
You will be notified with a successful update message.
Performs search operation to find property key or property value. You can search by using partial words of key labels, key names or key values.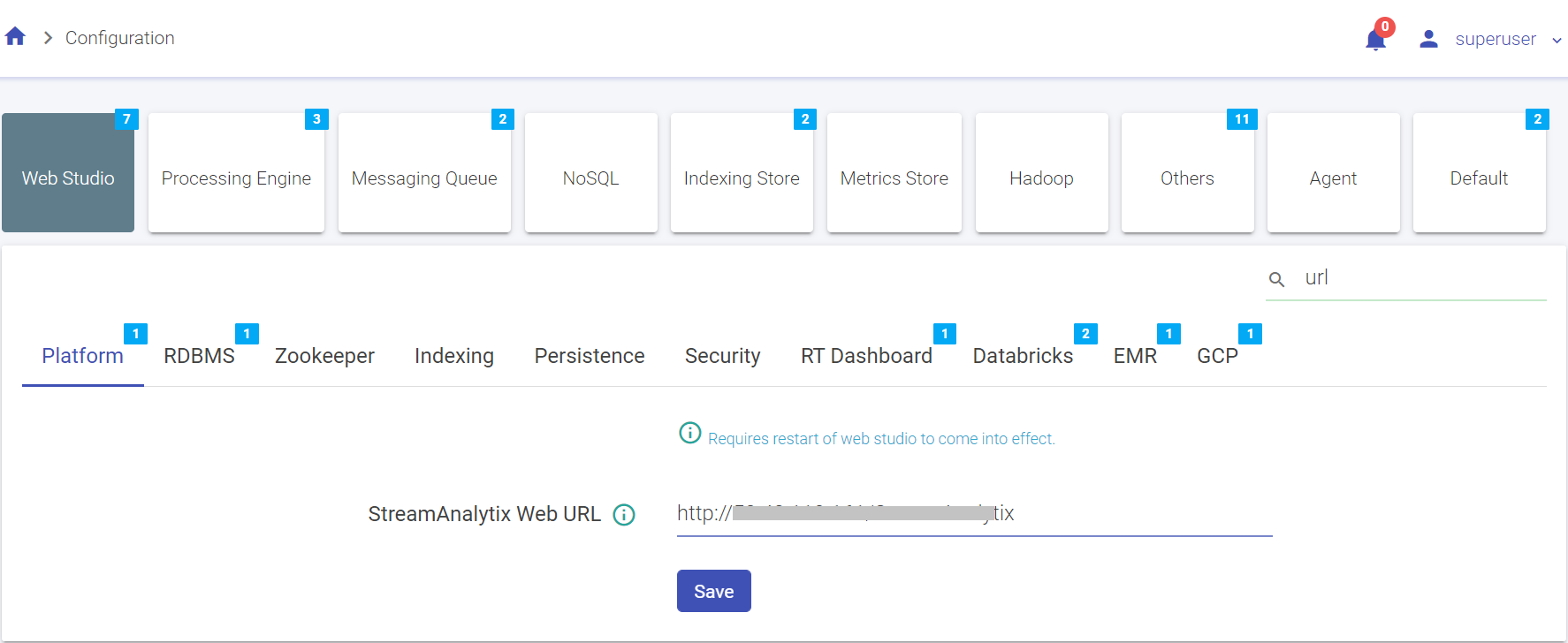
The above figure shows, matching configuration values and count for the searched keyword “url”.
By hovering the mouse on a property label, a box will show the fully qualified name of the key and click on the i button for its description.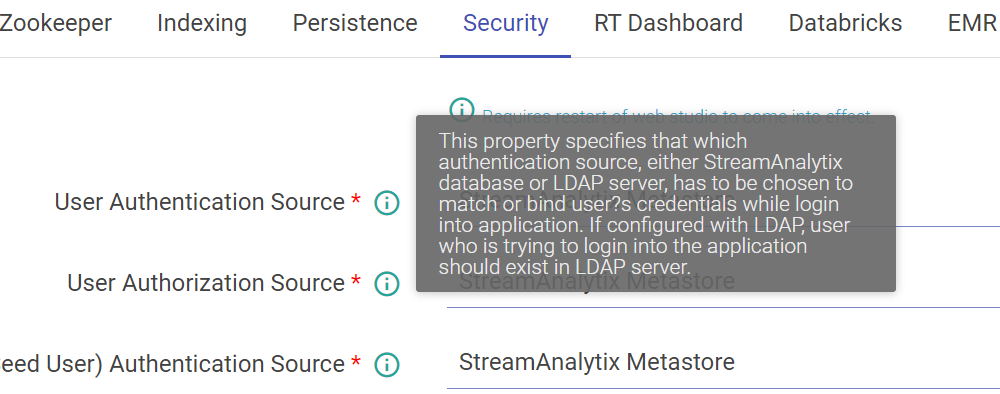
The above figure shows, matching configuration values and count for the searched keyword “url”.
Copy the fully qualified name of property key by clicking on key’s label as shown below.
The key name will be copied to clipboard.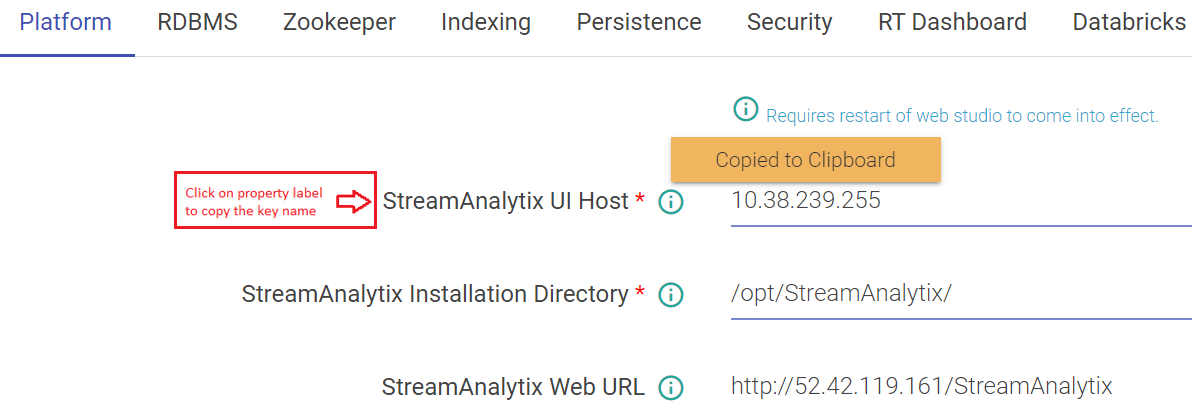
gathr configuration settings are divided into various categories and sub-categories according to the component and technology.
