This topic presents the side navigation panel, referred as the main menu and its features that can be used to perform several administrative tasks in Gathr. The illustration of the main menu is given below and the tasks that can be performed with these features are explained further in detail.
Note: The main menu is only displayed for the Superusers (System Admin) login.
Manage Workspaces
Cluster List View
Manage Setup
Manage Configuration
Manage Connections
Audit Trail
Manage Users
Templates
Credit Points Consumption
Help
gathr provides multi-tenancy support through Workspaces.
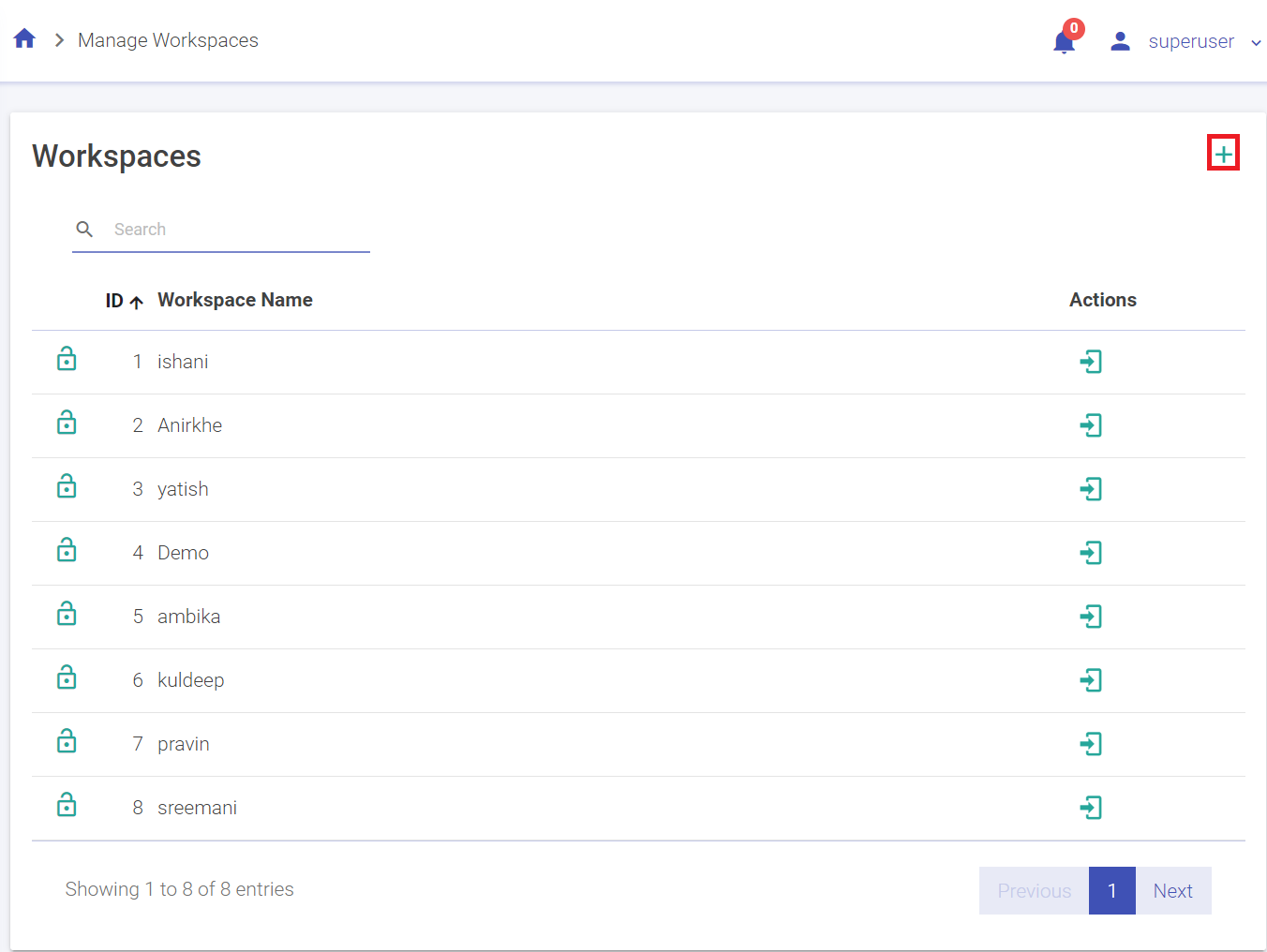
Superuser can create multiple workspaces and add users to a workspace. One user can be mapped to multiple workspaces.
A superuser can create number of workspaces.
Below are the steps to create a workspace.
1. Go to Manage Workspace and click on Create New Workspace. (The plus sign on the top right corner)
2. Enter the details in the following tab.
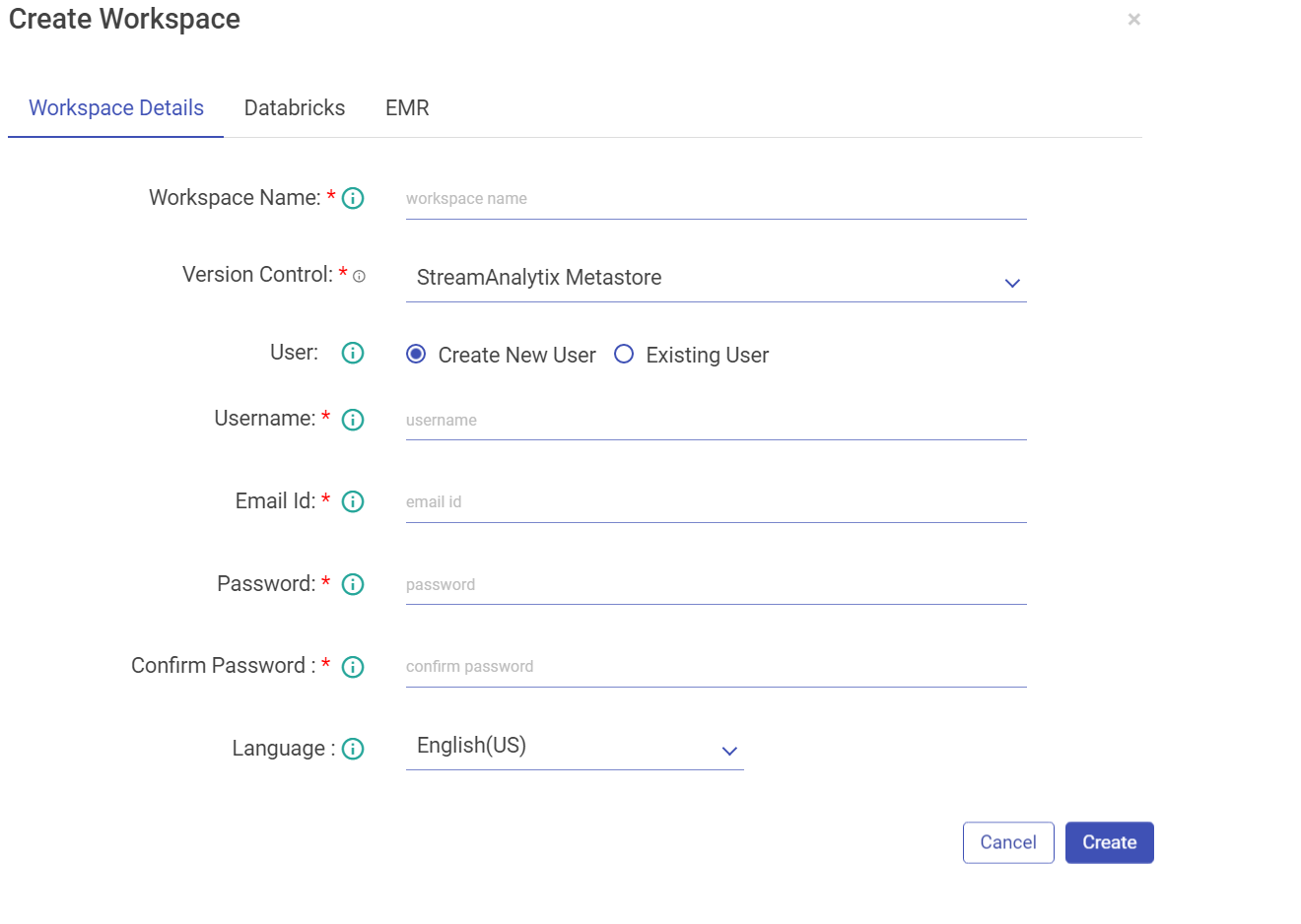
Property | Description |
|---|---|
Workspace Name | Enter a unique name for your workspace. |
Version Control | User can select option for Version Control from the drop-down. Currently the below mentioned options are available: - gathr MetaStore - Bitbucket - GitHub -GitLab |
User can opt for gathr MetaStore option (default) for Version Control and proceed further to fill other required details mentioned below. | |
If user selects Bitbucket option as Version Control, fill the below fields: | |
Git Login via. | User can log in via. Credentials/SSH Keys. |
Upon selecting Credentials option, fill the below fields: | |
Bitbucket User Name | Provide the Bitbucket user name. |
Bitbucket Password | Provide the Bitbucket password. Click the Fetch Workspace button to fetch the Bitbucket Workspace. |
Upon selecting SSH Keys option upload the Git SSH Key file. | |
If user selects GitHub option as Version Control, fill the below fields: | |
Git Login via. | User can log in via. Credentials/SSH Keys. |
Upon selecting Credentials option, fill the below fields: | |
Git User Name | Provide the GitHub user name. |
Git Password | Provide the GitHub access token or password. |
If user selects GitLab option as Version Control, fill the below fields: | |
Git Login via. | User can log in via. Credentials/SSH Keys. |
Upon selecting Credentials option, fill the below fields: | |
Git User Name | Provide the Git user name. |
Git Password | Provide the Git password. C |
User | A user can be of following types: Create New User: Enter a user name. |
If the user selects Create New User option, fill the below fields: | |
Username | Enter a username that will be used to log in the Application. |
Email Id | Enter an email id that will be used for any communication with the user. |
Password | Enter a Password. |
Confirm Password | Re-type the password. |
Language | Choose the language, from English (US) and German (DE). Click Create. |
If the user selects Existing User option, in that case Assign User by selecting users who can access the workspace. | |
While creating the workspace, configure Databricks Token details and credentials.
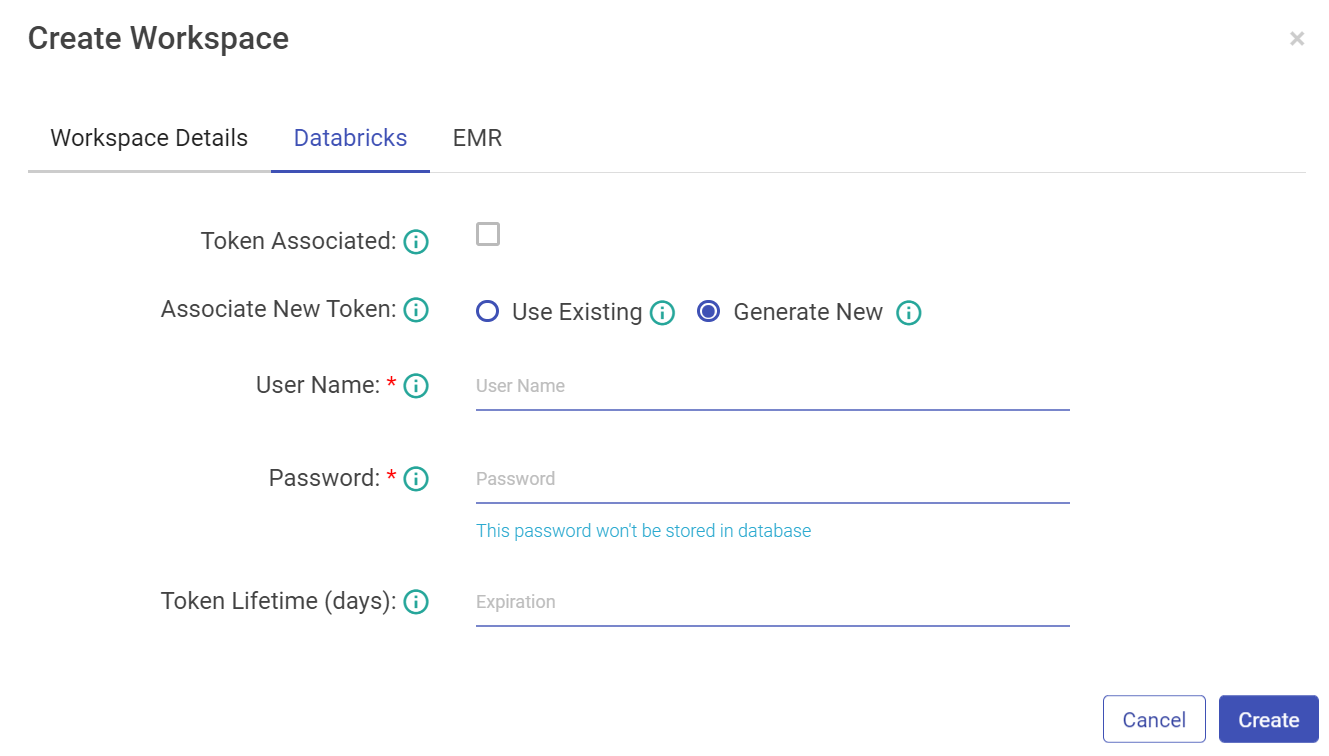
Property | Description |
|---|---|
Token Associated | If the Databricks user token is associated with gathr user or not. |
Associate New Token | Associate a new Databricks user token. Use Existing: Select this if you already have a databricks token_value. Generate New: Select this option if you want to generate new databricks. |
Username | Provide Databricks username with which token_value is generated. |
Password | Enter the password for Databricks username. |
Token Lifetime (days) | Provide Databricks token_value. |
For EMR, you can configure using AWS keys or the Instance Profile.
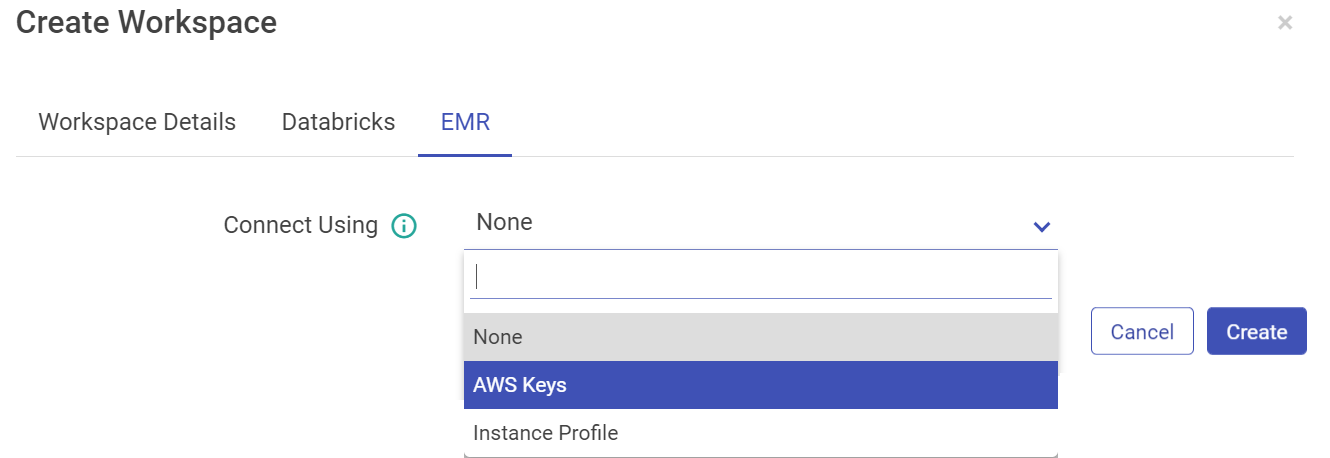
Configure with EMR cluster using AWS Keys:
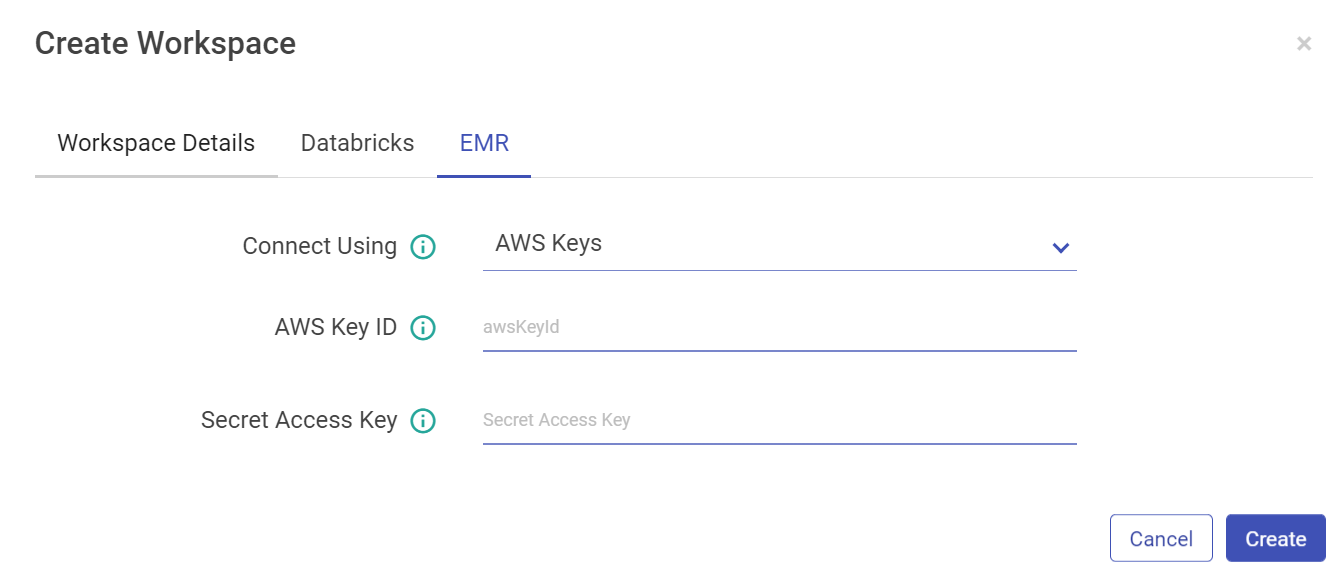
Property | Description |
|---|---|
Connect Using | Select AWS Keys from the drop-down if you want to configure EMR cluster using AWS Key ID and Secret Access Key. |
AWS Key ID | AWS Key that will be used for all the communication with AWS. |
Secret Access Key | Secret key corresponding to AWS key. |
Configure with EMR cluster using Instance Profile option:
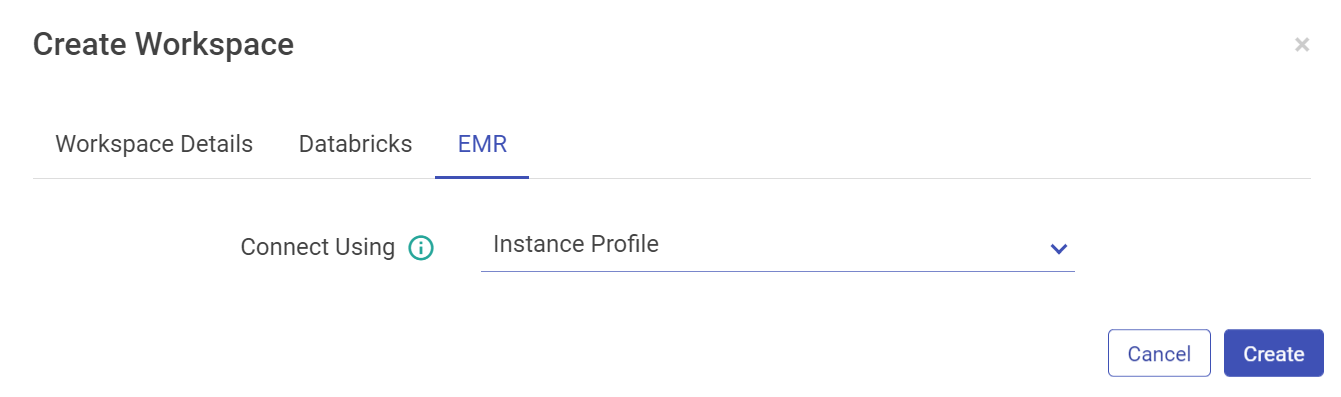
Note: Users creation is based on Databricks and EMR access as well. There may be users that won’t have access to create a Databricks users, for them the Databricks tabs will be not be accessible and so will be the case for EMR users.