Configurations properties related to application server, i.e. gathr web studio. This category is further divided into various sub-categories.
The type of database on which gathr database is created. Possible values are MySQL, PostgreSQL, Oracle.
The comma separated list of <IP>:<PORT> of all nodes in zookeeper cluster where configuration will be stored.
Search without specifying column names, takes extra space and time. Indexed data older than mentioned time in seconds from current time will not be fetched.
Security
Configurations properties related to application processing engines come under this category. This category is further divided into two sub-categories.
Configurations properties related to messaging brokers come under this category. This category is further divided into three sub-categories.
Configuration properties related to NoSQL databases come under this category. This category is further divided into two sub-categories:
Configurations properties related to search engines come under this category. This category is further divided into two sub-categories:
Configuration properties related to metric servers come under this category. This category is further divided into various sub-categories.
Configuration properties related to Hadoop, i.e. gathr web studio, come under this category. This category is further divided into various sub-categories.
The file system URI. For e.g. - hdfs://hostname:port, hdfs://nameservice, file://, maprfs://clustername The name of user through which the hadoop service is running.
Miscellaneous configurations properties left of the Web Studio. This category is further divided into various sub-categories.
You can add extra Java options for any Spark Superuser pipeline in following way:
Login as Superuser and click on Data Pipeline and edit any pipeline.
Once Kerberos is enabled, go to Superuser UI > Configuration > Environment > Kerberos to configure Kerberos.
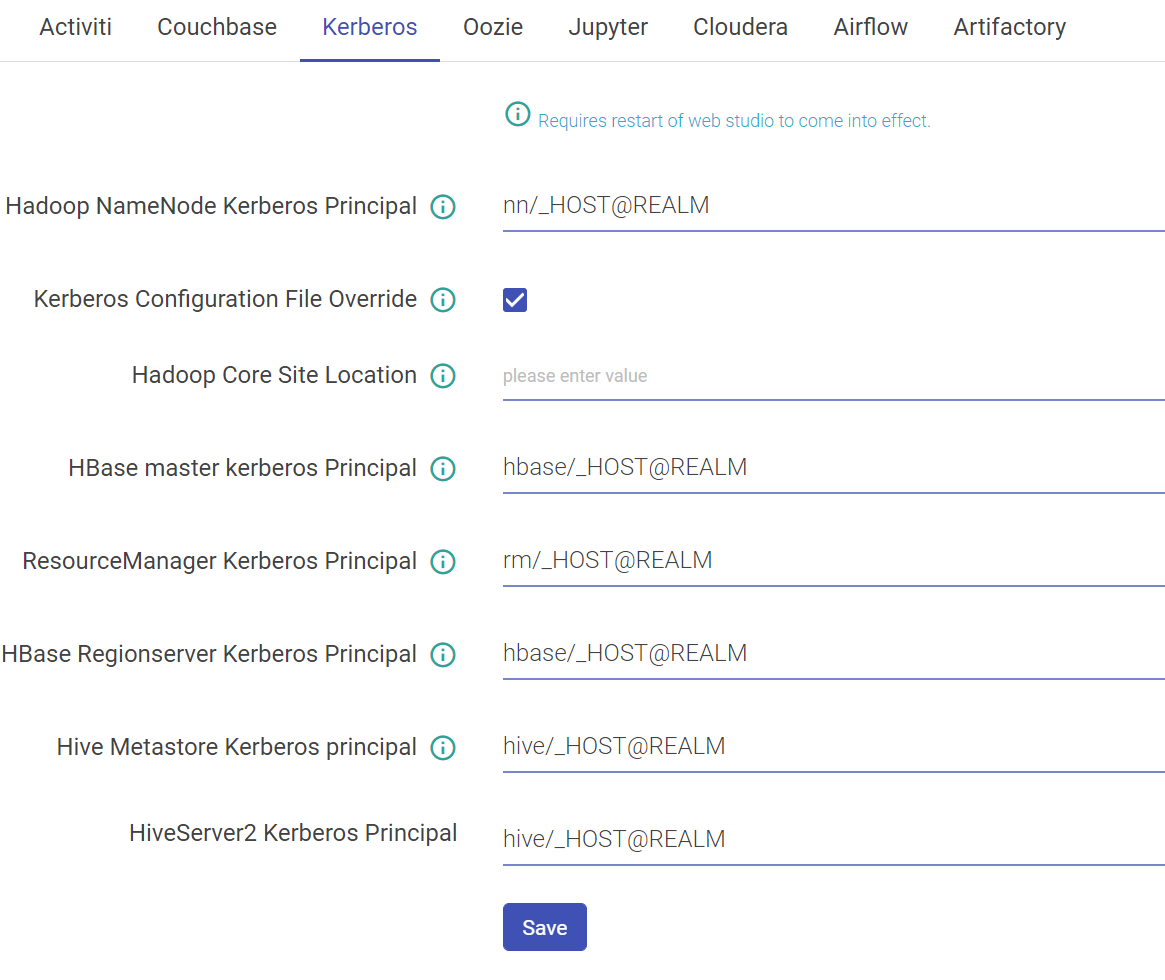
Configure Kerberos in Components
Go to Superuser UI > Connections, edit the component connection settings as explained below:
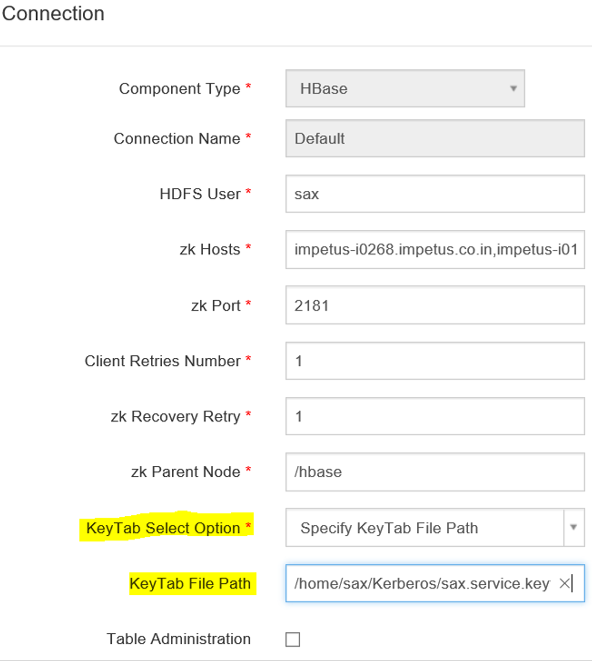
By default, Kerberos security is configured for these components: Solr, Kafka and Zookeeper. No manual configuration required.