3. Click Create to save the changes and the new Workspace will be listed in the Manage Workspaces page.
To enter a workspace, click on the enter icon.
Note: There is no provision to edit or delete a workspace.
Once the user enters into a Workspace, similar components will appear on the Workspace landing page as explained earlier in the Getting Started topic.
To know more about the Workspace menu, see Projects, Manage Workspace Connections and Manage Workspace Users.
To navigate to the Workspace Connections page, the user can click on the Connections feature which is available in the workspace menu.
The user can create new connections at the workspace level in the same manner as it is explained in the manage superuser connections topic.
Notes:
- Unique names must be used to create new connections inside a Workspace for similar component types. User will get notified in the UI if the specified connection name already exists.
- The visibility of default connections and the connections created by Superuser at any Workspace level is controlled by the Superuser.
- The connections created in a Workspace can be differentiated by the Workspace name in the list. The superuser created connections will appear in the list with the Workspace name as Superuser.
- Connections listed in a workspace can be used to configure features like Datasets, Pipelines, Applications, Data Validations, Import Export Entities & Register Entities inside a Project. While using the connections for above listed features, the superuser connections can be differentiated from other workspace created connections by the workspace name.
- Connections will not be visible and cannot be consumed outside of the workspace in which they are created.
A developer user can be created for a Workspace.
A developer user can perform unrestrictive operations within a workspace, such as operations of a DevOps role along with pipeline creation, updating and deletion.
To create a new Workspace User, go to Manage Users and select Create New User.
Following are the properties for the same:
Property | Description |
|---|---|
User Role | Only a Developer user can be created from within the Workspace. |
User Name | Enter a username that will be used to log in the Application. |
Email Id | Enter an email id that will be used for any communication with the user. |
Password | Enter a Password. |
Confirm Password | Re-type the password. |
Language | Choose the language, from English (US) and German (DE). |
Also, there will be options to configure the AWS Databricks and EMR as explained earlier.
Click the workspace icon in the upper right corner of the page to view a drop-down list of the workspaces. Choose the workspace from the list you wish to enter.
NOTE: There is no provision to delete any workspace.
User can manage the AWS Databricks and EMR clusters with this option.
All the existing clusters for Databricks and EMR will be listed in the Cluster List View page.
User has options to create interactive clusters, perform actions like start, refresh, edit and delete clusters, view logs and redirect to spark UI.
Given below is an illustration of the Databricks Interactive Clusters page followed by the steps to create a cluster.
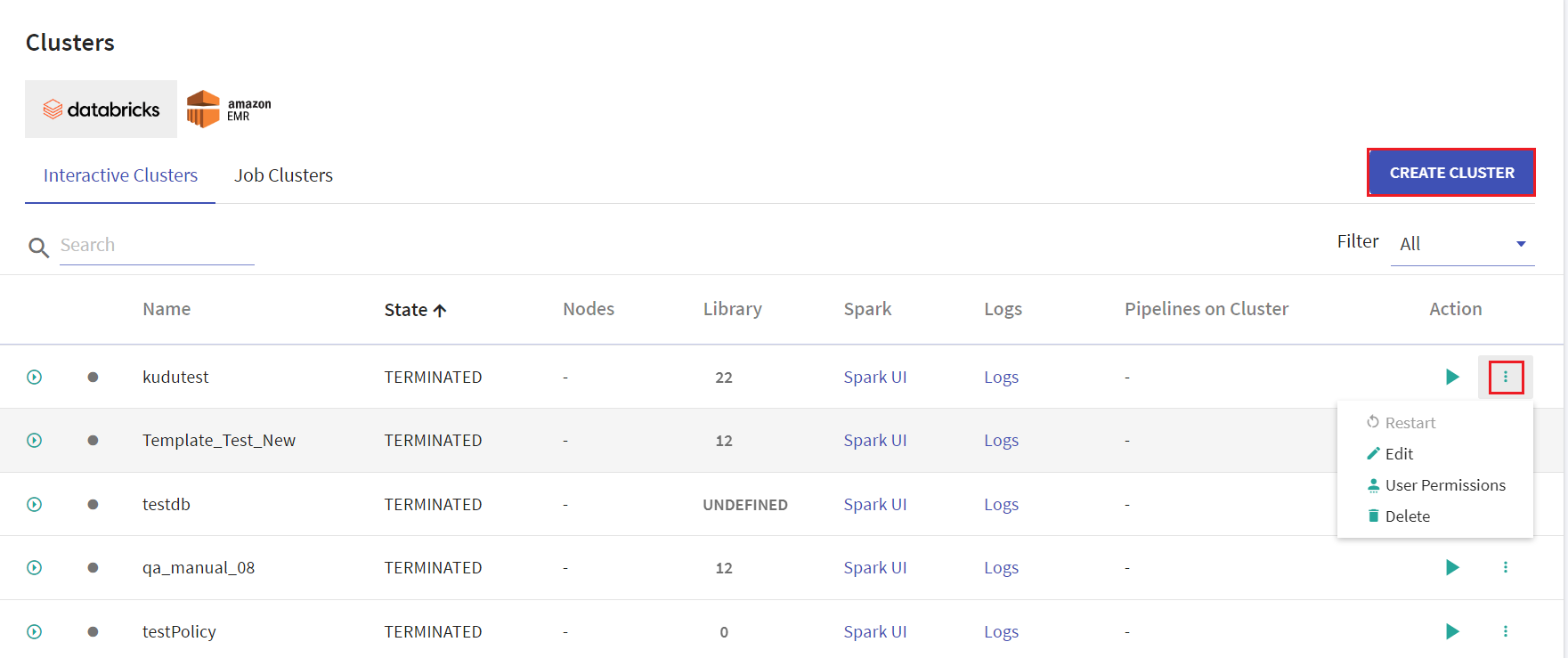
On the listing page under Action tab, user has options to start the cluster. Upon clicking the ellipses, under Action tab the available options are: Restart, Edit, User Permissions and Delete.
User has option to manage permissions of the existing Databricks clusters. Upon clicking User Permissions, the below screen will open:
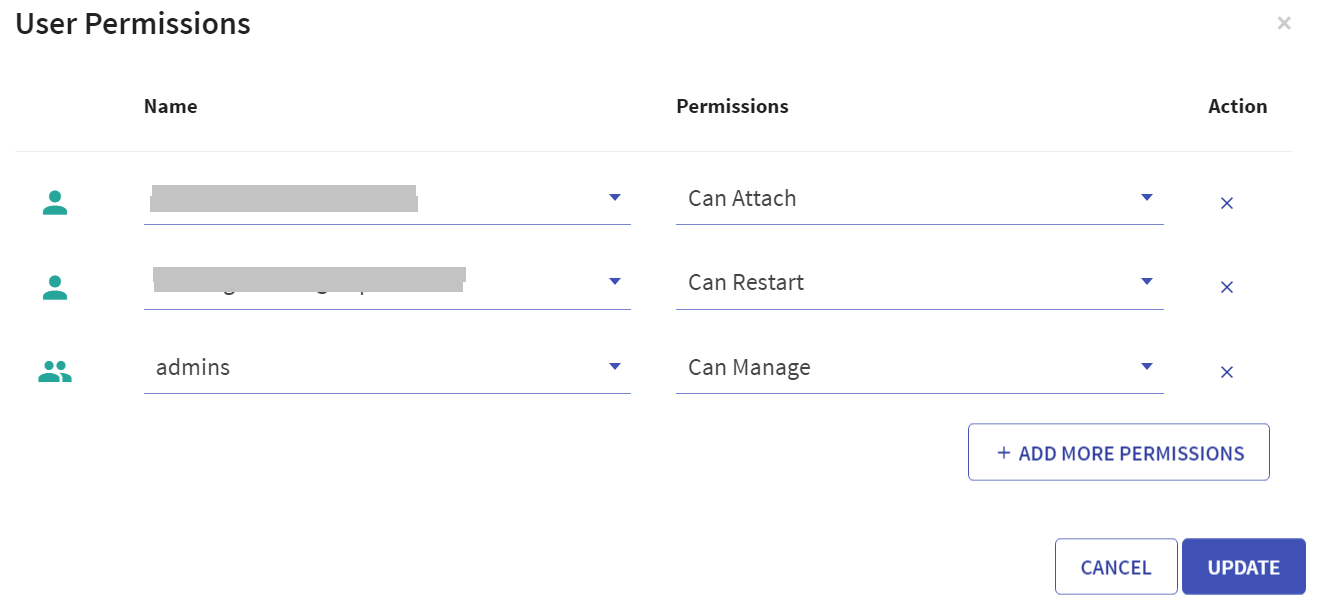
There are four permission levels for a cluster: No Permissions, Can Attach To, Can Restart, and Can Manage thereby enabling the cluster to be accessed by a set of users with specific permissions.
Note: User must comply with the below mentioned prerequisites for User Permissions in Databricks account:
- Admin to enable below mentioned toggles for the workspace in its settings:
- Under Access Control, 'Control Jobs, and pools Access Control' toggle must be enabled.
- Under Access Control, 'Cluster Visibility Control' option must be enabled to allow listing of only those clusters to the user for which it has any permission.
- Access control is available only in the Premium plan.
On the listing page, click CREATE CLUSTER to create Databricks cluster. Provide the below fields:
Field | Description |
|---|---|
Cluster Policy | Option to select the cluster policy created in Databricks to configure cluster that defines limits on the attributes available during the cluster creation. Default value is unrestricted. User have an option to download the cluster policy in the local system. |
Cluster Name | Provide a unique name for the cluster. |
Cluster Mode | Select Cluster node from the below options available: -Standard -Single Node Note: The Cluster Mode option is not editable on Databricks interactive cluster. |
Databricks Runtime Version | Provide the Databricks runtime version for the core components that run on the clusters managed by Databricks. |
The below option will be available upon selecting Single Node as Cluster Mode | |
Node Type | Provide the node type, if Single Node option is selected as Cluster Mode. |
Driver Type | Select the driver type from the drop down list. The available options are: - Same as worker - Pool - Memory Optimized Note: If the Driver Type option is selected as Pool, then the Worker Type must also be Pool. Once the created cluster is associated with the pool and the cluster is created successfully, the pool can be utilized in configuring a job. |
Worker Type | Select the worker type from the drop down list. |
Terminate After | Provide value in minutes to terminate the cluster due to inativity. |
The below options will be visible upon selecting Standard as Cluster Mode | |
Enable auto-scaling | This option is unchecked by default. Check the checkbox to enable auto-scaling the cluster between minimum and maximum number of nodes. |
Provide value for below fields if auto scaling is enabled | |
Minimum Workers | Provide value for minimum workers. |
Maximum Workers | Provide value for maximum workers. |
Workers | If auto scaling is unchecked, then provide value for workers. |
On-demand/Spot Composition | Provide the value for on-demand number of nodes. |
Spot fall back to On-demand | Check the option to use the Spot fall back to On-demand option. If the EC2 spot price exceeds the bid, use On-demand instances instead of spot instances. |
Databricks Interactive Clusters
Given below is an illustration of the Databricks Interactive Clusters page followed by the steps to create a cluster.
Click CREATE CLUSTER to create Databricks cluster. Provide the below fields:
Field | Description |
|---|---|
Cluster Name | Provide a unique name for the cluster. |
Cluster Mode | Select Cluster node from the below options available: -Standard -Single Node |
Databricks Runtime Version | Provide the Databricks runtime version for the core components that run on the clusters managed by Databricks. |
The below option will be available upon selecting Single Node as Cluster Mode | |
Node Type | Provide the node type, if Single Node option is selected as Cluster Mode. |
Driver Type | Select the driver type from the drop down list. |
Worker Type | Select the worker type from the drop down list. |
Terminate After | Provide value in minutes to terminate the cluster due to inativity. |
The below options will be visible upon selecting Standard as Cluster Mode | |
Enable auto-scaling | This option is unchecked by default. Check the checkbox to enable auto-scaling the cluster between minimum and maximum number of nodes. |
Provide value for below fields if auto scaling is enabled | |
Minimum Workers | Provide value for minimum workers. |
Maximum Workers | Provide value for maximum workers. |
Workers | If auto scaling is unchecked, then provide value for workers. |
On-demand/Spot Composition | Provide the value for on-demand number of nodes. |
Spot fall back to On-demand | Check the option to use the Spot fall back to On-demand option. If the EC2 spot price exceeds the bid, use On-demand instances instead of spot instances. |
Given below is an illustration of the Databricks Job Clusters page.
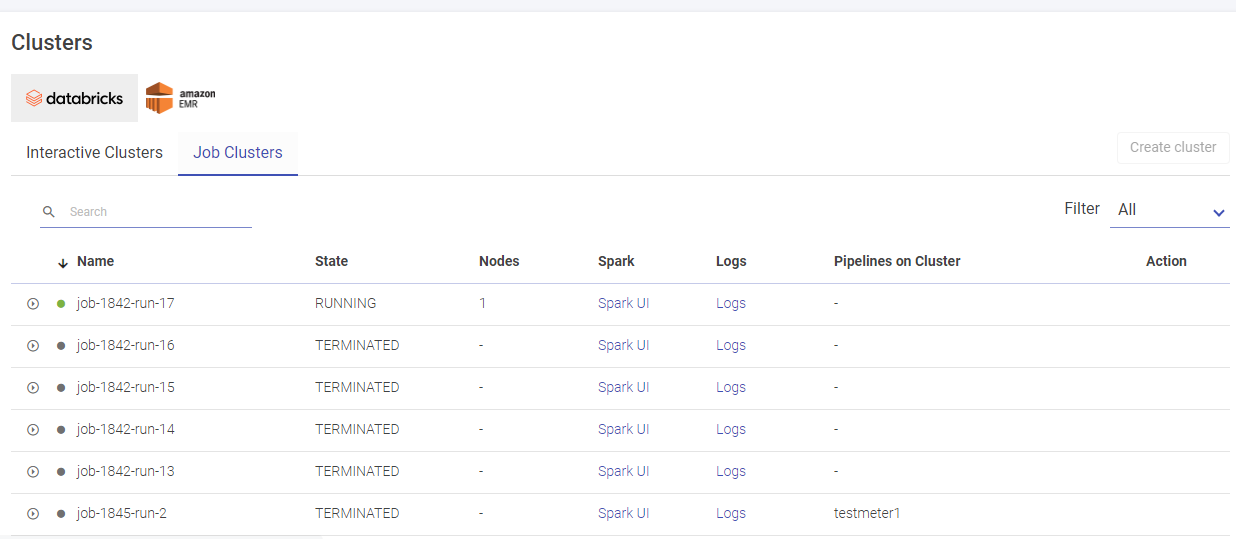
User has options to create long running clusters, fetch clusters from AWS, perform actions like start, edit and delete clusters, view logs and redirect to spark UI.
Given below is an illustration of the EMR Long Running Clusters page.
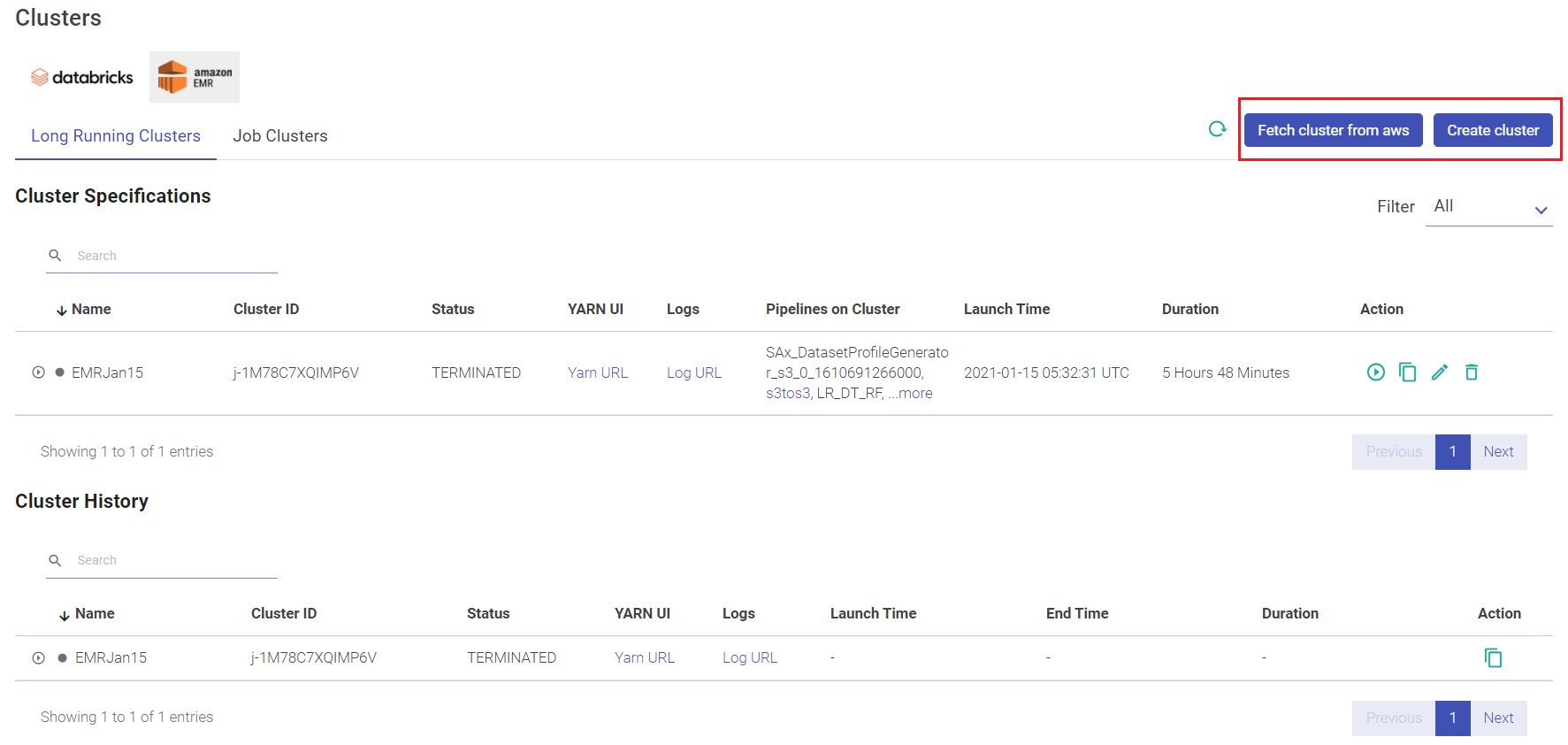
Given below is an illustration of the EMR Job Clusters page.
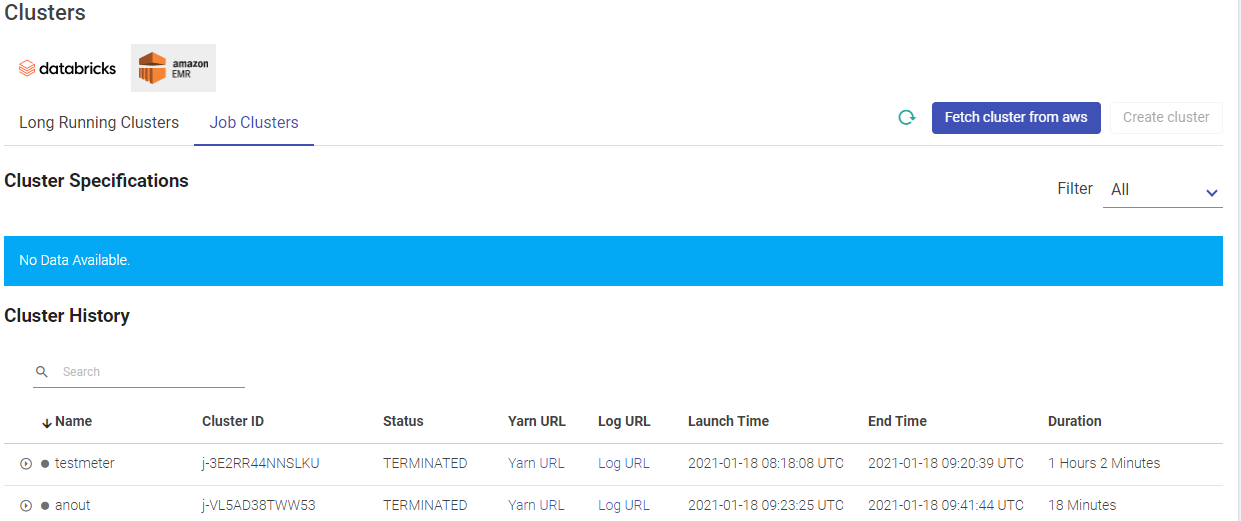
Click CREATE CLUSTER to create a fresh cluster. Provide the below fields for creating a new cluster.
Field | Description |
|---|---|
Cluster Name | Provide a unique name for the cluster. |
VPC | Select VPC for the cluster to be launched. |
Subnet ID | Select subnet with the cluster to be launched. |
Security Group | Select security group for the cluster to be launched. |
Security Configuration | Select security configuration from the drop down list of available options. Select None if security configuration is not required. |
Service Role | Select the emrIAMRole from the drop-down list of service roles. |
Job Flow Role | Select the emrIAMRole from the drop-down list of job flow roles. |
Auto Scaling Role | Select the emrIAMRole from the drop-down list of auto scaling roles. |
Root EBS Volume (GB) | Provide the root value for the cluster. Default value is 10. |
EMR Managed Scaling | Upon checking the option, the EMR will automatically adjust the number of EC2 instances required in core and task nodes based on workload. This option is unchecked by default. |
Upon checking the EMR Managed Scaling option, provide values for the below fields: | |
Minimum Units | Provide the minimum number of core or task units allowed in a cluster. Minimum value is 1. |
Maximum Units | Provide the maximum number of core or task units allowed in a cluster. Minimum value is 1. |
Maximum On-Demand Limit | Provide the maximum allowed core or task units for On-Demand market type in a cluster. If this parameter is not specified, it defaults to maximum units value. Minimum value is 0. |
Maximum Core Units | Provide the maximum allowed core nodes in a cluster. If this parameter is not specified, it defaults to maximum units value. Minimum value is 1. |
Auto Termination | This option is unchecked by default. Check this option for auto termination of cluster. Once the cluster becomes idle, it will terminate after the duration specified. Choose a minimum of one minute or a maximum of 24 hours value. |
Steps Concurrency | This option is unchecked by default. Check this option to enable running multiple steps concurrently. Once the last step completes, the cluster will enter a waiting state. |
Upon checking the Steps Concurrency check-box, the option appears: | |
Maximum Steps | Provide value for the maximum steps that can run at a time. Enter a value between 2 and 256. |
Click FETCH CLUSTER FROM AWS option to fetch an existing cluster by selecting the cluster ID from the drop-down list.
To navigate to the Workspace Connections page, the user can click on the Connections feature which is available in the workspace menu.
The users with privilege to create connections can create new connections at the workspace level.
Note:
- Unique names must be used to create new connections inside a Workspace for similar component types. User will get notified in the UI if the specified connection name already exists.
- The visibility of default connections and the connections created by Superuser at any Workspace level is controlled by the Superuser.
- The connections created in a Workspace can be differentiated by the Workspace and Owner name in the list. The superuser created connections will appear in the list with the Workspace and Owner name as Superuser.
- Connections listed in a workspace can be used to configure features like Datasets, Pipelines, Applications, Data Validations, Import Export Entities & Register Entities inside a Project. While using the connections for above listed features, the superuser connections can be differentiated from other workspace created connections by a suffix, “global” which is given after the connection name.
- Connections will not be visible and cannot be consumed outside of the workspace in which they are created.
This option will only be visible if the containerEnabled property is enabled in the Sandbox configuration settings.
The user can register a desired cluster by utilizing the Register Cluster option. It can be done either by uploading a valid embedded certificate within a config file, or by uploading config file and certificates separately during registration process. The cluster once registered can be utilized across all workspaces while configuring a sandbox.
Currently, only Kubernetes clusters can be registered on Gathr.
On the Cluster Configuration listing page the existing clusters will be listed.
Field Name | Description |
|---|---|
Name | Name of the registered cluster. |
Up Since | Timestamp information about the cluster since the time it is up. |
CPU/Memory | The consumed CPU/Memory will be listed here. |
Actions | The user can Edit/Unregister the registered cluster(s) information. |
The user can register a cluster by clicking at the top right + icon.
Configure the cluster by providing the following details:
Field Name | Description |
|---|---|
Type | Select type of cluster to be registered, i.e. kubernetes. |
Name | Provide a unique name of cluster to be registered. |
Ingress URL | Provide ingress URl with accurate server host and port details. |
Upload Certificate as | The user has an option to upload a valid cluster configuration file having certificate data (like certificate-authority-data, server, client-certificate-data, client-key-data) definition. Else, upload configuration and certificates separately. These are further explained below: Config with embedded certificate: The user can upload K8 config files with all the certificates embedded in a single zip file. Upload Config (zip): Kubernetes configuration zip file with all the certificates embedded. Upload certificate files: The user can upload configuration and certificates separately. Provide the API Server URL. Upload the below files: - Authority Certificate: Upload the API server client authority certificate. - Client Certificate: Upload the client certificate for API server authentication. - Client Key: Upload the client key for server API authentication. |
The user can TEST the cluster configuration and SAVE.
Upon successful registration, the registered cluster will get added in the listing page.
The option to register Container Images within Gathr are provided in the main menu as well as the workspace menu. It will only be visible if the containerEnabled property is enabled in the Sandbox configuration settings.
When user registers a container image, it will be visible as drop-down options in the sandbox configuration page inside project. These container images (sandbox) can be launched on the preferred container (for example, Kubernetes) to access the desired integrated development environments (Examples: Jupyter Lab, Visual Studio Code, Custom and Default) of the user’s choice on the sandbox.
Default IDE option will only be visible when the Register Container Image option is accessed by superuser via the main menu.
The container images that are registered from the main menu by the superuser can be utilized across all workspaces. Whereas, the container images that are registered from the workspace menu remain private to the specific workspace where it is registered.
Registered Container Images Listing
The container images that are registered will appear on the Registered Images page.
The information and actions displayed for the listed Container Images are explained below:
Field Name | Description |
|---|---|
Image Name | Name of the container image registered. |
Container Image URI | URI registered on container registry and accessible to the cluster. |
Tags | Custom tags added during container image registration. |
Actions | The user can Edit/Unregister the registered container image(s). |
Steps to Register Container Image
The user can register a container image by clicking at the top right + icon.
Configure the container image by providing the following details:
Field Name | Description |
|---|---|
Image Name | Provide a unique name of container to be registered. |
Description | Provide container image description. |
Tags | Custom tags for the container image can be added. |
Image URI | URI registered on container registry and accessible to the cluster must be provided. |
IDE | The IDE options that are selected here will be available during Sandbox configuration. |
Upload Docker File | An option to upload the docker file for user’s reference. |
Upload YAML [Zip] | A zip file containing supported YAML’s for the image can be uploaded. Once the YAML file is uploaded, the user can view details of the uploaded file by clicking on the View YAML File icon. Note: To know more about the YAML files upload, see Upload YAML Example given after the table. |
Upload YAML Example
Consider the below points for YAML file upload:
• Upload file with .zip extension.
• It should directly contain the valid YAML files.
• Use below expressions to populate YAML fields at runtime during sandbox configuration:
"@{<kind>:<field path>}" - The expression used to refer the specified field from any other YAML file.
Example: In "@{deployment:metadata.name}" expression, the first part "deployment" is kind (i.e., type of YAML) and the next part "metadata.name" is the field that is supposed to be fetched from the specified YAML type.
${value:"<default-value>",label:"<field label>"} - The expression used to display a dynamic field label along with a default value, which is editable.
Example:
${value:"sandbox-<<UUID>>",label:"Enter Sandbox Name"}
Field label will be: Enter Sandbox Name and default value will be: sandbox-A123.
"<<UUID>>" - This expression is used to generate a unique ID for a specific field.
Example:
- name: BASE_PATH
value: "/<<UUID>>"
In the above YAML configuration snippet, the BASE_PATH will always have a unique value generated via the "/<<UUID>>" expression.
Click REGISTER to complete the process. The registered image will appear in the listing page.
This section is defined in Installation Guide and defines the properties of Cluster Configuration, gathr settings, Database, Messaging Queue, Elasticsearch, Cassandra and Version Control.
Under SETUP, the user has an option to manage Version Control.
Field | Description |
|---|---|
Version Control System | User has an option to choose Git or gathr Metastore as version control system. In case of Git, the pipeline artifacts will get pushed to Git after a version is created. In case of gathr Metastore, the pipeline artifacts will be stored in the file system. |
If user selects Git option as Version Control System, fill the below fields: | |
Repositories Local Path | Provide the repositories local path where the Git clone will be placed in the repos of the file system. |
auth.type | Choose Credentials/SSH option from the drop-down. Note: - Upon selecting Credentials, provide the User name and Password. - Upon selecting SSH, upload the SSH key path. |
HTTP URL | Provide the HTTP URL of the remote GIT repository. |
Branch | Provide the branch name where the push operation will be performed. Note: Click SAVE/CLONE. |
Note: In gathr, under Setup > Version Control tab, in case of Bitbucket, make sure to create App password in Bitbucket account. Once the app password for Bitbucket is created, provide that password along with username in the gathr UI to access private repos. | |
If user selects gathr Metastore as Version Control System, fill the below fields: | |
auth.type | Choose Credentials/SSH option from the drop-down. Note: Upon selecting Credentials, provide the User name and Password. Upon selecting SSH, upload the SSH key path. Click SAVE. |
Configuration page enables configuration of gathr properties.
Note: Some of the properties reflected are not feasible with Multi-Cloud version of gathr. These properties are marked with **
Each sub-category contains configuration in key-value pairs. You can update multiple property values in single shot.
Update the values that you want then scroll down to bottom and click on Save button.
You will be notified with a successful update message.
Performs search operation to find property key or property value. You can search by using partial words of key labels, key names or key values.
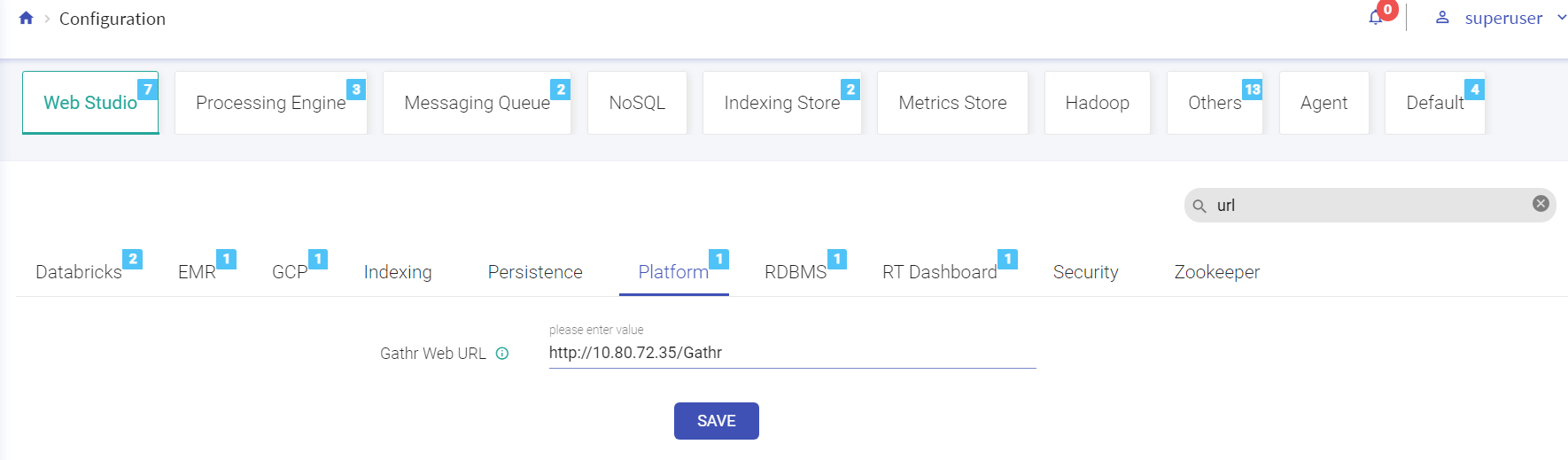
The above figure shows, matching configuration values and count for the searched keyword “url”.
By hovering the mouse on a property label, a box will show the fully qualified name of the key and click on the i button for its description.
The above figure shows, matching configuration values and count for the searched keyword “url”.
Copy the fully qualified name of property key by clicking on key’s label as shown below.
The key name will be copied to clipboard.
gathr configuration settings are divided into various categories and sub-categories according to the component and technology.
Configurations properties related to application server, i.e. gathr web studio. This category is further divided into various sub-categories.
Field | Description |
|---|---|
StreamAnalytix UI Host | The IP address of gathr. |
StreamAnalytix Installation Directory | The installation directory of gathr. |
StreamAnalytix Web URL | The URL of gathr web studio. |
StreamAnalytix UI Port | The UI port of gathr. |
LogMonitoring UI Host ** | The host address of LogMonitoring. |
LogMonitoring UI Port ** | The port of LogMonitoring. |
Messaging Type | Specifies the Message Queuing System that application uses internally for messaging. Possible value is RABBITMQ (for RabbitMQ. |
StreamAnalytix Monitoring Reporters Supported | The monitoring reporter type and the possible values should be comma separated graphite, console and logger. |
Metric Server ** | Monitoring Metric Server (Graphite or Ambari). |
Field | Description |
|---|---|
Password | The database password. |
Driver Class | The database driver class name. |
Connection URL | The database URL for the database. |
User | The database username. |
Database Dialect | The type of database on which gathr database is created. Possible values are MySQL, PostgreSQL, Oracle. |
Field | Description |
|---|---|
Host List | The comma separated list of <IP>:<PORT> of all nodes in zookeeper cluster where configuration will be stored. |
Field | Description |
|---|---|
Indexer Type | The default indexer type. For e.g. - Solr or ElasticSearch. |
Index Default Replication Factor | Number of additional copies of data to be saved. |
Enable Index Default is Batch | Default value for the Batch parameter of indexing. |
Index Default Batch Size | Default batch size for the indexing store. |
Enable Index Default Across Field Search | Search without specifying column names, takes extra space and time. |
Index Default Number of Shards | Number of shards to be created in index store. |
Index Default Routing Required | The default value for the Routing parameter of indexing. |
Indexer Default Source | The default value for the Source parameter of indexing. |
Index Retries | The number of retries for indexing. |
Index Retries Interval(in ms) | The retries interval for the indexing when ingestion fails. |
Indexer time to live in seconds | Indexed data older than mentioned time in seconds from current time will not be fetched. |
Field | Description |
|---|---|
Persistence Store ** | The default persistence type. For e.g. - Hbase, Cassandra. |
Persistence Default Is batch Enable ** | Defines if by default batching should be enabled in persistence. |
Persistence Default Batch Size ** | The batch size for the persistence store. |
Persistence Default Compression ** | The default compression type for the persistence store. |
Description | |
|---|---|
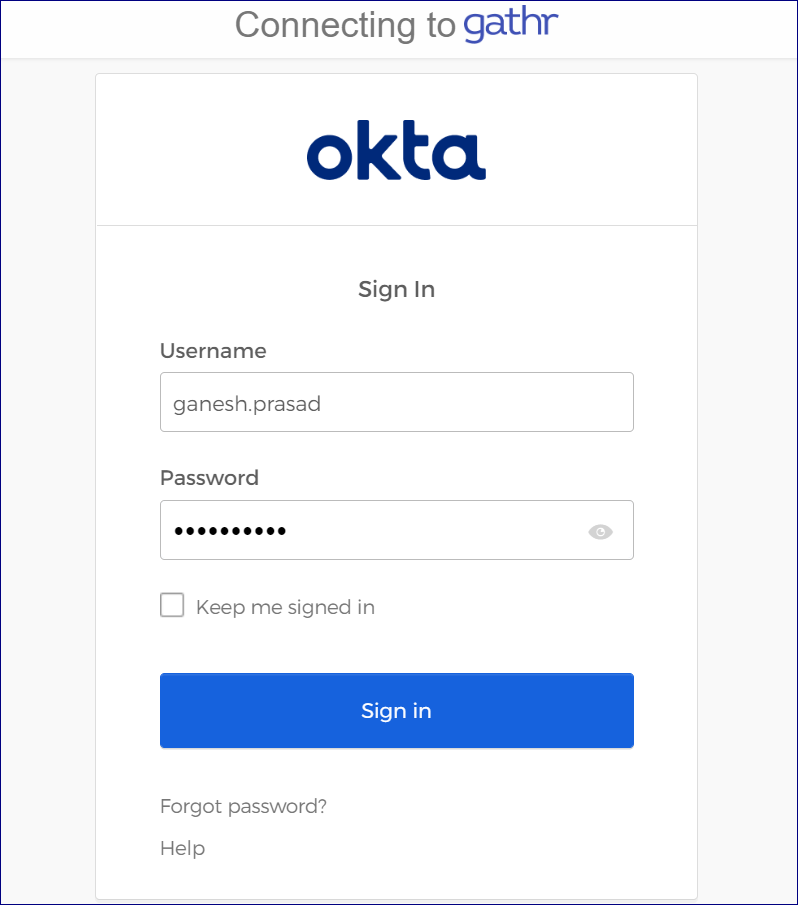
User Authentication Source | Options available for login into gathr application: LDAP Okta Gathr Metastore To authenticate user’s credentials while login gathr application, user can opt to authenticate login credentials using LDAP server, Okta, or Gathr metastore. Note: If configured with LDAP, user who is trying to login into the application should exist in LDAP server. Similarly, for enabling SSO (Single Sign On) in gathr, choose Okta as (Service provider)/User Authentication Source to verify the login credentials for application. Note: Upon logging into the environment, you will be redirected to Okta sign in page. Provide the username and password that is configured in LDAP.
|
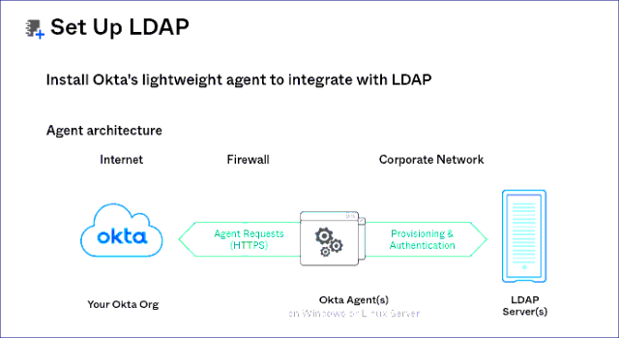
The prerequisites for Okta authentication are: In the LDAP server Group user mapping must be done accurately. For example, emailID, givenName. For Okta account, Application configuration, Application’s access management and LDAP directory integration must be done. Initially, the Gathr Role and LDAP role mapping should be done by login in the application in the embedded mode with superuser credentials and make the required changes. All the parameters including cn, sn, givenName, mail, uid, userPassword must be configured: So, mapping in LDAP is done by configuring LDAP Active Directory into Okta via. Okta agent that fetches the details from LDAP and the details are mapped in Okta. | |
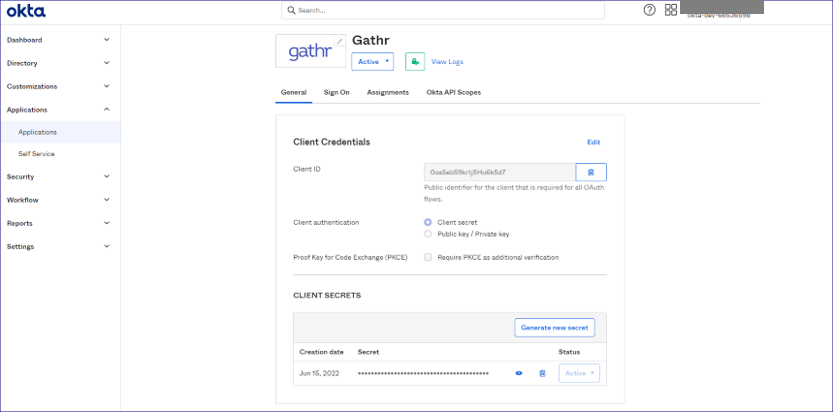
SSO in Okta Note: - Single Sign-On authentication allows users to login with a single ID within the software application without managing multiple accounts and passwords thus making it easier for admins to manage all users and privileges with one centralized admin dashboard. - Configure gathr application in Okta by providing Client credentials including details such as Client ID and secret key. User will be required to provide the details for gathr application Access Management in Okta.