Note: For Solr, Kafka and Zookeeper, Security is configured by providing principals and keytab paths in keytab_login.conf. This file then needs to be placed in StreamAnalytix/conf/common/kerberos and StreamAnalytix/conf/thirdpartylib folders.
Jupyter HDFS connection name use to connect HDFS (from gathr connection tab). URL contains IP address and port where Jupyter services are running.
Airflow
All default or shared kind of configurations properties come under this category. This category is further divided into various sub-categories.
Spark
Defines maximum number of retries for the RabbitMQ connection. Defines the RabbitMQ exchange name for real time alert data.
The URL of FTP service to create the FTP directory for logged in user (required only for cloud trial).
Audit
Others
Connections allow gathr to connect to services like ElasticSearch, JDBC, Kafka, RabbitMQ and many more. A user can create connections to various services and store them in gathr application. These connections can then be used while configuring the services in various features of gathr which require these services connection details, for e.g., Data Pipelines, Dataset, Application.
To navigate to the Superuser Connections page, the user can click on the Connections feature which is available in the gathr main menu.
The default connections are available out-of-box once you install the application. All the default connections expect RabbitMQ are editable.
The user can use these connections or create new connections.
A superuser can create new connections using the Connections tab. To add a new connection, follow the below steps:
Select the component from the drop-down list for which you wish to create a connection.
For creating an ADLS connection, select ADLS from the Component Type drop-down list and provide connection details as explained below:
For creating a AWS IoT connection, select AWS IoT from the Component Type drop-down list and provide connection details as explained below. Shows all the available connections. Select AWS IoT Component type from the list. This is the AWS Key i.e. the credential to connect to AWS console.
For creating a Azure Blob connection, select Aure Blob from the Component Type drop-down list and provide connection details as explained below:
For creating a Cassandra connection, select Cassandra from the Component Type drop-down list and provide connection details as explained below:
For creating a Cosmos connection, select Cosmos from the Component Type drop-down list and provide connection details as explained below:
For creating a Couchbase connection, select Couchbase from the Component Type drop-down list and provide connection details as explained below:
For creating an Elasticsearch connection, select Elasticsearch from the Component Type drop-down list and provide connections details as explained below.
For creating an Elasticsearch connection, select Elasticsearch from the Component Type drop-down list and provide connections details as explained below.
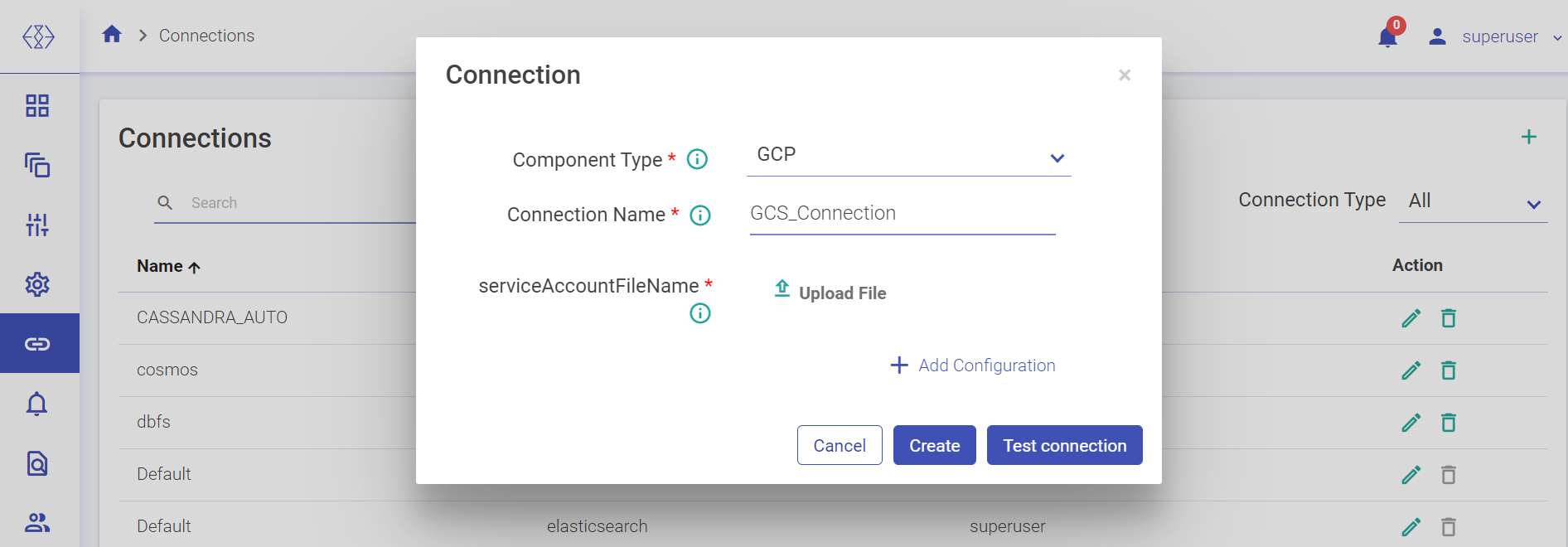
Note: The user can add further configuration.
Click Create, to create the GCP connection.
Now, once the data pipeline is created, the user requires to configure job.
For creating an Hbase connection, select Hbase from the Component Type drop-down list and provide connections details as explained below.
For creating a HDFS connection, select HDFS from the Component Type drop-down list and provide connections details as explained below.
For creating a HIVE Emitter connection, Select HIVE Emitter from the Component Type drop-down list and provide connections details as explained below.
** Properties marked with these two asterix** are presents only in HDP3.1.0 environment.
The value of Hive Server2 URL will be the value of HiveServer2 Interactive JDBC url (given the in the screenshot). In the HDP 3.1.0 deployment, this is an additional property:
HiveServer2 Interactive JDBC URL: The value is as mentioned below: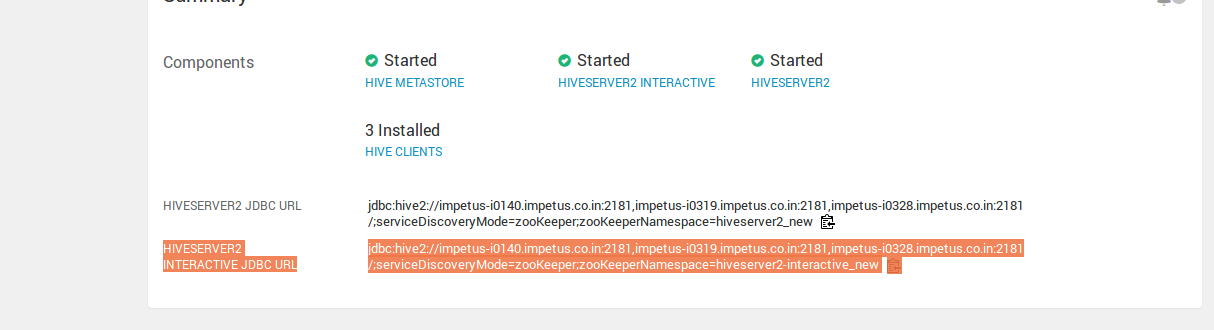
For creating a JDBC connection, select JDBC from the Component Type drop-down list and provide connections details as explained below.