- User will be required to install Okta Agent to be able to establish interaction between Okta and LDAP server. (The Okta agent can be installed in gathr/client end application, from where it can access the details of gathr application).
- Once Okta Agent is configured, provide LDAP server details. | |
User Authorization Source | Specify user's authorization mechanism, accordingly user will be assigned appropriate role in the gathr webstudio. Possible values are LDAP and gathr Metastore. Default value is gathr Metastore. Choose LDAP as User Authorization Source (defining the assigned roles within application. Example: superuser, custom user, workspace admin) if Okta is used for authentication. |
Superuser(Seed User) Authentication Source | Superuser authentication source needs to be selected. Currently, only gathr Metastore is supported as authentication source for Superuser. |
Field | Description |
|---|---|
SuperAdmin Password | The super admin password (Required to access the Dashboard UI). |
ReportClient path | The path of ReportClient.properties required to connect with Report Engine. |
Connection Name | The connection name created for gathr in Dashboard. |
Organization ID | The name of organization for gathr in Intellicus. |
SuperAdmin User ID | The Dashboard super user Username to access the Intellicus via UI. |
SuperAdmin Organization | The Dashboard superuser organization name, required to access Intellicus via UI. |
StreamAnalytix URL | The dashboard web admin URL, used for showing Dashboard UI from within gathr admin. |
Field | Description |
|---|---|
Databricks Enabled | To enable Databricks on this environment. |
Databricks Instance URL | Databricks Instance URL to connect databricks account and access it over REST calls. |
Databricks Authentication Token | Databricks Access token provided here will be associated with superuser account for gathr. It will be saved as encrypted text. |
Databricks DBFS Upload Jar Path | DBFS Path for the gathr specific jars and files. |
Maximum Polling Time (in minutes) | Maximum Polling Time. |
Polling Interval | Polling Interval (in seconds). |
Databricks Mediator Service URL | This is gathr web service URL for Databricks. |
Field | Description |
|---|---|
EMR Enabled | To enable EMR on this environment. |
Jar Upload Path | S3 Path for the gathr specific jars and files. |
Log URI | S3 Path for creating Logs for EMR Cluster launched by gathr. |
EMR Mediator Service URL | This is gathr webservice URL for EMR. |
Connect Using | Connect to the EMR cluster by using either AWS Keys or with the Instance Profile. |
AWS Key | AWS Access key to the associated gathr superuser account. |
AWS Secret Key | AWS Access key to the associated superuser account for gathr. It will be saved as encrypted text. |
Instance Profile | AWS Instance Profile to the associated superuser account for gathr. |
AWS Region | The region that the AWS EMR is to be launched in. |
Configurations properties related to application processing engines come under this category. This category is further divided into two sub-categories.
Field | Description |
|---|---|
Spark Livy URL ** | Livy web server URL through which gathr submit pipelines on Spark. |
Spark Home ** | The spark installation directory. |
Spark Master URL ** | It is the Spark Master URL for e.g. spark://host1:7077 |
Spark cluster manager ** | Defines spark cluster manager i.e. standalone or yarn. |
Spark Job Server Log Directory | Directory path where pipeline logs will be generated when using Spark Job server. |
Spark UI Port | It is the port on which the spark master UI is running. |
spark.history.server | The history server URL. |
Spark Hadoop is HDP | If your environment is HDP, set it to True, otherwise set it to false and use for setting proxy user |
Resource Manager Host | The resource manager hostname used for spark yarn deployment. |
Resource Manager Webapp Port | Yarn Resource Manager UI Port. |
Resource Manager Port | The resource manager port used for storm-yarn deployment. |
ResourceManager High Availability | Enables Resource Manager’s High Availability. |
ResourceManager HA Logical Names | ResourceManager High Availability Logical IDs defined at HA configuration. |
ResourceManager HA Hosts | ResourceManager High Availability host names defined at HA configuration. |
ResourceManager HA ZK Address | ResourceManager High Availability ZooKeeper-Quorum's address which is defined for HA configuration. |
Spark Job Submit Mode | Submit mode of Spark pipeline using Job-Server. |
Spark UI Host | Host name of the Spark Master. |
Job Server Spark Home | The spark installation directory with which Job Server is configured. |
Job Server URL | The host URL of Job Server. |
Spark REST Host and Port | Spark REST Host name and port for e.g Host1:6066 |
Spark Python Path | This environment variable is used to augment the default search path for Python module files. Directories and individual zip files containing pure Python modules can be added to this path. gathr uses this variable to find PySpark modules usually located at $SPARK_HOME/python/lib. |
Configurations properties related to messaging brokers come under this category. This category is further divided into three sub-categories.
Field | Description |
|---|---|
Password | RabbitMQ Password to create connection. |
Port | Port number of RabbitMQ. |
RabbitMQ STOMP URL | RabbitMQ stomp URL. |
Host List | IP address of the machine where RabbitMQ is running. |
RabbitMQ Virtual Host | The RabbitMQ virtual hosts. |
User | Username of RabbitMQ to create connection. |
RabbitMQ Web URL | Web URL of RabbitMQ. |
Field | Description |
|---|---|
Kafka Metadata Broker List ** | The list of comma separated IP:port of Kafka brokers. |
Kafka Zookeeper Server List ** | The list of comma separated IP:port of zookeeper for creating Kafka topic from gathr UI. |
Kafka Topic Administration ** | When set to true it specifies that with in the application a Kafka connection has permission to create topics in Kafka. |
Configuration properties related to NoSQL databases come under this category. This category is further divided into two sub-categories:
Field | Description |
|---|---|
HBase Zookeeper Host ** | The zookeeper host names used for HBase cluster. |
HBase Zookeeper Port ** | The zookeeper port for HBase cluster. |
HBase Client Retry Number ** | The number of retries for the HBase client. |
HBase Zookeeper Parent Node ** | Parent node in zookeeper for HBase service metadata. |
HBase Zookeeper Recovery Retry ** | The no. of times to retry the connection to HBase zookeeper. |
system-config.hbase.table.administration ** | When set to true it specifies that with in the application a HBase Default connection has permission to create tables and name spaces in HBase. |
Field | Description |
|---|---|
Cassandra Host List | Addresses of servers where Cassandra is running. |
Cassandra User | Username for Cassandra data store authentication. |
Cassandra Password | Password for Cassandra data store authentication. |
Cassandra Thrift Client Retry Count | The number of retries the Cassandra client will make to make a connection with server. |
Cassandra Thrift Client Delay Between Retries (in ms) | The time(in ms) after which the Cassandra client retries to make a connection to server. |
Cassandra Keyspace Replicaton Factor | Defines how many copies of the data will be present in the cluster. |
Cassandra Keyspace Replicaton Strategy | Strategy determines the nodes where replicas are placed. Simple Strategy places the first replica on a node determined by the partitioner. Additional replicas are placed on the next nodes clockwise in the ring without considering topology. |
Cassandra Connection Retry Count | Cassandra connection retry count. |
Configurations properties related to search engines come under this category. This category is further divided into two sub-categories:
Field | Description |
|---|---|
Enable Authentication | Select the check box, if Elasticsearch authentication is enabled. |
Elasticsearch Cluster Name | Name of the Elasticsearch cluster. |
Elasticsearch Connection URL | The http connection URL for Elasticsearch. |
Connection Timeout in secs | ElasticSearch connection timeout in seconds. |
Elasticsearch Embedded Data Directory | The data directory for running embedded Elasticsearch |
Elasticsearch Embedded Enable data | Defines either to store data into disk or memory (true for disk, false for memory). |
Elasticsearch Embedded Enable HTTP | Defines either the http connection is enabled or not for embedded Elasticsearch. |
Elasticsearch Embedded Enable local | The value of this field should be true. |
Elasticsearch Embedded Node Name | The node name of embedded as node. |
Elasticsearch HTTP Connection URL | The http connection URL for Elasticsearch. |
Elasticsearch HTTP Port | The port on which Elasticsearch REST URI is hosted. |
Keystore Password | Elasticsearch keystore password. |
Keystore Path | Elasticsearch keystore file (.p12) path. |
Request Timeout in secs | Request Retry Timeout for ElasticSearch connection in seconds. |
Enable Security | If security is enabled on Elasticsearch, set this to true. |
Socket Timeout in secs | Socket Timeout for ElasticSearch connection in seconds |
Enable SSL | Select the checkbox if SSL is enabled on Elasticsearch |
Username | Elasticsearch authentication username. |
Field | Description |
|---|---|
Solr Zookeeper Hosts | The Zookeeper hosts for the Solr server. |
Solr Configuration Version | Solr version number to create the zookeeper config node path for solr data. |
Configuration properties related to metric servers come under this category. This category is further divided into various sub-categories.
Field | Description |
|---|---|
Port | Port number of Graphite. |
Host | IP address of the machine where Graphite is running. |
UI Port | UI port number of Graphite. |
Field | Description |
|---|---|
Metric Collector Port | Ambari Metric Collector port. |
Metric Collector Host | Hostname where Ambari Metric Collector is running. |
Configuration properties related to Hadoop, i.e. gathr web studio, come under this category. This category is further divided into various sub-categories.
Field | Description |
|---|---|
Hive Meta Store URI ** | Defines the hive metastore URI. |
Hive Server2 JDBC URL ** | Password for HiveServer2 JDBC connection. In case no password is required pass it as empty(""). |
Hive Server2 Password ** | Defines the Hive server-2 password. |
Hive Warehouse Dir ** | Defines the warehouse directory path of Hive server. |
Field | Description |
|---|---|
Hadoop Enable HA | Hadoop cluster is HA enabled or not. |
File System URI | The file system URI. For e.g. - hdfs://hostname:port, hdfs://nameservice, file://, maprfs://clustername |
Hadoop User | The name of user through which the hadoop service is running. |
Hadoop DFS Name Services | The name service id of Hadoop HA cluster. |
Hadoop Namenode 1 Details | The RPC Address of namenode1. |
Hadoop Namenode 2 Details | The RPC Address of namenode2. |
Miscellaneous configurations properties left of the Web Studio. This category is further divided into various sub-categories.
Field | Description |
|---|---|
Password | Password against which the user will be authenticated in LDAP Server. |
Group Search Base | Defines the part of the directory tree under which group searches will be performed. |
User Search Base | Defines the part of the directory tree under which DN searches will be performed. |
User Search Filter | The filter which will be used to search DN within the User Search Base defined above. |
Group Search Filter | The filter which is used to search for group membership. The default is member={0 corresponding to the groupOfMembers LDAP class. In this case, the substituted parameter is the full distinguished name of the user. The parameter {1} can be used if you want to filter on the login name. |
Admin Group Name | LDAP group name which maps to application's Admin role. |
Developer Group Name | LDAP group name which maps to application's Developer role. |
Devops Group Name | LDAP group name which maps to application's Devops role. |
Tier-II Group Name | LDAP group name which maps to application's Tier-II role. |
LDAP Connection URL | URL of the LDAP server is a string that can be used to encapsulate the address and port of a directory server. For e.g. - ldap://host:port. |
User Distinguished Name | A unique name which is used to find the user in LDAP Server. |
Field | Description |
|---|---|
Alert Email Character Set | The character set used for sending emails. |
Alert Sender Email | The email address from which mails must be sent. |
JDBC Driver Class | The database driver used for activity setup. |
JDBC URL | The database URL for activity database. |
JDBC User | The database user name. |
JDBC Password | JDBC Password. |
Host | The email server host from which emails will be sent |
Port | The email server port. |
User | The email id from which emails will be sent. |
Password | The Password of the email account from which emails will be sent. |
Default Sender Email | The default email address from which mails will be sent if you do not provide one in the UI. |
Enable SSL | If SSL (Secure Sockets Layer) is enabled for establishing an encrypted link between server and client. |
Enable TSL | If Transport Layer Security (TLS) enables the encrypted communication of messages between hosts that support TLS and can also allow one host to verify the identity of another. |
History | Activiti history is needed or not. |
Database | The database used for activity setup. |
Field | Description |
|---|---|
Max Pool Size ** | The Couchbase Max Pool Size. |
Default Bucket Memory Size ** | The memory size of default bucket in Couchbase. |
Password ** | The Couchbase password. |
Default Bucket Replica No ** | The Couchbase default bucket replication number. |
Host Port ** | The port no. of Couchbase. |
Host Name ** | The host on which the Couchbase is running. |
HTTP URL ** | The Couchbase http URL. |
Bucket List ** | The Couchbase bucket list. |
Polling timeout ** | The polling timeout of Couchbase. |
Polling sleeptime ** | The sleep time between each polling. |
User Name ** | The username of the Couchbase user. |
Field | Description |
|---|---|
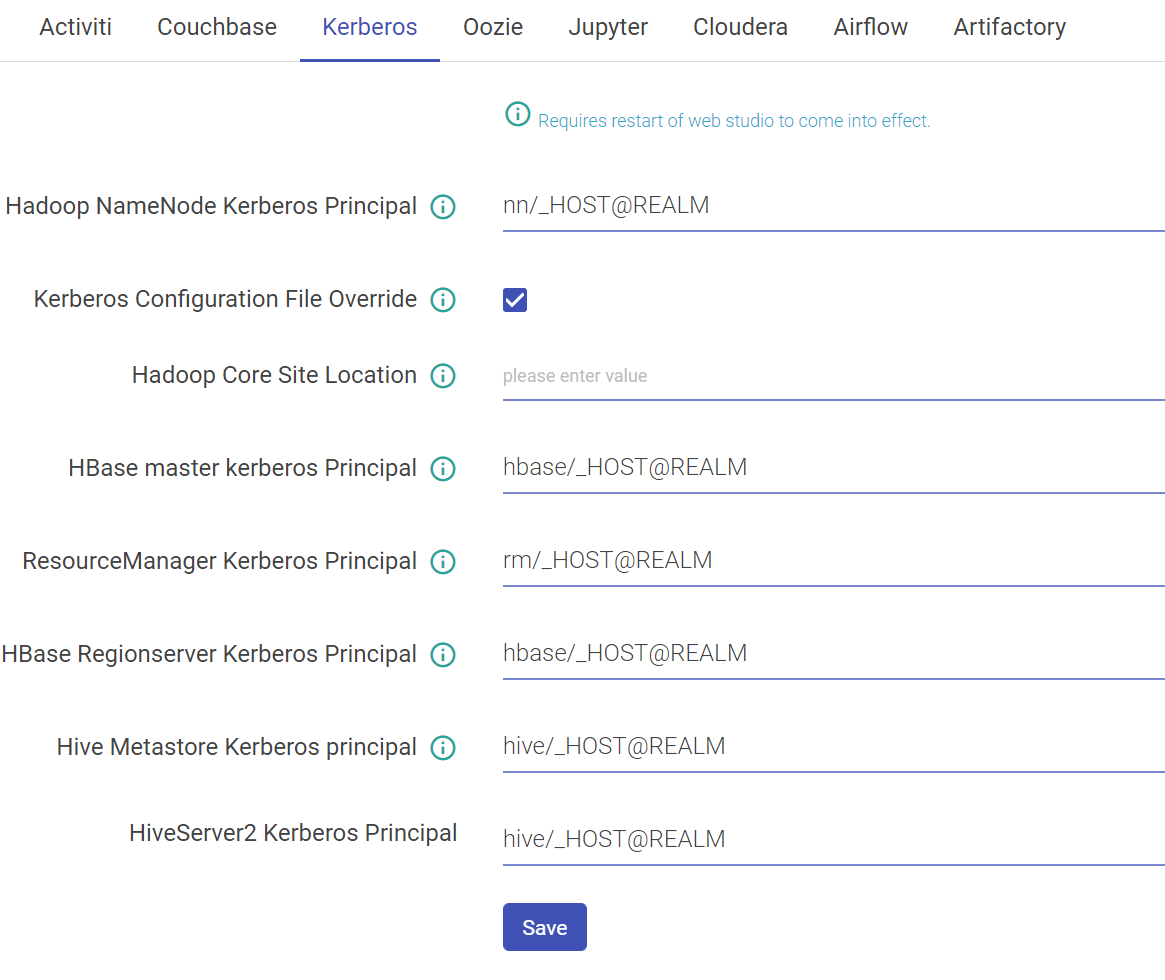
Hadoop NameNode Kerberos Principal | Service principal of name node. |
Kerberos Configuration File Override | Set to true if you want the keytab_login.conf file to be (re)created for every running pipeline when Kerberos security is enabled. |
Hadoop Core Site Location | The property should be used when trying to connect HDFS from two different realms. This property signifies the path of Hadoop core-site.xml containing roles for cross-realm communications. |
Hbase Master Kerberos Principal | Service principal of HBase master. |
ResourceManager Kerberos Principal | Service principal of resource manager |
Hbase Regionserver Kerberos Principal | Service principal of region server. |
Hive Metastore Kerberos principal | Service principal of Hive metastore. |
HiveServer2 Kerberos Principal | Service principal of hive server 2 |
You can add extra Java options for any Spark Superuser pipeline in following way:
Login as Superuser and click on Data Pipeline and edit any pipeline.