Note: JDBC-driver jar must be in class path while running a pipeline with JDBC emitter or while testing JDBC connection.
For creating a Kafka connection, select Kafka from the Component Type drop-down list and provide connections details as explained below.
For creating a Kinesis connection, select Kinesis from the Component Type drop-down list and provide other details required for creating the connection.
Users can also choose to authenticate Kinesis connections using Instance Profile option.
For creating a KUDU connection, select KUDU from the Component Type drop-down list and provide other details required for creating the connection.
For creating Mongo DB connection, select Mongo DB from the Component Type drop-down list and provide details required for creation the connection.
For creating an MQTT connection, select MQTT from the Component Type drop-down list and provide other details required for creating the connection.
For creating an OpenJMS connection, select OpenJMS from the Component Type drop-down list and provide other details required for creating the connection.
For creating a RedShift connection, select RedShift from the Component Type drop-down list and provide other details required for creating the connection.
For creating a RabbitMQ connection, Select RabbitMQ from the Component Type drop-down list and provide connections details as explained below.
For creating a DBFS connection, select DBFS from the Component Type drop-down list and provide other details required for creating the connection.
For creating a RDS connection, select RDS from the Component Type drop-down list and provide other details required for creating the connection.
For creating a S3 connection, select S3 from the Component Type drop-down list and provide other details required for creating the connection.
For creating an SQS connection, select SQS from the Component Type drop-down list and provide other details required for creating the connection.
For creating a Salesforce connection, select Salesforce from the Component Type drop-down list and provide other details required for creating the connection.
For creating a Socket connection, select Socket from the Component Type drop-down list and provide connections details as explained below.
For creating a Solr connection, Select Solr from the Component Type drop-down list and provide connections details as explained below.
For creating a Tibco connection, select Tibco from the Component Type drop-down list and provide connections details as explained below.
For creating a Twitter connection, select Twitter from the Component Type drop-down list and provide connections details as explained below.
For creating a Vertica connection, select Vertica from the Component Type drop-down list and provide connections details as explained below.
On updating a default connection, its respective configuration also gets updat
In reverse of auto update connection, auto update configuration is also possible.
If you update any component’s configuration property, from Configuration Page, then the component’s default connection will also be auto updated.
For example: Updating RabbitMQ host URL configuration will auto update RabbitMQ Default connection.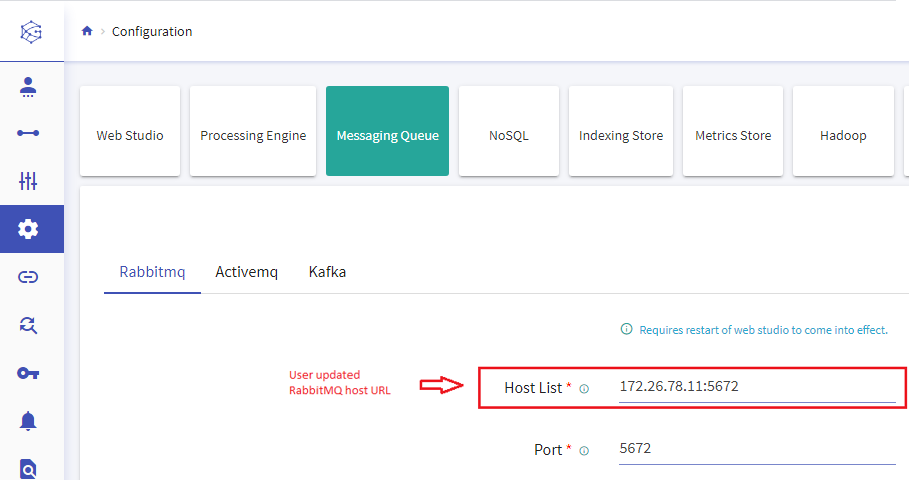
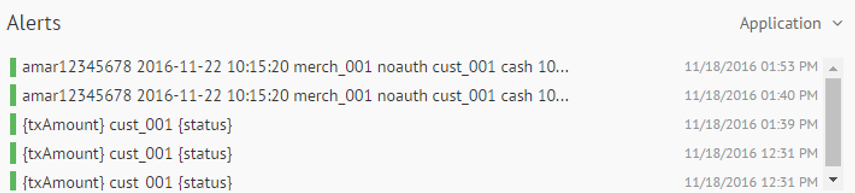
This widget will show system alerts, with a brief description and its timestamp. You can also check the generated alerts on the UI along with email notifications.
From the top right drop-down arrow, select System.
This widget shows the alerts generated by a pipeline when it goes in error mode or killed from YARN.
System alerts shows two types of alerts.
Pipeline stopped Alerts: Alerts thrown when a Pipeline is killed from YARN.
Error Mode Alerts: Alerts thrown when the Pipeline goes in error mode.
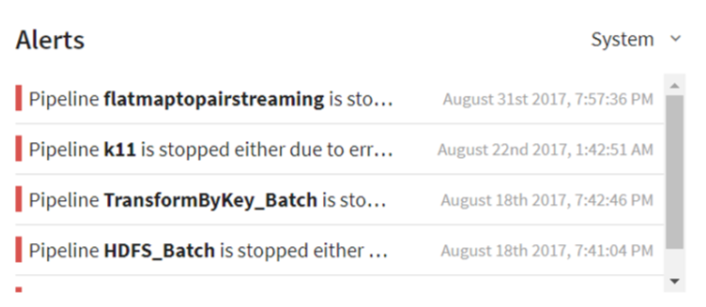
You can apply an alerts on a streaming pipeline as well. You will see the description of the alert and its time stamp in this widget. The alert can have a customized description.
To navigate to the Workspace Connections page, the user can click on the Connections feature which is available in the workspace menu.
The users with privilege to create connections can create new connections at the workspace level in the same manner as it is explained in the manage superuser connections topic. To know more, see Manage Superuser Connections.
- Unique names must be used to create new connections inside a Workspace for similar component types. User will get notified in the UI if the specified connection name already exists.
- The visibility of default connections and the connections created by Superuser at any Workspace level is controlled by the Superuser.
- The connections created in a Workspace can be differentiated by the Workspace and Owner name in the list. The superuser created connections will appear in the list with the Workspace and Owner name as Superuser.
- Connections listed in a workspace can be used to configure features like Datasets, Pipelines, Applications, Data Validations, Import Export Entities & Register Entities inside a Project. While using the connections for above listed features, the superuser connections can be differentiated from other workspace created connections by a suffix, “global” which is given after the connection name.
- Connections will not be visible and cannot be consumed outside of the workspace in which they are created.
This option will only be visible if the containerEnabled property is enabled in the Sandbox configuration settings.
The user can register a desired cluster by utilizing the Register Cluster option. It can be done either by uploading a valid embedded certificate within a config file, or by uploading config file and certificates separately during registration process. The cluster once registered can be utilized across all workspaces while configuring a sandbox.
Currently, only Kubernetes clusters can be registered on Gathr.
On the Cluster Configuration listing page the existing clusters will be listed. Timestamp information about the cluster since the time it is up. The user can Edit/Unregister the registered cluster(s) information.
The user can register a cluster by clicking at the top right + icon.
Configure the cluster by providing the following details:
The user can TEST the cluster configuration and SAVE.
Upon successful registration, the registered cluster will get added in the listing page.
The option to register Container Images within Gathr are provided in the main menu as well as the workspace menu. It will only be visible if the containerEnabled property is enabled in the Sandbox configuration settings.
When user registers a container image, it will be visible as drop-down options in the sandbox configuration page inside project. These container images (sandbox) can be launched on the preferred container (for example, Kubernetes) to access the desired integrated development environments (Examples: Jupyter Lab, Visual Studio Code, Custom and Default) of the user’s choice on the sandbox.
Default IDE option will only be visible when the Register Container Image option is accessed by superuser via the main menu.
The container images that are registered from the main menu by the superuser can be utilized across all workspaces. Whereas, the container images that are registered from the workspace menu remain private to the specific workspace where it is registered.
Registered Container Images Listing
The container images that are registered will appear on the Registered Images page.
The information and actions displayed for the listed Container Images are explained below:
URI registered on container registry and accessible to the cluster. The user can Edit/Unregister the registered container image(s).
Steps to Register Container Image
The user can register a container image by clicking at the top right + icon.
Configure the container image by providing the following details:
Consider the below points for YAML file upload:
• Upload file with .zip extension.
• It should directly contain the valid YAML files.
• Use below expressions to populate YAML fields at runtime during sandbox configuration:
"@{<kind>:<field path>}" - The expression used to refer the specified field from any other YAML file.
Example: In "@{deployment:metadata.name}" expression, the first part "deployment" is kind (i.e., type of YAML) and the next part "metadata.name" is the field that is supposed to be fetched from the specified YAML type.
${value:"<default-value>",label:"<field label>"} - The expression used to display a dynamic field label along with a default value, which is editable.
${value:"sandbox-<<UUID>>",label:"Enter Sandbox Name"}
Field label will be: Enter Sandbox Name and default value will be: sandbox-A123.
"<<UUID>>" - This expression is used to generate a unique ID for a specific field.
In the above YAML configuration snippet, the BASE_PATH will always have a unique value generated via the "/<<UUID>>" expression.
Click REGISTER to complete the process. The registered image will appear in the listing page.
Audit Trail captures and presents all important activities and events in the platform for auditing.
Interaction events include pipeline creation, pipeline inspection, license uploads, test-cases execution, configuration updates, connection updates, notebook creation, model validation and all other interactions possible within Gathr. 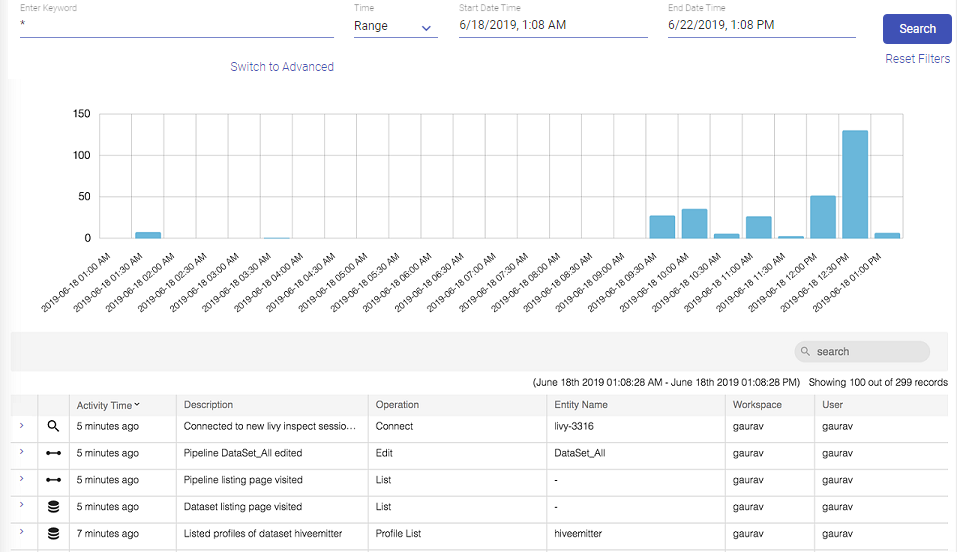
Audit Trail provides following features to search, view and filter user interaction events in graphical and tabular formats.
There are two modes of searching an event, Basic and Advanced.
Events can be searched by providing required parameters inside filter menu on top of Audit Trail page. The search results returned are from all the entities, which is across all workspaces, all types of operations and so on.
In a basic search, following are the options by which you can perform a search.
Note: Time Range and Time Duration search is also performed in Advanced Search.
Different filter operations are available which are listed below.
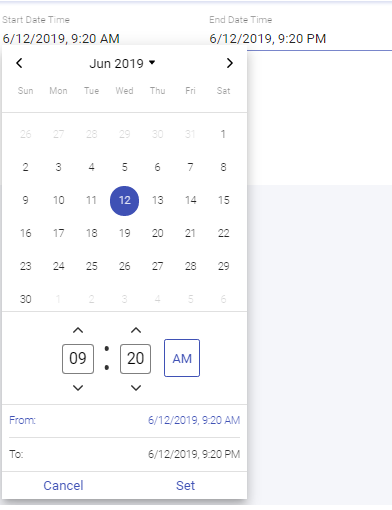
Provide time intervals by setting Start Date Time and End Date Time filters to get those event interactions which were performed in specified time range.