• Kafka
• HDFS
• HBASE
• SOLR
• Zookeeper
Configure Kerberos
Once Kerberos is enabled, go to Superuser UI > Configuration > Environment > Kerberos to configure Kerberos.
Configure Kerberos in Components
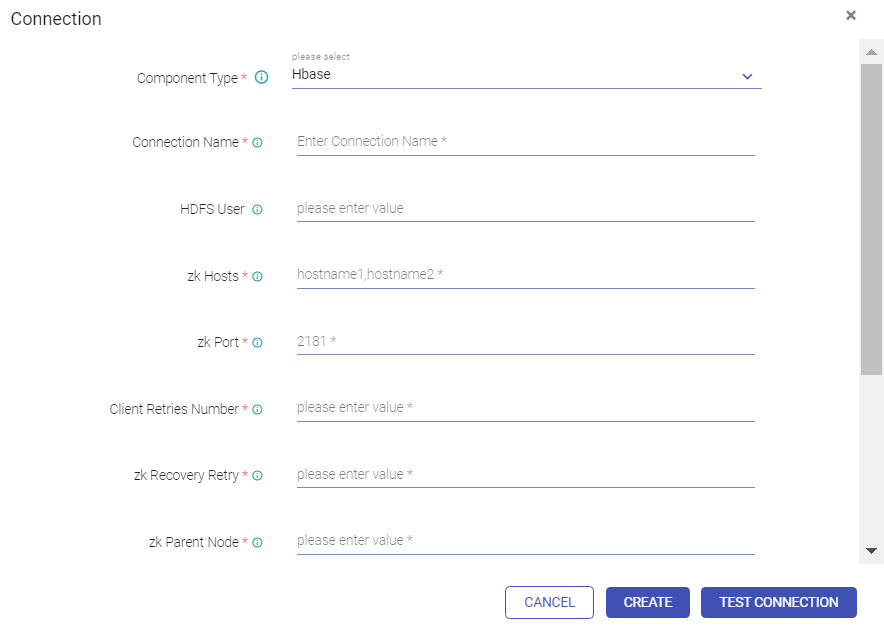
Go to Superuser UI > Connections, edit the component connection settings as explained below:
HBase, HDFS
Field | Description |
|---|---|
Key Tab Select Option | A Keytab is a file containing pair of Kerberos principals and encrypted keys. You can use Keytab to authenticate various remote systems. It has two options: Specify Keytab File Path: Path where Keytab file is stored Upload Keytab File: Upload Keytab file from your local file system. |
Specify Keytab File Path | If the option selected is Specify Keytab File Path, system will display the field KeyTab File Path where you will specify the keytab file location. |
Upload Keytab File | If the option selected is Upload Keytab File, system will display the field Upload Keytab File that will enable you to upload the Keytab file. |
By default, Kerberos security is configured for these components: Solr, Kafka and Zookeeper. No manual configuration required.
Note: For Solr, Kafka and Zookeeper, Security is configured by providing principals and keytab paths in keytab_login.conf. This file then needs to be placed in StreamAnalytix/conf/common/kerberos and StreamAnalytix/conf/thirdpartylib folders.
Description | |
|---|---|
jupyter.hdfs.port | HDFS Http port. |
jupyter.hdfs.dir | HDFS location where uploaded data will be saved. |
jupyter.dir | Location where notebooks will be created. |
jupyter.notebook.service.port | Port on which Auto create Notebook service is running. |
jupyter.hdfs.connection.name | HDFS connection name use to connect HDFS (from gathr connection tab). |
jupyter.url | URL contains IP address and port where Jupyter services are running. |
Description | |
|---|---|
Navigator URL | The Cloudera Navigator URL. |
Navigator API Version | The Cloudera Navigator API version used. |
Navigator Admin User | The Cloudera navigator Admin user. |
Navigator User Password | The Cloudera navigator Admin user password. |
Autocommit Enabled | Specifies of the auto-commit of entities is required. |
Description | |
|---|---|
Enable AWS MWAA | Option to enable AWS Managed Airflow for gathr. It is disabled by default. |
If Enable AWS MWAA is check-marked, additional fields will be displayed as given below: | |
Region | AWS region should be provided where MWAA environment is created. |
Provider Type | Option to choose AWS credentials provider type. |
AWS Access Key ID | AWS account access key ID should be provided for authentication if Provider Type is selected as AWS keys. |
AWS Secret Access Key | AWS account secret access key should be provided for the Access Key ID specified above. The available options to choose from the drop-down list are: None, AWS Keys and Instance Profile. |
Environment Name | Exact AWS environment name should be provided that is required to be integrated with gathr. |
StreamAnalytix Service URL | Default URL where gathr application is installed. This should be updated for any modifications done to the gathr base URL. |
DAG Bucket Name | Exact DAG bucket name should be provided that is configured in the environment specified above. |
DAG Path | DAG path should be provided for the bucket name specified above. |
If Enable AWS MWAA is un-check, the below fields will be displayed: | |
Airflow Server Token Name | It is the key that is used to authenticate a request. It should be same as the value given in section Plugin Installation>Authentication for property ‘sax_request_http_token_name’ |
Airflow Server Token Required | Check if the token is required. |
Airflow Server Token Value | HTTP token to authenticate request. It should be same as the value given in section Plugin Installation > Authentication for property ‘sax_request_http_token_value’ |
Airflow Server URL | Airflow URL to connect to Airflow. |
All default or shared kind of configurations properties come under this category. This category is further divided into various sub-categories.
Field | Description |
|---|---|
Application Logging Level | The logging level to be used for gathr logs. |
StreamAnalytix HTTPs Enabled | Whether gathr application support HTTPs protocol or not. |
Spark HTTPs Enabled | Whether Spark server support HTTPs protocol or not. |
Test Connection Time Out | Timeout for test connection (in ms). |
Java Temp Directory | The temp directory location. |
StreamAnalytix Reporting Period | Whether to enable View Data link in application or not. |
View Data Enabled | Whether to enable View Data link in application or not. |
TraceMessage Compression | The type of compression used on emitted TraceMessage from any component. |
Message Compression | The type of compression used on emitted object from any component. |
Enable StreamAnalytix Monitoring Flag | Flag to tell if monitoring is enabled or not. |
CEP Type | Defines the name of the cep used. Possible value is esper as of now. |
Enable Esper HA Global | To enable or disable HA. |
CepHA Wait Interval | The wait interval of primary CEP task node. |
StreamAnalytix Scheduler Interval | The topology stopped alert scheduler's time interval in seconds. |
Enable StreamAnalytix Scheduler | Flag to enable or disable the topology stopped alert. |
StreamAnalytix Session Timeout | The timeout for a login session in gathr. |
Enable dashboard | Defines whether dashboard is enable or disable. |
Enable Log Agent | Defines if Agent Configuration option should be visible on gathr GUI or not. |
Enable Storm Error Search | Enable showing pipeline Application Errors tab using LogMonitoring search page. |
StreamAnalytix Pipeline Error Search Tenant Token | Tenant token for Pipeline Error Search. |
StreamAnalytix Storm Error Search Index Expression | Pipeline application error index expression (time based is expression to create indexes in ES or Solr, that is used during retrieval also). |
Kafka Spout Connection Retry Sleep Time | Time between consecutive Kafka spout connection retry. |
Cluster Manager Home URL | The URL of gathr Cluster Manager |
StreamAnalytix Pipeline Log Location | gathr Pipeline Log Location. |
HDFS Location for Pipeline Jars | HDFS Location for Pipeline Jars. |
Scheduler Table Prefix | Tables name starting with a prefix which are related to storing scheduler's state. |
Scheduler Thread Pool Class | Class used to implement thread pool for the scheduler. |
Scheduler Thread Pool Thread Count | This count can be any positive integer, although only numbers between 1 and 100 are practical. This is the number of threads that are available for concurrent execution of jobs. If only a few jobs run a few times a day, then 1 thread is plenty. However if multiple jobs, with most of them running every minute, then you probably want a thread count like 50 or 100 (this is dependent on the nature of the jobs performed and available resources). |
Scheduler Datasource Max Connections | The maximum number of connections that the scheduler datasource can create in its pool of connections. |
Scheduler Misfire Threshold Time | Milliseconds the scheduler will tolerate a trigger to pass its next-fire-time by, before being considered misfired. |
HDP Version | Version of HDP ecosystem. |
CDH Version | Version of CDH ecosystem. |
Audit Targets | Defines the Audit Logging Implementation to be use in the application, Default is file. |
Enable Audit | Defines the value (true/false) for enabling audit in application. |
Persistence Encryption Key | Specifies the encryption key used to encrypt data in persistence. |
Ambari HTTPs Enabled | Whether Ambari server support HTTPs protocol or not. |
Graphite HTTPs Enabled | Whether Graphite server support HTTPs protocol or not. |
Elastic Search HTTPs Enabled | Whether Elasticsearch engine support HTTPs protocol or not. |
SQL Query Execution Log File Path | File location for logging gathr SQL query execution statistics. |
SQL Query Execution Threshold Time (in ms) | Defines the max limit of execution time for sql queries after which event will be logged (in ms). |
Lineage Persistence Store | The data store that will be used by data lineage feature. |
Aspectjweaver jar location | The absolute path of aspectweaver jar required for inspect pipeline or data lineage. |
Is Apache Environment | Default value is false. For all apache environment set it to "true". |
Field | Description |
|---|---|
Zookeeper Retry Count | Zookeeper connection retry count. |
Zookeeper Retry Delay Interval | Defines the retry interval for the zookeeper connection. |
Zookeeper Session Timeout | Zookeeper's session timeout time. |
Spark Description Model Registration Validation Timeout(in seconds) The time, in seconds, after which the MLlib, ML or H2O model registration and validation process will be failed if the process not complete. Spark Fetch Schema Timeout(in seconds) The time, in seconds, after which the fetch schema process of register table will be failed if the process not complete. Spark Failover Scheduler Period(in ms) Regular intervals to run scheduler tasks. Only applicable for testing connection of Data Sources in running pipeline. Spark Failover Scheduler Delay(in ms) Delay after which a scheduler task can run once it is ready. Only applicable for testing connection of Data Sources in running pipeline. Refresh Superuser Pipelines and Connections Whether to refresh Superuser Pipelines and Default Connections in database while web studio restart. Gathr SparkErrorSearchPipeline Index Expression ** Pipeline application error index expression (time based js expression to create indexes in ES or Solr, that is used during retrieval). Enable Spark Error Search ** Enabled to index and search spark pipeline error in LogMonitoring. Register Model Minimum Memory Minimum memory required for web studio to register tables, MLlib, ML or H2O models. Example -Xms512m. Register Model Maximum Memory Maximum memory required for web studio to register tables, MLlib, ML or H2O models. Example -Xmx2048m. H2O Jar Location Local file system's directory location at which H2O model jar will be placed after model registration. H2O Model HDFS Jar Location HDFS path location at which H2O model jar will be placed after model registration. Spark Monitoring Scheduler Delay(in ms) ** Specifies the Spark monitoring scheduler delay in milliseconds. Spark Monitoring Scheduler Period(in ms) ** Specifies the Spark monitoring scheduler period in milliseconds. Spark Monitoring Enable ** Specifies the flag to enable the spark monitoring. Spark Executor Java Agent Config Spark Executor Java Agent configuration to monitor executor process, the command includes jar path, configuration file path and Name of the process. Spark JVM Monitoring Enable ** Specifies the flag to enable the spark monitoring. ES query monitoring index name Provide the ES query monitoring index name which is required for indexing the data of query streaming. Scheduler period for es monitoring purging Scheduler period for es monitoring purging in seconds. Rotation policy for of ES monitoring graph Specify the rotation policy for index creation for ES monitoring graph (daily for a period of one day and weekly for 7 days). Purging duration of ES monitoring index Purge duration for ES in seconds for es monitoring graph index. Index created before this duration will be deleted. Enable purging scheduler for ES Graph monitoring Check the checkbox to enable purging scheduler for ES Graph monitoring. Spark Version ** By default the version is set to 2.3. Note: Set spark version to 2.2 for HDP 2.6.3” Livy Supported JARs Location ** HDFS location where livy related jar file and application streaming jar file have been kept. Livy Session Driver Memory ** Minimum memory that will be allocated to driver while creating livy session. Livy Session Driver Vcores ** Minimum virtual cores that will be allocated to driver while creating Livy session. Livy Session Executor Memory ** Minimum executor instances that will be allocated while executing while creating Livy seconds where sample data has been kept while schema auto detection. Livy Session Executor Vcores ** Minimum virtual cores that will be allocated to executor while creating Livy session. Livy Session Executor Instances ** Minimum executor instances that will be allocated while executing while creating Livy session.HDFS where sample data has been kept while schema auto detection. Livy Custom Jar HDFS Path ** The full qualified path of HDFS where uploaded custom jar has been kept while creating pipeline. Livy Data Fetch Timeout ** The query time interval in seconds for fetching data while data inspection. isMonitoringGraphsEnabled Whether monitoring graph is enabled or not. ES query monitoring index name this property stores the data of monitoring in this given index of default ES connection. Scheduler period for ES monitoring purging in this time interval purging scheduler will invoke and check whether the above index is eligible for purging (in sec.) (tomcat restart require). Rotation policy of ES monitoring graph “It can have two values daily or weekly” If daily index will be rotated daily else weekly means only a single day data will be stored in single index otherwise a data of a week will be stored in an index. Purging duration of ES monitoring index It’s a duration after which index will be deleted default is 604800 sec. Means index will be deleted after 1 week.” (tomcat restart requires) Enable purging scheduler for ES Graph monitoring If we need purging of index or not depend on this flag. Purging will not take place if flag is disable. It requires restart of Tomcat Server.
Field | Description |
|---|---|
RabbitMQ Max Retries | Defines maximum number of retries for the RabbitMQ connection. |
RabbitMQ Retry Delay Interval | Defines the retry delay intervals for RabbitMQ connection. |
RabbitMQ Session Timeout | Defines session timeout for the RabbitMQ connection. |
Real-time Alerts Exchange Name | Defines the RabbitMQ exchange name for real time alert data. |
Field | Description |
|---|---|
Kafka Message Fetch Size Bytes | The number of byes of messages to attempt to fetch for each topic-partition in each fetch request. |
Kafka Producer Type | Defines whether Kafka producing data in async or sync mode. |
Kafka Zookeeper Session Timeout(in ms) | The Kafka Zookeeper Connection timeout. |
Kafka Producer Serializer Class | The class name of the Kafka producer key serializer used. |
Kafka Producer Partitioner Class | The class name of the Kafka producer partitioner used. |
Kafka Key Serializer Class | The class name of the Kafka producer serializer used. |
Kafka 0.9 Producer Serializer Class | The class name of the Kafka 0.9 producer key serializer used. |
Kafka 0.9 Producer Partitioner Class | The class name of the Kafka 0.9 producer partitioner used. |
Kafka 0.9 Key Serializer Class | The class name of the Kafka 0.9 producer serializer used. |
Kafka Producer Batch Size | The batch size of data produced at Kafka from log agent. |
Kafka Producer Topic Metadata Refresh Interval(in ms) | The metadata refresh time taken by Kafka when there is a failure. |
Kafka Producer Retry Backoff(in ms) | The amount of time that the Kafka producer waits before refreshing the metadata. |
Kafka Producer Message Send Max Retry Count | The number of times the producer will automatically retry a failed send request. |
Kafka Producer Request Required Acks | The acknowledgment of when a produce request is considered completed. |
Field | Description |
|---|---|
Kerberos Sections | Section names in keytab_login.conf for which keytabs must be extracted from pipeline if krb.config.override is set to true. |
Hadoop Security Enabled | Set to true if Hadoop in use is secured with Kerberos Authentication. |
Kafka Security Enabled | Set to true if Kafka in use is secured with Kerberos Authentication. |
Solr Security Enabled | Set to true if Solr in use is secured with Kerberos Authentication. |
Keytab login conf file Path | Specify path for keytab_login.conf file. |
Field | Description |
|---|---|
Cloud Trial | The flag for Cloud Trial. Possible values are True/False. |
Cloud Trial Max Datausage Monitoring Size (in bytes) | The maximum data usage limit for cloud trial. |
Cloud Trial Day Data Usage Monitoring Size (in bytes) | The maximum data usage for FTP User. |
Cloud Trial Data Usage Monitoring From Time | The time from where to enable the data usage monitoring. |
Cloud Trial Workers Limit | The maximum number of workers for FTP user. |
FTP Service URL | The URL of FTP service to create the FTP directory for logged in user (required only for cloud trial). |
FTP Disk Usage Limit | The disk usage limit for FTP users. |
FTP Base Path | The base path for the FTP location. |
Enable Monitoring Graphs | Set to True to enable Monitoring and to view monitoring graphs. |
QueryServer Monitoring Flag | Defines the flag value (true/false) for enabling the query monitoring. |
QueryServer Moniting Reporters Supported | Defines the comma-separated list of appenders where metrics will be published. Valid values are graphite, console, logger. |
QueryServer Metrics Conversion Rate Unit | Specifies the unit of rates for calculating the queryserver metrics. |
QueryServer Metrics Duration Rate Unit | Specifies the unit of duration for the queryserver metrics. |
QueryServer Metrics Report Duration | Time period after which query server metrics should be published. |
Query Retries | Specifies the number of retries to make a query in indexing. |
Query Retry Interval (in ms) | Defines query retry interval in milliseconds. |
Error Search Scroll Size | Number of records to fetch in each page scroll. Default value is 10. |
Error Search Scroll Expiry Time (in secs) | Time after which search results will expire. Default value is 300 seconds. |
Index Name Prefix | Prefix to use for error search system index creation. The prefix will be used to evaluate exact index name with partitioning. Default value is sax_error_. |
Index number of shards | Number of shards to create in the error search index. Default value is 5. |
Index Replication Factor | Number of replica copies to maintain for each index shard. Default value is 0. |
Index Scheduler Frequency (in secs) | Interval (in secs) after which scheduler will collect error data and index in index store. |
Index Partitioning Duration (in hours) | Time duration after which a new index will be created using partitioning. Default value is 24 hours. |
Data Retention Time (in days) | Time duration for retaining old data. Data above this threshold will be deleted by scheduler. Default value is 60 days. |
Description | Default Value | |
|---|---|---|
Enable Event Auditing | Defines the value for enabling events auditing in the application. | true |
Events Collection Frequency (in secs) | Time interval (in seconds) in which batch of captured events will be processed for indexing. | 10 |
Events Search Scroll size | Number of records to fetch in each page scroll on result table. | 100 |
Events Search Scroll Expiry (in secs) | Time duration (in seconds) for search scroll window to expire. | 300 |
Events Index Name Prefix | Prefix string for events index name. The prefix will be used to evaluate exact target index name while data partitioning process. | sax_audit_ |
Events Index Number of Shards | Number of shards to create for events index. | 5 |
Events Index Replication Factor | Number of replica copies to maintain for each index shard. | 0 |
Index Partitioning Duration (in hours) | Time duration (in hours) after which a new index will be created for events data. A partition number will be calculated based on this property. This calculated partition number prefixed with Events Index Name Prefix value will make target index name. | 24 |
Events Retention Time (in days) | Retention time (in days) of data after which it will be auto deleted. | 60 |
Events Indexing Retries | Number of retries to index events data before sending it to a WAL file. | 5 |
Events Indexing Retries Interval (in milliseconds) | It defines the retries interval (in milliseconds) to perform subsequent retries. | 3000 |
Field | Description |
|---|---|
QueryServer Monitoring Flag | The flag value (true/false) for enabling the query monitoring. |
QueryServer Monitoring Reporters Supported | The comma-separated list of appenders where metrics will be published. Valid values are graphite, console, logger. |
QueryServer Metrics Conversion Rate Unit | Specifies the unit of rates for calculating the queryserver metrics. |
QueryServer Metrics Duration Rate Unit | Specifies the unit of duration for the queryserver metrics. |
QueryServer Metrics Report Duration | Time after which query server metrics should be published. |
QueryServer Metrics Report Duration Unit | The units for reporting query server metrics. |
Query Retries | The number of retries to make a query in indexing. |
Query Retry Interval (in ms) | Defines query retry interval in milliseconds. |
Description | |
|---|---|
Audit Targets | Defines the audit logging implementation to be used in the application, Default is fine. |
ActiveMQ Connection Timeout(in ms) | Defines the active MQTT connection timeout interval in ms. |
MQTT Max Retries | Max retries of MQTT server. |
MQTT Retry Delay Interval | Retry interval, in milliseconds, for MQTT retry mechanism. |
JMS Max Retries | Max retries of JMS server. |
JMS Retry Delay Interval | Retry interval, in milliseconds, for JMS retry mechanism. |
Metrics Conversion Rate Unit | Specifies the unit of rates for calculating the queryserver metrics. |
Metrics Duration Rate Unit | Specifies the unit of duration for the metrics. |
Metrics Report Duration | Specifies the duration at interval of which reporting of metrics will be done. |
Metrics Report Duration Unit | Specifies the unit of the duration at which queryserver metrics will be reported. |
Gathr Default Tenant Token | Token of user for HTTP calls to LogMonitoring for adding/modifying system info. |
LogMonitoring Dashboard Interval(in min) | Log monitoring application refresh interval. |
Logmonitoring Supervisors Servers | Servers dedicated to run LogMonitoring pipeline. |
Export Search Raw Field | Comma separated fields to export LogMonitoring search result. |
Elasticsearch Keystore download path prefix | Elasticsearch keystore download path prefix in case of uploading keystore. |
Tail Logs Server Port | Listening port number where tail command will listen incoming streams of logs, default is 9001. |
Tail Logs Max Buffer Size | Maximum number of lines, that can be stored on browser, default is 1000. |
sax.datasets.profile.frequency.distribution.count.limit | Defines the number of distinct values to be shown in the frequency distribution graph of a column in a Dataset. |
sax.datasets.profile.generator.json.template | common/templates/DatasetProfileGenerator.json Template of the spark job used to generate profile of a Dataset. |
Pipeline Error Notification Email IDs | Provide comma separated email IDs for pipeline error notification. |
Pipeline Test Connection Enabled | Check mark the checkbox to enable the email notification when a pipeline component is down. |
Maintenance mode enabled | Provide true or false value for enabling the email notification in case pipeline component stops working. |
Contextual Logs | A detailed contextual information (e.g. userName, roles, projectName) will be appended in the logs once this option is enabled. |
Enable Event Notifier | Check this option to enable event notification based on the provided event notifier type. For example: SNS. |
Event Notifier Type | Provide the event notifier type i.e., SNS |
SNS Authentication Type | Select the AWS Authentication Type from the available options: - AWS Keys - Instance Profile - Role ARN |
AWS Key ID | Provide the AWS account access key. |
AWS Secret Key | Provide the AWS account secret key. |
SNS Topic Region | Provide the AWS SNS topic region. |
SNS Topic Type | Select the SNS topic type from the below available options: - Standard - FIFO |
SNS Topic ARN | Provide the SNS topic ARN where you want to publish alert data i.e., arn:aws:sns:us-east-1:123456789012:Test. |
Role ARN | Provide the AWS account Role ARN. |
Message Group ID | Provide message group ID for the FIFO SNS topic. |
Connections allow gathr to connect to services like ElasticSearch, JDBC, Kafka, RabbitMQ and many more. A user can create connections to various services and store them in gathr application. These connections can then be used while configuring the services in various features of gathr which require these services connection details, for e.g., Data Pipelines, Dataset, Application.