Default value is 12 hours ago from the current system time.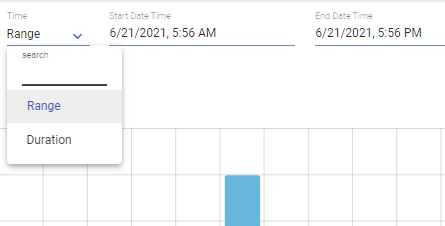
Click on Set button for it to reflect the selected date time.
Select Duration option for defining time intervals. Provide duration as integer value with desired time unit. Default duration value is 12 and unit is hours.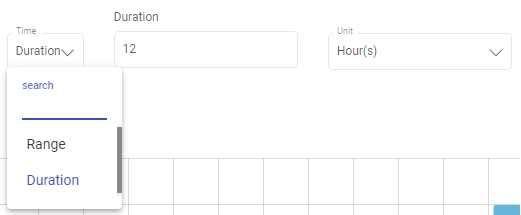
Possible units are minutes, hours, days and weeks.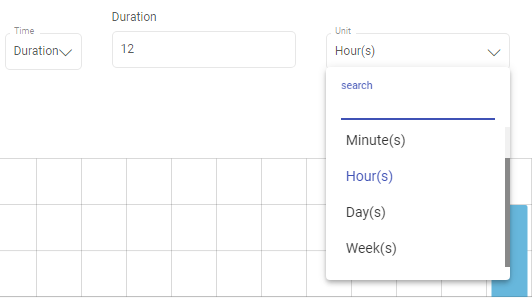
To search events based on keyword or pattern, use Full text search filter option.
Use wildcard (*) to create pattern or provide exact value. System will search events by matching all field values of record.
To perform search on any of the field value of the event record, use colon based pattern.
For example- interactionBy:John*, where, interactionBy is one of the field name of event record which specifies the user name who performed that event and John* is value of field interactionBy. 
Possible field names which can be used to perform Keyword search are as follows:
In contrast to basic Full Text Search, you can perform advance search where you need to select list of entities and operations on which you want to search event interactions.
Possible entities and operation types will be listed on Entity and Operation drop down filters respectively.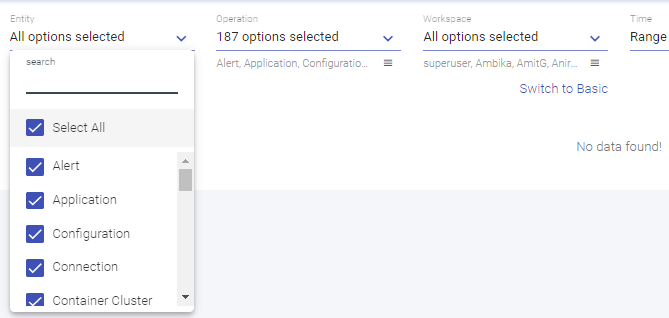
Filter out event interactions based on workspace names. The event occurred in specified work-space will be shown. This filter operation is visible in superuser workspace only.
Time-series graph represents aggregated count of events occurred within given time range. The counts will be shown on time series graph with fixed time intervals. Each interval is represented by graph bar.
Time intervals are calculated based on given time range values in search query. Bigger the given time range, bigger will be the time interval.
Example: 12 hours as input time range will give event counts of every 30 minutes interval 1 hour as input time range will give event counts of every 1 minute interval.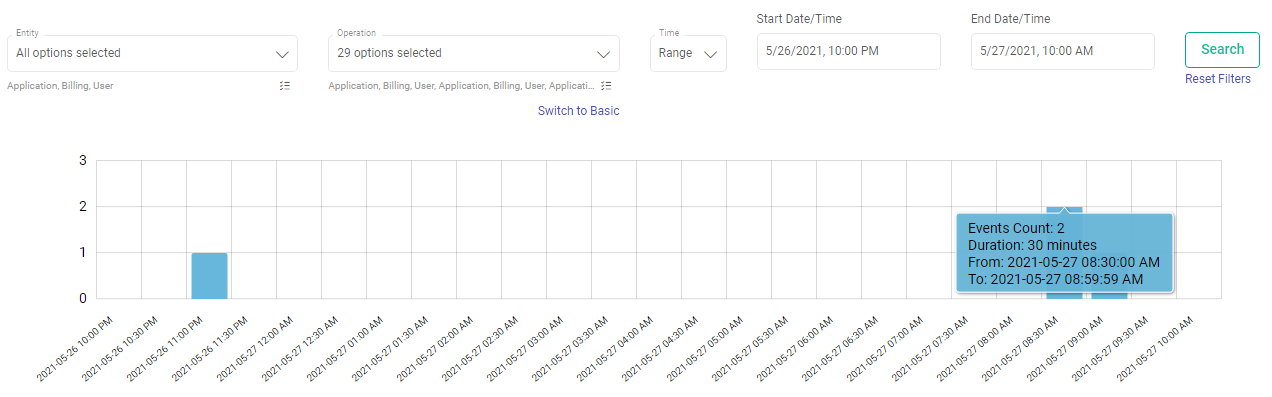
It allows you to zoom in on a specific area of the graph, which will drill down the graph further and will show the zoomed selected area. New search request will be placed with zoomed time range boundaries.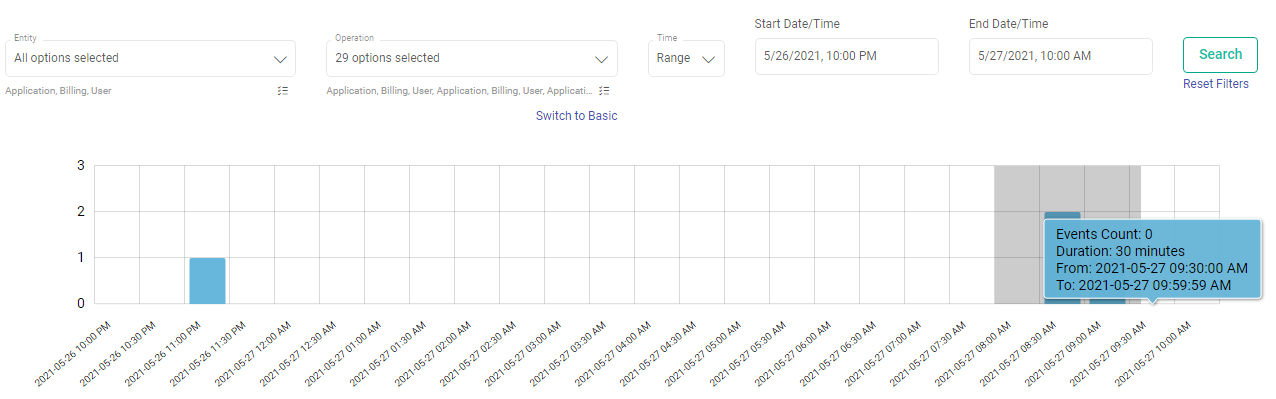
After panning and zooming the results, the graph looks as shown below: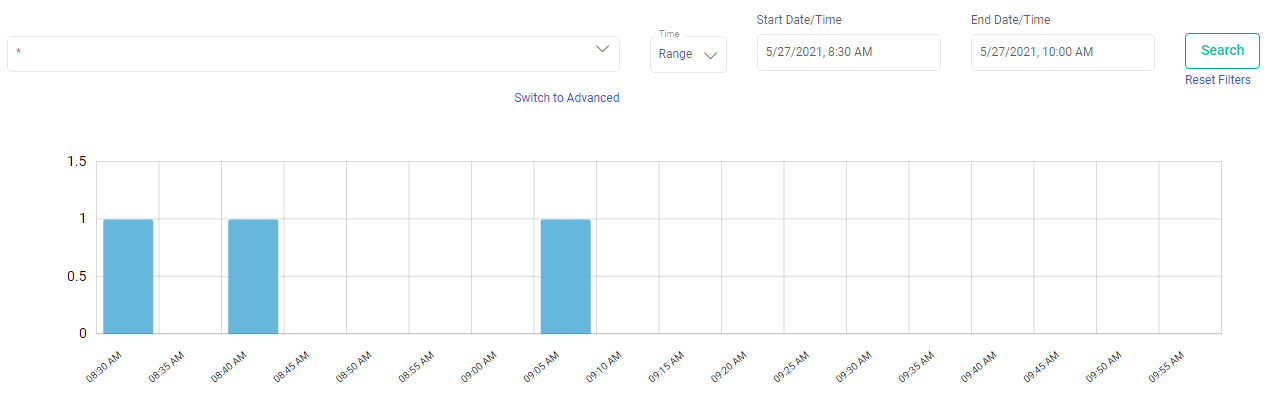
Perform following operations on the search results:
Whenever you scroll down in Result table, next bunch of 100 records will be fetched and appended in result table. You can change the default 100 fetch-size from Audit Configuration page.
Scroll has defined an expiry time after which scroll window will be expired. Default scroll expiry time is 5 minutes.
On every subsequent scroll and new search request, scroll expiry time will get reset.
You can sort results based on field value of events. A new search request will be placed on each sort action and top 100 (default fetch size) sorted results will be shown out of total matched hits.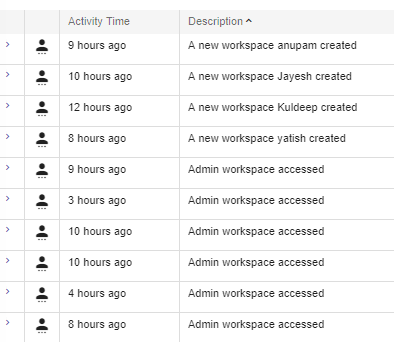
This functionality shows the event activities performed on a pipeline.
Event counts are represented by circles on time series graph.
Event interaction will be auto deleted after configured retention time.
The common terms displayed in the search result table are explained in the table below.
User can configure events audit mechanism as per the requirement.
Refer the Administration Audit tab for configuration details.
Gathr users are the authorized consumers of the application having one or more roles assigned with certain privileges, to execute a group of tasks.
The Manage Users option is provided in the main menu and the workspace menu.
Only the superuser has control over user and role management features that are available in the main menu, whereas both the admin user and the superuser can manage users and roles in the workspace menu.
The other workspace users can only view the role(s) and associated privileges assigned to them in the Manage Users option of the workspace menu.
There are several tabs in the Manage Users feature which are explained in the subsequent topics.
The tabs that are available for Manage Users option in the main menu are described below.
The LDAP tab will only appear when user authentication and authorization is controlled by LDAP or Active Directory in the Gathr configuration options.
The superuser can assign global or custom created roles to the existing LDAP groups as per the requirement.
The information and actions displayed for the listed LDAP groups are explained below:
Once the role assignment for required LDAP groups is done, click on the VALIDATE option to cross-check the LDAP group name and SAVE to register the changes.
This tab contains the list of the out of box global roles and the custom roles that are created using New Role option.
The out of box Global roles are:
The information and actions displayed on the Roles listing page are explained below:
The superuser can create new roles using the Add New Role option given on the top right side of the Roles tab.
The configuration details for creation of a new role are described in the table given below:
Once the required privilege assignment is done for the new role, click on the CREATE option to register the role in Gathr.
This tab contains the list of the users that are registered with Gathr.
The options available on this tab will be different for LDAP configured user management. The description clearly states the options that will be only visible when Gathr Metastore configuration is used for user management.
The information and actions displayed on the Users listing page are explained below:
Note: Add users option is only applicable for Gathr Metastore configuration user management.
The superuser can create new users using the New User option given on the top right side of the Users tab.
The configuration details for creation of a new user are described in the table given below:
Once the required configuration is done for the new user, click on the CREATE option to register the user in Gathr.
The tabs that are available for Manage Users option in the workspace menu are described below.
The users can verify their assigned privileges on the My Roles tab.
The information displayed on the My Roles tab are explained below:
The LDAP tab on the workspace listing is divided in two parts, Global LDAP Groups and Custom LDAP Groups.
The Global LDAP Groups will contain the list of LDAP groups and the roles assigned by the superuser. They cannot be deleted from the Actions column.
The Custom LDAP Groups will contain the list of LDAP groups and roles assigned at the Workspace level. They can be deleted from the Actions column.
The steps and configuration to add custom LDAP groups and roles is same as mentioned in the table for Global LDAP groups which is given in Manage Users (Main Menu) topic.
The Roles tab contains the list of Global roles (created by superuser through the main menu) and custom roles (added through the workspace menu).
The Global roles listed on this tab cannot be deleted from the Actions column.
The steps and configuration to add roles is same as mentioned in the Manage Users (Main Menu) topic.
The Users tab contains the list of users.
The options and functionality are same as described in the Users section of the Manage Users (Main Menu) topic.
A number of users that are registered in Gathr can be combined in a group to manage assignment of privileges for the entire group from Groups tab.
The information and actions displayed on the Groups listing page are explained below:
The groups can be created using the New Group option given on the top right side of the Groups tab.