To navigate to the Superuser Connections page, the user can click on the Connections feature which is available in the gathr main menu.
The default connections are available out-of-box once you install the application. All the default connections expect RabbitMQ are editable.
The user can use these connections or create new connections.
A superuser can create new connections using the Connections tab. To add a new connection, follow the below steps:
• Login as a Superuser.
• Go to Connections page.
• Click on Add Connection.
Select the component from the drop-down list for which you wish to create a connection.
For creating an ADLS connection, select ADLS from the Component Type drop-down list and provide connection details as explained below:
Field | Description |
|---|---|
Component Type | Shows all the available connections. Select ADLS from the drop-down list. |
Connection Name | Provide a connection name to create the connection. |
Account Name | Provide the valid storage account name. |
Authentication Type | Select authentication type. The available options are mentioned below: - Azure AD - Access Key - Credential Passthrough |
Upon selecting Azure AD, provide the below fields: | |
Client ID | Provide a valid client ID. |
Secret Client | Provide a valid client secret password. |
Directory ID | Provide a valid directory ID. |
Upon selecting Access Key, provide the below fields: | |
Account Key | Provide a valid storage account key. |
The Credential Passthrough option allows you to authenticate automatically to Azure Data Lake Storage from Azure Databricks clusters using the identity that you use to log in to Azure Databricks. | |
For creating a AWS IoT connection, select AWS IoT from the Component Type drop-down list and provide connection details as explained below.
Field | Description |
|---|---|
Component Type | Shows all the available connections. Select AWS IoT Component type from the list. |
Connection Name | Name of the connection. For example, AWSIoT. |
AWS KeyId | This is the AWS Key i.e. the credential to connect to AWS console. |
Secret Access Key | This is AWS secret access key, to access AWS services. |
Client EndPoint | AWS IoT Client End Point, which is unique for IoT. |
Role ARN | User role ARN. It is used to create rules. |
Region | AWS Region. |
Connection ClientId | Any stream name. |
For creating a Azure Blob connection, select Aure Blob from the Component Type drop-down list and provide connection details as explained below:
Field | Description |
|---|---|
Component Type | Shows available connections. |
Connection Name | Name of the connection. For example, Cassandra. |
Azure Blob Connection String | Azure Blob connection String. |
For creating a Cassandra connection, select Cassandra from the Component Type drop-down list and provide connection details as explained below:
Field | Description |
|---|---|
Component Type | Shows available connections. |
Connection Name | Name of the connection. For example, Cassandra |
Hosts | Hosts name and ports of Cassandra machine (comma separated). |
Connection Retries | Number of retries for component connection. |
Authentication Enabled | Enable if authentication is enabled in Cassandra. |
Username | Username for Cassandra data store authentication |
Password | Password for Cassandra data store authentication |
Test Connection | After entering all the details, click on the Test Connection button. If credentials are correct, a successful connection message is generated. If you enter wrong credentials or server is down, you will get the a Connection unavailable message. |
For creating a Cosmos connection, select Cosmos from the Component Type drop-down list and provide connection details as explained below:
Field | Description |
|---|---|
Component Type | Shows all the available connections. |
Connection Name | Name of the connection. |
Cosmos Endpoint URI | End point URI of Azure Cosmos DB Account. |
Key | Provide the Azure Cosmos DB Key. |
Consistency Level | Consistency levek in Azure Cosmos DB. If the user selects Default option then the Cosmos DB account level consistency will be used as configured on the azure portal of Cosmos DB. User can alternately select the Eventual consistency option for read operations instead of using the default account level consistency. |
TEST CONNECTION | After entering all the details, click on the Test Connection button. If credentials are correct, a successful connection message is generated. If you enter wrong credentials or server is down, you will get the a Connection unavailable message. |
For creating a Couchbase connection, select Couchbase from the Component Type drop-down list and provide connection details as explained below:
Field | Description |
|---|---|
Component Type | Shows available connections. |
Connection Name | Name of the connection. |
Hosts | Hosts name and ports of Couchbase machine (comma separated). |
Username | Username for Couchbase datastore authentication. |
Password | Password for Couchbase datastore authentication. |
Note: If Spark SSL is enabled, in case of standalone click the + ADD CONFIGURATION button and provide the key-value pair for com.couchbase.sslEnabled as false. | |
Test Connection | After entering all the details, click on the Test Connection button. If credentials are correct, a successful connection message is generated. If you enter wrong credentials or server is down, you will get the a Connection unavailable message. |
For creating an Elasticsearch connection, select Elasticsearch from the Component Type drop-down list and provide connections details as explained below.
Field | Description |
|---|---|
Component Type | Shows available connections. Select EFS Component type from the list. |
Connection Name | Connection name to create. |
Directory Path | Enter mounted root directory EFS. |
For creating an Elasticsearch connection, select Elasticsearch from the Component Type drop-down list and provide connections details as explained below.
Field | Description |
|---|---|
Component Type | Shows available connections. Select Elasticsearch Component type from the list. |
Connection Name | Name of the connection. For example, Elasticsearch |
Hosts | Hosts name and ports of Elasticsearch machine. |
http Port | Port number where elastic search is running. |
Zone | Defines the zone of Elastic Search cluster. |
Cluster Name | The name of the cluster to which elastic search will connect. |
Connection Timeout secs | Maximum time taken by the client to connect to the Elasticsearch server (unit seconds). |
Socket Timeout secs | If the continuous incoming data flow did not occur for a specified period of time, socket timeout connection occurs (unit seconds). |
Request Retry Timeout secs | Sets the maximum timeout in case of multiple retries of same request. |
Enable Security | Enable X-Pack security plugin for Elasticsearch authentication. |
Enable SSL | If security is enabled on Elasticsearch, set this to true. |
Keystore select option | Specify keystore path: Specify the Elasticsearch keystore file (.p12) path. Upload keystore path: Upload the Elasticsearch keystore file (.p12) path. |
Keystore file path | Mention the Elasticsearch keystore file (.p12) path. |
Keystore password | Keystore password. |
Enable Authentication | Select the checkbox if Authentication is enabled on Elasticsearch. |
Username | Elasticsearch authentication username. |
Password | Elasticsearch authentication password. |
For creating an EventBridge, select EventBridge from the Component Type drop-down list and provide connections details as explained below.
Field | Description |
|---|---|
Component Type | Shows available connections. Select Elasticsearch Component type from the list. |
Connection Name | Name of the connection. For example, EventBridge. |
Connect Using | Options to connect using AWS Key or Instance Profile. |
Upon selecting AWS, provide the below details: | |
AWS KeyID | Provide the AWS account access key. |
Secret Access Key | Provide the AWS account secret key. |
AWS Region | Specify region for AWS EventBridge service. |
Upon selecting the Instance Profile option provide the below detail: | |
AWS Region | Specify region for AWS EventBridge service. |
Note: For using BigQuery, GCS and Pubsub components, you can use the GCP connection.
To access GCP services, it is mandatory to Generate Service Account Key with below permission for read and write.
Big query:
For the BigQuery Data Sources and Emitters to run successfully in Gathr applications, the following permissions/policy actions should be assigned in Google Cloud:
bigquery.datasets.get
bigquery.jobs.create
bigquery.jobs.delete
bigquery.jobs.get
bigquery.jobs.list
bigquery.jobs.listAll
bigquery.jobs.listExecutionMetadata
bigquery.jobs.update
bigquery.tables.create
bigquery.tables.create
bigquery.tables.getData
bigquery.tables.list
bigquery.tables.update
bigquery.tables.updateData
storage.buckets.get
storage.buckets.create
storage.buckets.list
storage.objects.create
storage.objects.delete
storage.objects.get
storage.objects.list
GCS:
For the GCS Data Sources and Emitters to run successfully in Gathr applications, the following permissions/policy actions should be assigned in Google Cloud:
storage.buckets.get
storage.buckets.create
storage.buckets.list
storage.objects.create
storage.objects.delete
storage.objects.get
storage.objects.list
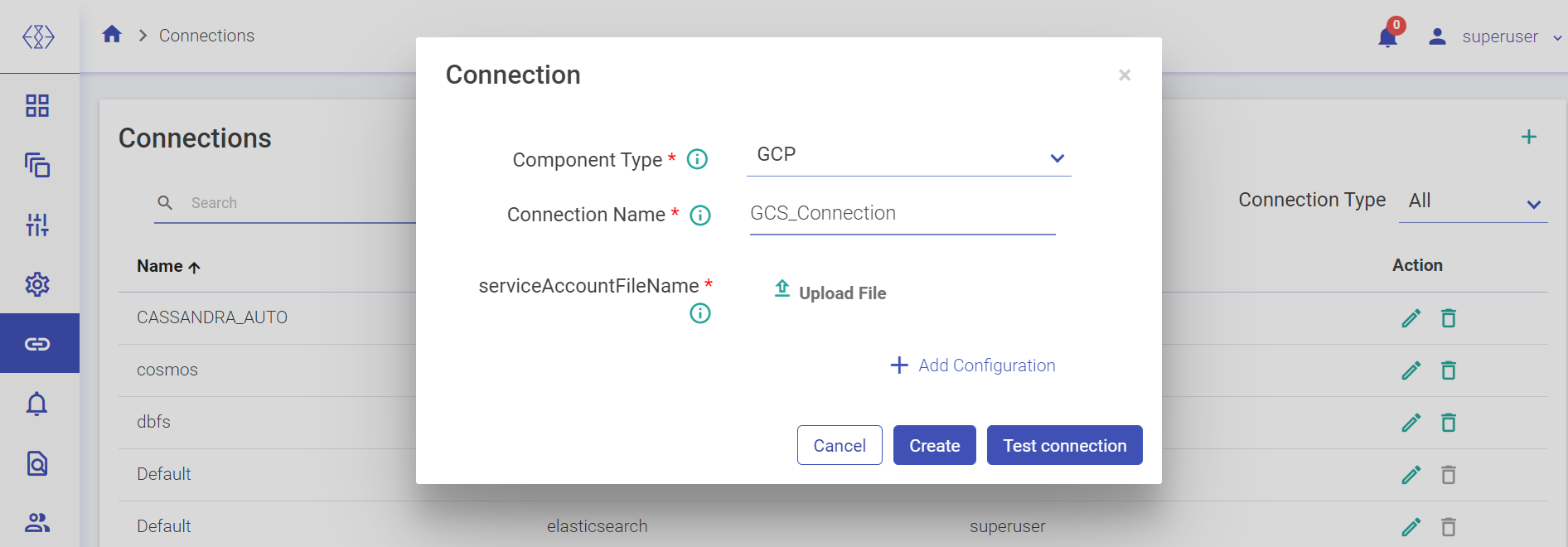
Field | Description |
|---|---|
Component Type | The selected component type is reflected here which is GCP in this case. |
Connection Name | Mention the connection name. |
Service Account Key | Upload the service account key. |
Note: The user can add further configuration by clicking at the +Add Configuration button.
After entering all the details, click on the Test Connection button to validate if the connection is running properly.
Click on Create button to save the changes.
For using GCP Connection in gathr, generate service account key.
Note: In order to access the GCP account, make sure to have the permission to access the service account key.
See the sub-topic Generate Service Account Key to know the steps required for generating Service Account ID and Service Account Key for upload.
You must have a Google account to access the GCP services.
Steps required to generate service account key
Follow these steps in GCP to allow Gathr the access to your GCP Component:
- Create a Service Account and key
- Enable the required APIs
Each of these steps are explained below:
Steps to generate Service Account ID and Key:
1. Use the below link to access/create Google account.
https://console.cloud.google.com/iam-admin/serviceaccounts
2. Sign in to GCP.
3. Create a new project to proceed further. Else, use any existing project to continue.
4. Navigate to IAM & Admin section and click on the Service Accounts option.
5. On the Service Accounts page, click on the CREATE SERVICE ACCOUNT option as shown below:
6. Provide the service account details and click CREATE AND CONTINUE.
7. (Optional steps) Grant the service account access to project and users.
Click Done.
8. The created service account will be listed on the Service accounts page along with the available ones (if any).
This Service Account ID should be provided in Gathr during the GCP connection configuration.
Click on the ellipses under Actions and select Manage Keys.
9. Click on ADD KEY to create a new key or download an existing key.
Choose a key type from the available options, JSON or P12, and click CREATE.
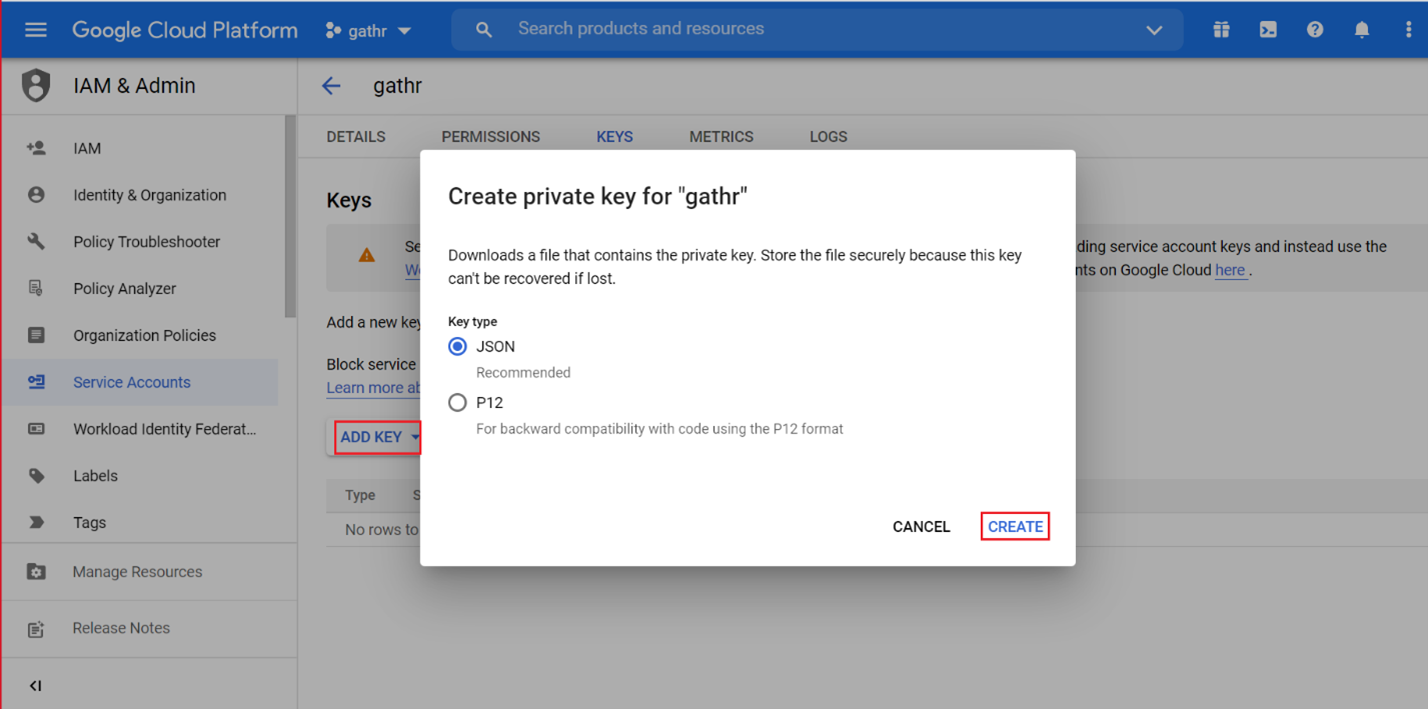
The created Private key will be downloaded and saved locally.