The configuration details for creation of a new group are described in the table given below:
To change outline of any existing connection, components or pipelines, a developer has to manually edit JSON files residing in /conf/common/template directory of Gathr bundle. Templates allow you to update these from UI. You can create many versions of them and switch to any desired version at any point. The changes in the outline of that component will be reflected immediately.
Components tab allows you to edit the JSON, view the type of component for Spark engine.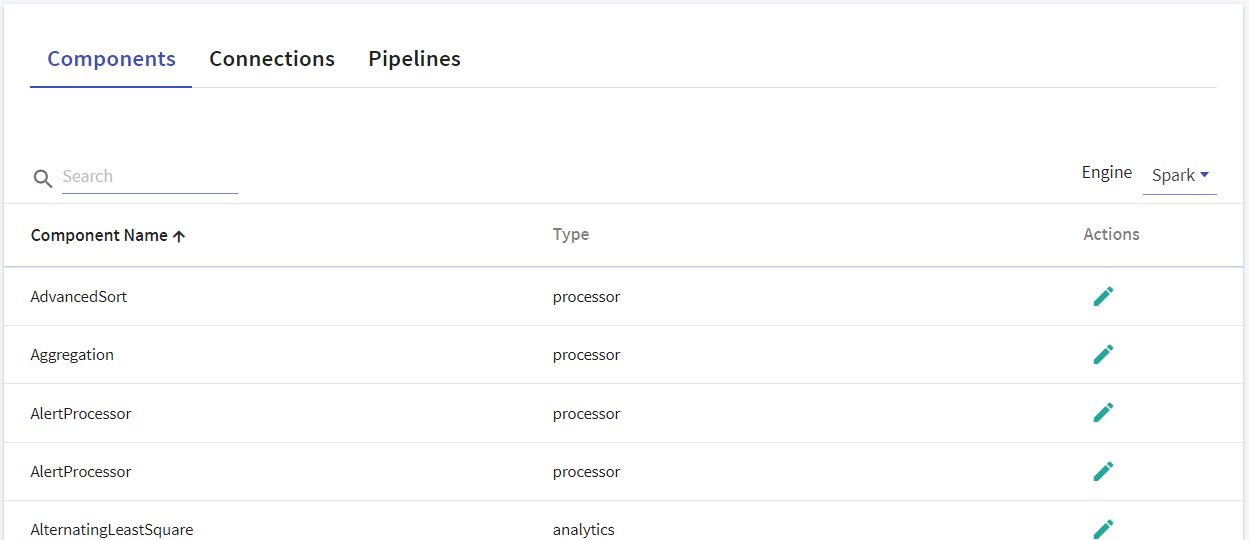
When you edit any component, Version, Date Modified and Comments added are viewable.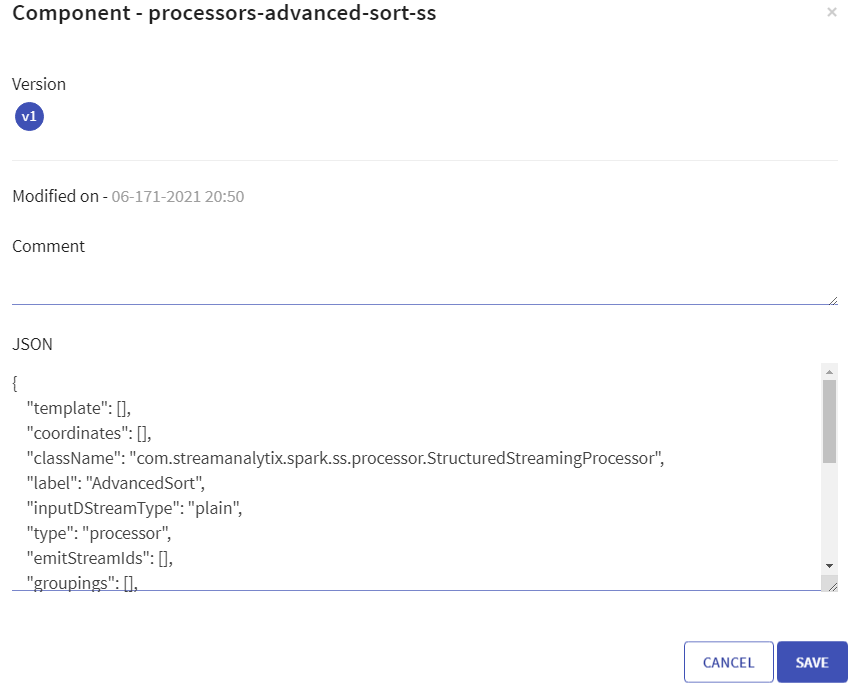
Connection tab allows you to edit the JSON and create as many versions as required.
When you edit any Connection, Version, Date Modified and Comments added are viewable.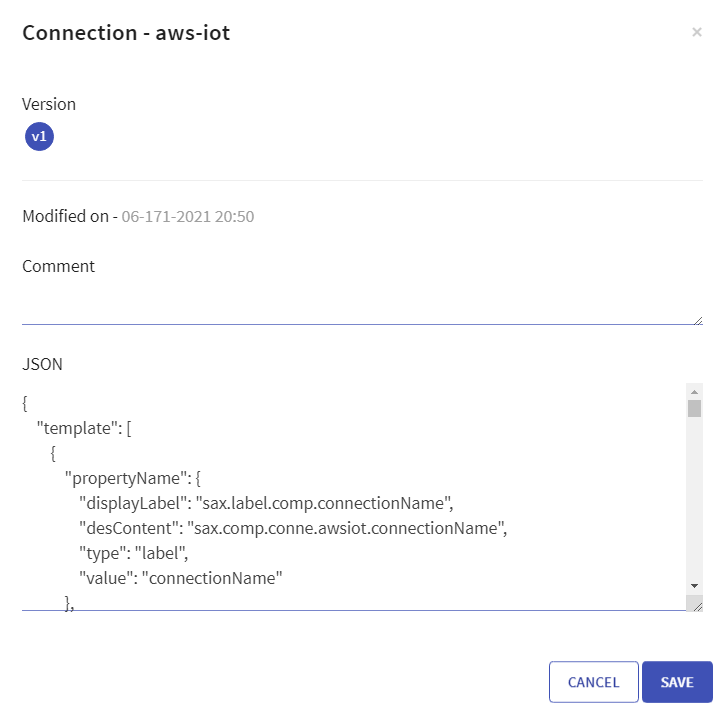
Gathr Credit Points Consumption calculates the credits which is based on the number of cores used in the running jobs. It is a costing model which charges customer based on their usage.
The number of cores used is captured every minute for every running job. Currently the number of cores used is calculated for two types of clusters: EMR and Databricks.