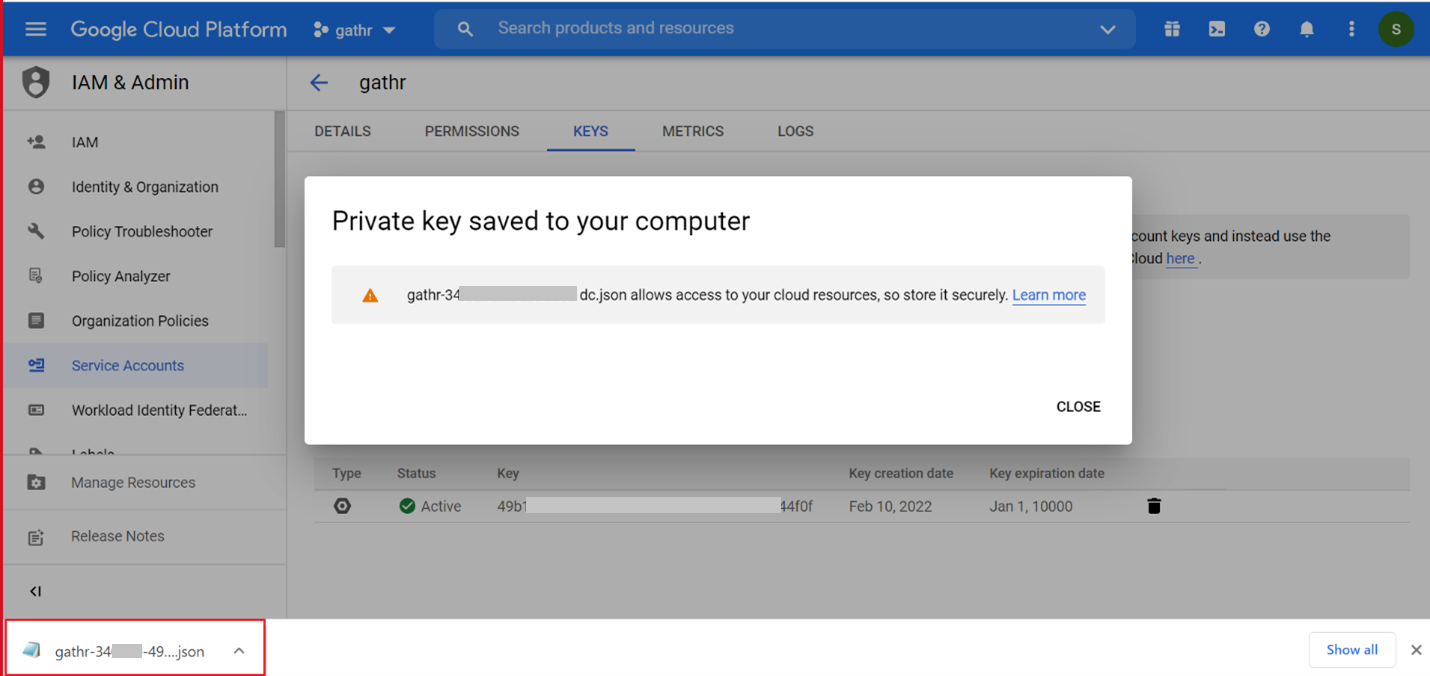
This Private Key file should be uploaded in Gathr during the GCP connection configuration.
Note: For using the Pubsub, BigQuery and GCS components the GCP connection is used:. However, for accessing SpreadSheet component you need to create a service account key using below steps:
Enable Google Sheets API and Drive API
Note: This step is mandatory for Gathr to have access to your Google Sheets.
1. Search for APIs & Services on Google console or follow the link given below:
https://console.cloud.google.com/apis
2. Click on ENABLE APIS AND SERVICES option.
3. On the API Library page, search and open google sheets api
4. On the Google Sheets API page, click on ENABLE.
A confirmation will appear once the Google Sheets API is enabled.
5. On the API Library page, search and open google drive api.
6. On the Google Drive API page, click on ENABLE.
A confirmation will appear once the Google Drive API is enabled.
Share Spreadsheet with Service Account ID
1. Navigate to Google Sheets and open a spreadsheet.
2. Share you Google Spreadsheet with the created Service Account.
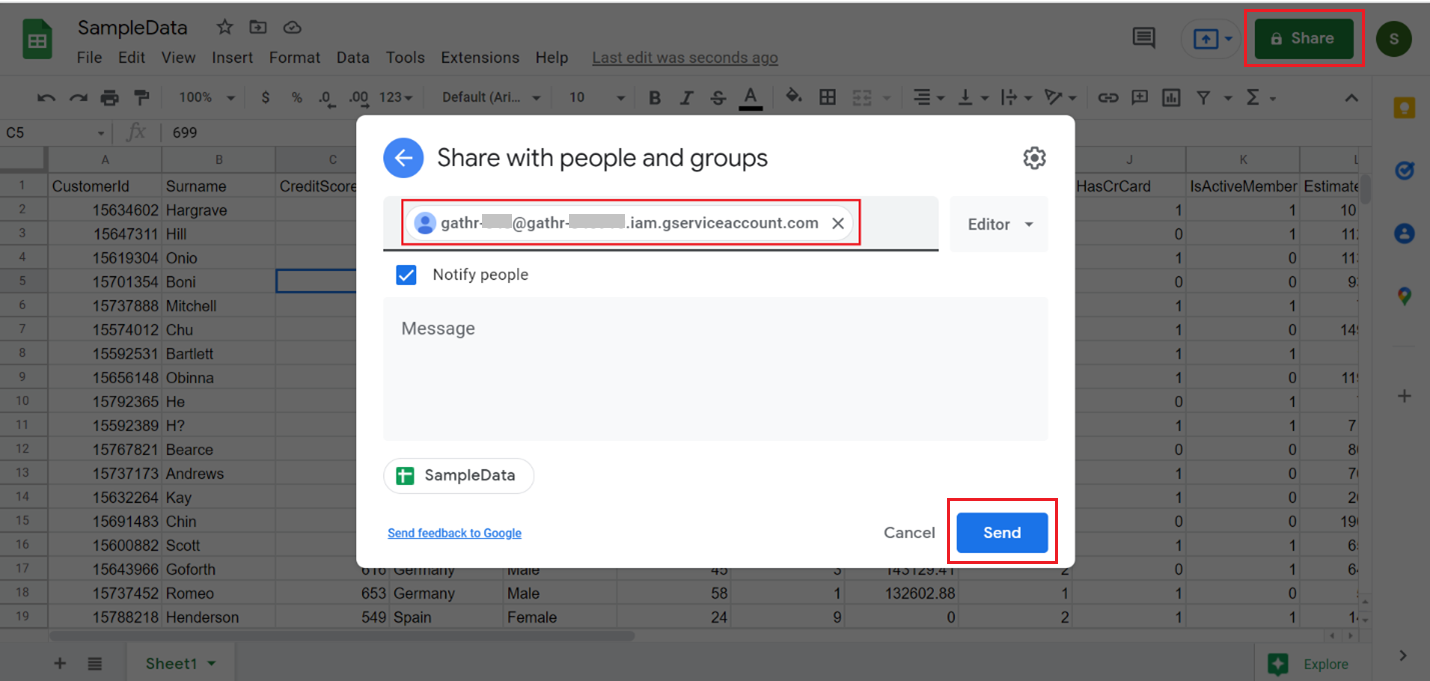
Note: Make sure to share a google sheet and not any other file type.
After completing all the required steps navigate to Gathr console and provide the necessary details to create the connection.
Click below link to know more about how to create and manage service account keys using the Google Cloud Console.
https://cloud.google.com/iam/docs/creating-managing-service-account-keys
For creating Google Spreadsheet connection, select Google Spreadsheet option from the Component Type drop down list and provide connection details as explained below:
Field | Description |
|---|---|
Component Type | Select the component type from the drop-down list. i.e., Google Spreadsheet in this case. |
Connection Name | Unique name of the connection to be created. |
Service Account ID | Provide the google service account ID. |
Service Account Key Type | Preferred service account key type should be selected for authentication. |
Upload File | Upload file with service account credentials as per the service account key type selected above. |
See the topic Generate Service Account Key to know the steps required for generating Service Account ID and Service Account Key for upload.
Enable Google Sheet API and Drive API
Note: This step is mandatory for Gathr to have access to your Google Sheets.
1. Search for APIs & Services on Google console or follow the link given below:
https://console.cloud.google.com/apis
2. Click on ENABLE APIS AND SERVICES option.
3. On the API Library page, search and open google sheets api
4. On the Google Sheets API page, click on ENABLE.
A confirmation will appear once the Google Sheets API is enabled.
5. On the API Library page, search and open google drive api.
6. On the Google Drive API page, click on ENABLE.
A confirmation will appear once the Google Drive API is enabled.
Share Spreadsheet with Service Account ID
1. Navigate to Google Sheets and open a spreadsheet.
2. Share you Google Spreadsheet with the created Service Account.
Note: Make sure to share a google sheet and not any other file type.
After completing all the required steps navigate to Gathr console and provide the necessary details to create the connection.
Click below link to know more about how to create and manage service account keys using the Google Cloud Console.
https://cloud.google.com/iam/docs/creating-managing-service-account-keys
For creating an Hbase connection, select Hbase from the Component Type drop-down list and provide connections details as explained below.
Field | Description |
|---|---|
Component Type | Shows all different types of available connections. Select HBase Component type from the list. |
Connection Name | Name of the connection. For example, HBase |
HDFS User | HDFS user name. |
zK Host | Zookeeper host name for Hbase cluster. |
zK Port | Zookeeper port for Hbase cluster. |
Client Retries Number | Number of retries for the Hbase Client. For example, 2. |
zk Recovery Retry | Number of retries to reconnect to HBase Zookeeper. |
zk Parent Node | Parent node in Zookeeper for Hbase service metadata. |
Table Administration | Enable this if you want to create table in Hbase. |
Create | Click on the Create button to create the connection. |
Test Connection | After entering all the details, click on the Test Connection button, if credentials provided are correct, services are up, and running, you will get the message Connection is available. If you enter wrong credentials or server is down and you click on Test Connection, you will get the message Connection unavailable. |
For creating a HDFS connection, select HDFS from the Component Type drop-down list and provide connections details as explained below.
Field | Description |
|---|---|
Component Type | Shows all different types of available connections. Select HDFS Component type from the list. |
Connection Name | Name of the connection. For example, HDFS. |
File System URI | File System URI of the machine where HDFS installed. |
Username | The name of the user through which Hadoop user is running. |
HA Enabled | Hadoop cluster is HA Enabled or not. |
Name Node1 Name | NameNode1 identifier/label. |
Name Node1 RPC Address | RPC Address of the Name Node1. |
Name Node2 Name | NameNode2 identifier/label. |
Name Services | Name service id of Hadoop cluster. |
Create | Click on the Create button to create the connection. |
Test Connection | After entering all the details, click on the Test Connection button, if credentials provided are correct, services are up, and running, you will get the message Connection is available. If you enter wrong credentials or server is down and you click on Test Connection, you will get the message Connection unavailable. |
For creating a HIVE Emitter connection, Select HIVE Emitter from the Component Type drop-down list and provide connections details as explained below.
Field | Description |
|---|---|
Component Type | Shows all the available connections. Select HIVE Emitter Component type from the list. |
Connection Name | Name of the connection. |
MetaStore URI | Thrift URI to connect to HIVE Metastore service. |
Hive Server2 URL | Defines the Hive server 2 JDBC URL. i.e. jdbc:hive2://<host>:<port>/default;principal=<principal>; ssl=<true/false>;sslTrustStore=<truststorepath>;trustStorePassword=<pass>;sslKeyStore=<keystorepath>; keyStorePassword=<pass>; transportMode=<http/binary>;httpPath=cliservice Please view the note below the table. |
HiveServer2 Password | Password for HiveServer2 JDBC connection. If there is no password, leave it blank. |
FileSystem URI | HDFS File System URI |
UserName | HDFS User name authorized to access the services. |
HA Enabled | Check this option, if Name Node of HDFS is HA enabled. |
KeyTab Select Option | You can add extra Java options for any Spark Superuser pipeline in following way: 1. Login as Superuser and click on Data Pipeline and edit any pipeline. Upload key tab file: Enables to upload Key tab file for authentication. Depending on the option selected. |
Specify keytab file path | If the option selected is Specify Keytab File Path, system will display the field KeyTab File Path where you will specify the keytab file location. |
Upload key tab file | If the option selected is Upload Keytab File, system will display the field Upload Keytab File that will enable you to upload the keytab file. |
Hive Zookeeper Quorum** | Zookeeper hosts used by LLAP. For example: host1:2181;host2:2181;host3:2181 |
Hive Daemon Service Hosts** | Application name for LLAP service. For example @llap0 |
Hive Warehouse Load Staging Directory** | Temp directory for batch writes to Hive. For e.g /tmp |
Table Administration | Enable this if you want to create table in Hive Emitter. |
Create | Click on the Create button to create the connection. |
Test Connection | After entering all the details, click on the Test Connection button. If credentials are correct, a successful connection message is generated. If you enter wrong credentials or server is down, you will get the a Connection unavailable message. |
Note:
** Properties marked with these two asterix** are presents only in HDP3.1.0 environment.
The value of Hive Server2 URL will be the value of HiveServer2 Interactive JDBC url (given the in the screenshot). In the HDP 3.1.0 deployment, this is an additional property:
HiveServer2 Interactive JDBC URL: The value is as mentioned below:
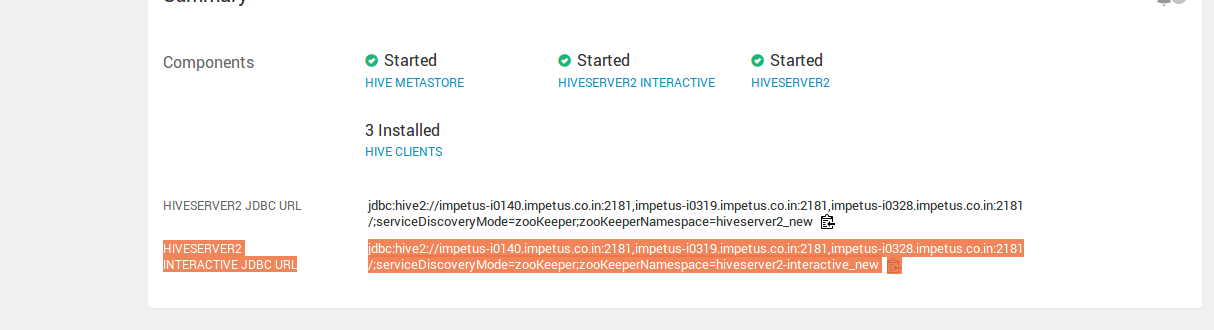
For creating a JDBC connection, select JDBC from the Component Type drop-down list and provide connections details as explained below.
Field | Description |
|---|---|
Component Type | Shows all different types of available connections. Select JDBC Component type from the list. Then select database type as “IBM DB2”. |
Connection Name | Name of the connection. |
Database Type | Type of database in which data needs to be dumped. The databases available are: MySQL, POSTGRESQL, ORACLE, MSSQL, Custom, and IBM DB2. |
Database Name | The name of the database to be used. |
Host | The host of the machine where database is deployed. |
Port | The port of the database where database is deployed. |
UserName | The username of the database. |
Password | The password of the database. |
Enable SSL | Check the option to enable SSL. |
SQL SSL Properties | SQL SSL JDBC driver url additional properties. |
Keystore Select Option | Option to provide keystore file path either by selecting the Specify keystore File Path option or Upload keystore File. |
ADD CONFIGURATION | In case of Databricks cluster, set the below configuration on the JDBC connection config for the respective Database type. Connection config property with key as connectionProvider and value as GathrJdbcConnectionProvider |
Create | Click on the Create button to create the connection. |
Test Connection | After entering all the details, click on the Test Connection button. If credentials are correct, a successful connection message is generated. If you enter wrong credentials or server is down, you will get the a Connection unavailable message. |
Note: JDBC-driver jar must be in class path while running a pipeline with JDBC emitter or while testing JDBC connection.
For creating a Kafka connection, select Kafka from the Component Type drop-down list and provide connections details as explained below.
Field | Description |
|---|---|
Component Type | Shows all the available connections. Select Kafka Component type from the list. |
Connection Name | Name of the connection to be created. |
zK Hosts | Defines the list of comma separated IP port of Zookeeper for creating Kafka topic from gathr UI. |
Kafka Brokers | List of Kafka nodes against which connections need to be created. |
Enable Topic Administration | Enabling topic administration will allow creation, updation and deletion of a topic. |
Enable SSL | Select the check box if connection is to be created with SSL enabled Kafka. |
Enable Truststore | Specify Truststore file path or upload Truststore file (in JKS Format). If option selected is Specify Truststore Path, you will view two additional fields: Truststore Path and Truststore Password. If option selected is Upload Truststore Path, you will view two additional fields: Upload Truststore File and Truststore Password. |
Upload Truststore File | Upload Truststore file by clicking on UPLOAD FILE button. |
Truststore Path | Location of the Truststore file. |
Truststore Password | Password of the Truststore file. |
Enable Authentication | Select the checkbox if client authentication is enabled. if selected, you will view four additional fields: Keystore Select Option, Upload keystore File, Keystore Password and Password. |
Keystore Select Option | Either specify keystore file path or upload keystore file (in JKS Format) |
Upload Keystore File | Enables to upload keystore file by clicking on UPLOAD FILE button. |
Keystore File Path | Location of the keystore file. |
Keystore Password | Keystore password for the Keystore file. |
Password | Password of the private key in the keystore file. |
Create | Click on the Create button to create the connection. |
Test Connection | After entering all the details, click on the Test Connection button. If credentials are correct, a successful connection message is generated. If you enter wrong credentials or server is down, you will get the a Connection unavailable message. |
For creating a Kinesis connection, select Kinesis from the Component Type drop-down list and provide other details required for creating the connection.
Field | Description |
|---|---|
Component Type | Shows all the available connections. Select Kinesis component type from the list. |
Connection Name | Name of the connection to be created. |
Connect Using | User has the option to authenticate the Kinesis connection with either AWS Keys or Instance Profile. |
Access Key Id | AWS account access key ID. |
Secret Key | AWS account secret key. |
Instance Profile | AWS Instance will be used to authenticate the connection, if user selects this option to create connection. |
Create | Click on the Create button to create the connection. |
Test Connection | After entering all the details, click on the Test Connection button. If credentials are correct, a successful connection message is generated. If you enter wrong credentials or server is down, you will get the a Connection unavailable message. |
Users can also choose to authenticate Kinesis connections using Instance Profile option.
For creating a KUDU connection, select KUDU from the Component Type drop-down list and provide other details required for creating the connection.
Field | Description |
|---|---|
Component Type | Shows all the available connections. Select KUDU component type from the list. |
Access Key Id | Name of the connection to be created. |
HOSTS | IP address and port of the machine where KUDU is running. |
Test Connection | After entering all the details, click on the Test Connection button. If credentials are correct, a successful connection message is generated. If you enter wrong credentials or server is down, you will get the a Connection unavailable message. |
For creating Mongo DB connection, select Mongo DB from the Component Type drop-down list and provide details required for creation the connection.
Field | Description |
|---|---|
Component Type | Shows different types of available connections. Select Mongo DB from the drop down. |
Connection Name | Name of the connection to be created. |
URI Format | Select URI Format from the drop down for defining connection between StreamAnalytix and Mongo DB instance. Use DNS seed to connect with any Mongo DB instance seed list member or else select the Standard option. |
Connection URL | Provide the driver URL to be used. |
Authentication Options | Option to choose the authentication method. Select either None or Basic AUTH option from the drop-down. If you select Basic AUTH, then provide the below fields: |
User Name | Provide the database user name with available access. |
Password | Provide the database password. |
Add Configuration | Option to add further configuration is available. |
For creating an MQTT connection, select MQTT from the Component Type drop-down list and provide other details required for creating the connection.
Field | Description |
|---|---|
Component Type | Shows all different types of available connections. |
Connection Name | Name of the connection to be created. |
Host | IP address of the machine where Socket is running. |
Port | Port of the machine where Socket is running. |
Test Connection | After entering all the details, click on the Test Connection button. If credentials are correct, a successful connection message is generated. If you enter wrong credentials or server is down, you will get the a Connection unavailable message. |
For creating an OpenJMS connection, select OpenJMS from the Component Type drop-down list and provide other details required for creating the connection.
Field | Description |
|---|---|
Component Type | Shows all the available connections. |
Connection Name | Name of the connection to be created. |
Connection Factory | A connection factory is an object that a JMS client uses to create a connection with OpenJMS. |
Host | IP address of the machine where Socket is running. |
Port | Port of the machine where Socket is running. |
Test Connection | After entering all the details, click on the Test Connection button. If credentials are correct, a successfull connection message is generated. If you enter wrong credentials or server is down, you will get the a Connection unavailable message. |
For creating a RedShift connection, select RedShift from the Component Type drop-down list and provide other details required for creating the connection.
Field | Description |
|---|---|
Component Type | Shows all different types of available connections.Select RedShift Component type from the list. |
Connection Name | Name of the connection to be created. |
Driver Type | Define Driver version for Redshift. |
Database Name | Name of the Database to be used. |
Host | Hostname of the machine where Redshift cluster is running. |
Port | Port number on which redshift cluster is listening. |
UserName | Redshift Username. |
Password | Redshift Password. |
Test Connection | After entering all the details, click on the Test Connection button. If credentials are correct, a successful connection message is generated. If you enter wrong credentials or server is down, you will get the a Connection unavailable message. |
For creating a RabbitMQ connection, Select RabbitMQ from the Component Type drop-down list and provide connections details as explained below.
Field | Description |
|---|---|
Component Type | Shows all the available connections.Select RMQ Component type from the list. |
Connection Name | Name of the connection to be created. For example, RabbitMQ, |
Host | IP address and port of the machine where RabbitMQ is running. |
UserName | Username of RabbitMQ to create connection. |
Password | Password of RabbitMQ to create connection. |
Create | Click on the create button to create the connection. |
Test Connection | After entering all the details, click on the Test Connection button, if credentials provided are correct, services are up, and running, you will get the message Connection is available. If you enter wrong credentials or server is down and you click on Test Connection, you will get the message Connection unavailable. |
For creating a DBFS connection, select DBFS from the Component Type drop-down list and provide other details required for creating the connection.
Field | Description |
|---|---|
Component Type | Shows all the available connections. Select S3 Component type from the list. |
Connection Name | Name of the connection to be created. |
Directory Path | Enter DBFS Parent Path for checkpointing. |
Test Connection | After entering all the details, click on the Test Connection button. If credentials are correct, a successful connection message is generated. If you enter wrong credentials or server is down, you will get the a Connection unavailable message. |
For creating a RDS connection, select RDS from the Component Type drop-down list and provide other details required for creating the connection.
Field | Description |
|---|---|
Component Type | Shows all the available connections. Select S3 Component type from the list. |
Connection Name | Name of the connection to be created. For example, RabbitMQ. |
Database Type | Database Type (mysql, postgresql, oracle, mssql, Amazon Aurora-Mysql, Amazon Aurora-PSSQL) |
Enable SSL | Select the checkbox if SSL is enabled on RDS. |
Keystore Select Option | Specify keystore path: Specify the Elasticsearch keystore file (.p12) path. Upload keystore path: Upload the Elasticsearch keystore file (.p12) path. |
Upload Keystore File | Enables to upload keystore file by clicking on UPLOAD FILE button. |
Database Name | Name of the database. |
Host | Hostname of RDS. |
Port | Portname of RDS. |
Username | Username of the account. |
Password | Password of the account. |
Create | Click on the Create button to create the connection. |
Test Connection | After entering all the details, click on the Test Connection button. If credentials are correct, a successful connection message is generated. If you enter wrong credentials or server is down, you will get the a Connection unavailable message. |
For creating a S3 connection, select S3 from the Component Type drop-down list and provide other details required for creating the connection.
Field | Description |
|---|---|
Component Type | Shows all the available connections. Select S3 Component type from the list. |
Connection Name | Name of the connection to be created. For example, RabbitMQ. |
Connect Using | User has the option to authenticate the S3 connection with either AWS Keys or Instance Profile. |
Access Key Id | AWS account access key ID. |
Secret Key | AWS account secret key. |
Instance Profile | AWS Instance will be used to authenticate the connection, if user selects this option to create connection. |
Create Connection | Click on the Create button to create the connection. |
Test Connection | After entering all the details, click on the Test Connection button. If credentials are correct, a successful connection message is generated. If you enter wrong credentials or server is down, you will get the a Connection unavailable message. |
For creating an SQS connection, select SQS from the Component Type drop-down list and provide other details required for creating the connection.
Field | Description |
|---|---|
Component Type | Shows all the available connections. Select Component type from the list. |
Connection Name | Name of the connection to be created. |
AWS Key id | S3 account access key. |
Secret Access Key | S3 account secret key. |
Region | AWS IOT Region. |
Test Connection | After entering all the details, click on the Test Connection button. If credentials are correct, a successful connection message is generated. If you enter wrong credentials or server is down, you will get the a Connection unavailable message. |
For creating a Salesforce connection, select Salesforce from the Component Type drop-down list and provide other details required for creating the connection.
Field | Description |
|---|---|
Component Type | Shows all the available connections. Select Salesforce Component type from the list. |
Connection Name | Name of the connection to be created. |
Username | Username of Salesforce to create connection. |
Password | Password of Salesforce to create connection. |
securityToken | Security token is a case-sensitive alphanumeric key that is used in combination with a password to access Salesforce via API. |
Test Connection | After entering all the details, click on the Test Connection button. If credentials are correct, a successful connection message is generated. If you enter wrong credentials or server is down, you will get the a Connection unavailable message. |
For creating a Snowflake connection, select Snowflake from the Component Type drop-down list and provide connections details as explained below. Field Description Component Type Shows all the available connections. Select Snowflake component type from the list. Connection Name Name of the connection to be created. Account Name Option to enter the Snowflake account name. After entering the account name, the connection URL will get formed on its own. Connection URL Provide the driver URL to be used. Database Name Database name should be provided to access the data. Username Username of the Snowflake account should be provided. Password Password of the Snowflake account should be provided. Keystore Select Option Option to upload the keystore file is selected by default. Upload Keystore File Option to upload the keystore file. Keystore Password Option to provide the password to access the uploaded keystore file.
After entering all the details, click on the TEST button.
If the connection service identification and authentication details are provided correctly, a success message stating “connection available” is generated. Click on the CREATE button to save the changes.
If the details are incorrect or the server is down, you will get a message “Connection unavailable”.
For creating a Socket connection, select Socket from the Component Type drop-down list and provide connections details as explained below.
Field | Description |
|---|---|
Component Type | Shows all the available connections. Select Socket component type from the list. |
Connection Name | Name of the connection to be created. |
Host | IP address of the machine where Socket is running. |
Port | Port of the machine where Socket is running. |
Create | Click on the Create button to create the connection. |
Test Connection | After entering all the details, click on the Test Connection button. If credentials are correct, a successful connection message is generated. If you enter wrong credentials or server is down, you will get the a Connection unavailable message. |
For creating a Solr connection, Select Solr from the Component Type drop-down list and provide connections details as explained below.
Field | Description |
|---|---|
Component Type | Shows all different types of available connections. Select SOLR component type from the list. |
Connection Name | Name of the connection to be created. |
zkHost | The Zookeeper host for Solr sever. |
Create | Click on the Create button to create the connection. |
Test Connection | After entering all the details, click on the Test Connection button. If credentials are correct, a successful connection message is generated. If you enter wrong credentials or server is down, you will get the a Connection unavailable message. |
For creating a Tibco connection, select Tibco from the Component Type drop-down list and provide connections details as explained below.
Field | Description |
|---|---|
Component Type | Shows all the available connections. Select Tibco Component type from the list. |
Connection Name | Name of the connection to be created. |
Connection URL | For Tibco connection the driver URL should be provided. |
User Name | Tibco account username should be provided. |
Password | Tibco account password should be provided. |
JNDI Naming | Unchecked by default, the user can check-mark this option to provide the JNDI naming context. Upon selecting this option, provide the below details: |
Initial Context Factory | Provide the initial context factory to be used for JNDI lookup. |
Factory Name | Provide the Factory name which is the name of the connection factory. |
Enable SSL | Unchecked by default, the user has an option to enable the SSL. Upon check-marking the Enable SSL option, provide the below details: |
Identity Certificate | Option to choose the Identity Certificate. Choose one of the below options: - Specify Identity Certificate Path - Upload Identity Certificate Note: Provide the Identity Certificate Path or Upload the Identity Certificate based on the selected Identity Certificate type. |
Private Key File | Option to choose the Private Key File type. Choose one of the below options: - Specify the Private Key File path - Upload Private Key File Note: Provide the Private Key File either by specifying the Private Key File path or by uploading the Private Key File based on the selected Private Key File options available in the drop down list. |
Password for Private Key | Provide the password for Private Key. |
Verify Host | Option to enable verification of Tibco server certificate. If enabled the client will verify the server certificate. If disabled, the client will establish secure communication with the server but will not verify the server's identity. Upon checking this option, provide below details: |
Server Root Certificate | Select the Server Root Certificate: - Specify Server Root Certificate Path - Upload Server Root Certificate |
Verify Hostname | Option for client to enable verification of hostname in the CN field of the server's certificate. If enabled the client will verify the name specified in the "Expected Hostname" against the server's certificate. Else, it will take the server's hostname as default. If disabled, the client establishes secure communication with the server but does not verify the server's name. |
Expected Hostname | Option to specify expected hostname which will be used while hostname verification. |
Auth Only | This option specifies whether SSL should be used to encrypt all server-client communications or only for client authentication. Upon check marking this option, the client request SSL will be used only for authentication. |
Create | Click on the Create button to create the connection. |
Test Connection | After entering all the details, click on the Test Connection button. If credentials are correct, a successful connection message is generated. If you enter wrong credentials or server is down, you will get the a Connection unavailable message. |
For creating a Twitter connection, select Twitter from the Component Type drop-down list and provide connections details as explained below.
Field | Description |
|---|---|
Component Type | Shows all the available connections. Select Twitter Component type from the list. |
Connection Name | Name of the connection to be created. |
Consumer Key | Twitter User consumer key. |
Consumer Secret Key | Twitter User consumer secret key. Consumer keys are the identity of an application owner. |
Access Token | Application owners need to generate Authorization-access tokens that are used to call the Twitter API without sharing their passwords. This is a twitter user access token. |
Access Token Secret | This is a twitter user access token secret |
For creating a Vertica connection, select Vertica from the Component Type drop-down list and provide connections details as explained below.
Field | Description |
|---|---|
Component Type | Shows all different types of available connections. Select VERTICA Component type from the list. |
Connection Name | Name of the connection. For example, HDFS. |
Database Name | Database name to access data. |
Host | Database host name or IP address. |
Port | Database port name. |
Username | The username of database user. |
Password | The password of database user. |
Test Connection | After entering all the details, click on the Test Connection button, if credentials provided are correct, services are up, and running, you will get the message Connection is available. If you enter wrong credentials or server is down and you click on Test Connection, you will get the message Connection unavailable. |
On updating a default connection, its respective configuration also gets updat
In reverse of auto update connection, auto update configuration is also possible.
If you update any component’s configuration property, from Configuration Page, then the component’s default connection will also be auto updated.
For example: Updating RabbitMQ host URL configuration will auto update RabbitMQ Default connection.
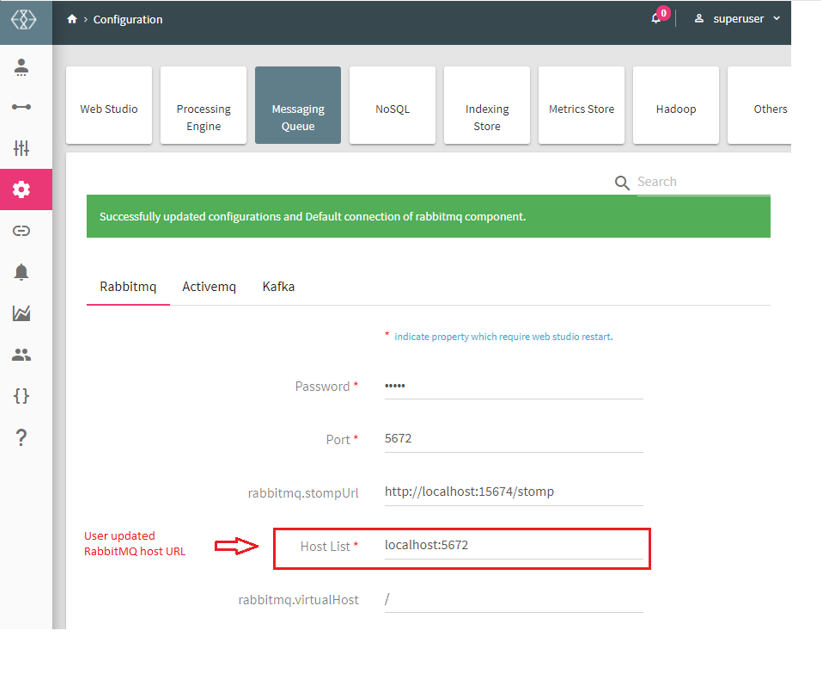
This widget shows the alerts generated by a pipeline when it goes in error mode or killed from YARN.
System alerts shows two types of alerts.
Pipeline stopped Alerts: Alerts thrown when a Pipeline is killed from YARN.
Error Mode Alerts: Alerts thrown when the Pipeline goes in error mode.
You can apply an alerts on a streaming pipeline as well. You will see the description of the alert and its time stamp in this widget. The alert can have a customized description.
To navigate to the Workspace Connections page, the user can click on the Connections feature which is available in the workspace menu.
The users with privilege to create connections can create new connections at the workspace level in the same manner as it is explained in the manage superuser connections topic. To know more, see Manage Superuser Connections.
Note:
- Unique names must be used to create new connections inside a Workspace for similar component types. User will get notified in the UI if the specified connection name already exists.
- The visibility of default connections and the connections created by Superuser at any Workspace level is controlled by the Superuser.
- The connections created in a Workspace can be differentiated by the Workspace and Owner name in the list. The superuser created connections will appear in the list with the Workspace and Owner name as Superuser.
- Connections listed in a workspace can be used to configure features like Datasets, Pipelines, Applications, Data Validations, Import Export Entities & Register Entities inside a Project. While using the connections for above listed features, the superuser connections can be differentiated from other workspace created connections by a suffix, “global” which is given after the connection name.
- Connections will not be visible and cannot be consumed outside of the workspace in which they are created.
Audit Trail captures and presents all important activities and events in the platform for auditing.
Interaction events include pipeline creation, pipeline inspection, license uploads, test-cases execution, configuration updates, connection updates, notebook creation, model validation and all other interactions possible within Gathr.
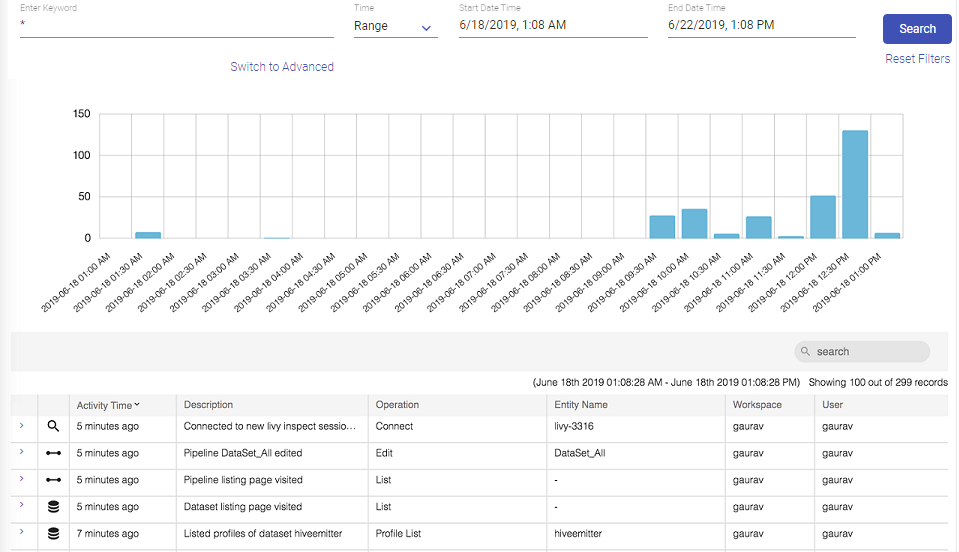
Audit Trail provides following features to search, view and filter user interaction events in graphical and tabular formats.
There are two modes of searching an event, Basic and Advanced.
Events can be searched by providing required parameters inside filter menu on top of Audit Trail page. The search results returned are from all the entities, which is across all workspaces, all types of operations and so on.
In a basic search, following are the options by which you can perform a search.
l Time Range search
l Time Duration search.
l Full Text Search
l Keyword Search
Note: Time Range and Time Duration search is also performed in Advanced Search.
Different filter operations are available which are listed below.
Provide time intervals by setting Start Date Time and End Date Time filters to get those event interactions which were performed in specified time range.
Default value is 12 hours ago from the current system time.
Click on Set button for it to reflect the selected date time.
Select Duration option for defining time intervals. Provide duration as integer value with desired time unit. Default duration value is 12 and unit is hours.
Possible units are minutes, hours, days and weeks.
To search events based on keyword or pattern, use Full text search filter option.
Use wildcard (*) to create pattern or provide exact value. System will search events by matching all field values of record.

To perform search on any of the field value of the event record, use colon based pattern.
For example- interactionBy:John*, where, interactionBy is one of the field name of event record which specifies the user name who performed that event and John* is value of field interactionBy.

Possible field names which can be used to perform Keyword search are as follows:
Field Name | Description |
|---|---|
timestamp | Epoch time, in milliseconds, when the event was performed, e.g., 1560369000 |
entityType | Entity type on which action was performed, e.g., pipeline, user, work-space, inspect_session, etc. |
entityName | Name of the entity on which event was performed, e.g., pipeline name, workflow name, user name etc. |
operation-Name | The type of action performed on entity, e.g., create, up-date, delete, list, access, share, revoke, etc. |
description | Descriptive message about the event interaction. |
interactionBy | User who caused the interaction event. |
tenantId | The tenant id in which event occurred. |
tenantName | The tenant name associated with tenant id. |
In contrast to basic Full Text Search, you can perform advance search where you need to select list of entities and operations on which you want to search event interactions.

Possible entities and operation types will be listed on Entity and Operation drop down filters respectively.
Filter out event interactions based on workspace names. The event occurred in specified work-space will be shown. This filter operation is visible in superuser workspace only
.
Time-series graph represents aggregated count of events occurred within given time range. The counts will be shown on time series graph with fixed time intervals. Each interval is represented by graph bar.
Time intervals are calculated based on given time range values in search query. Bigger the given time range, bigger will be the time interval.
Example: 12 hours as input time range will give event counts of every 30 minutes interval 1 hour as input time range will give event counts of every 1 minute interval.
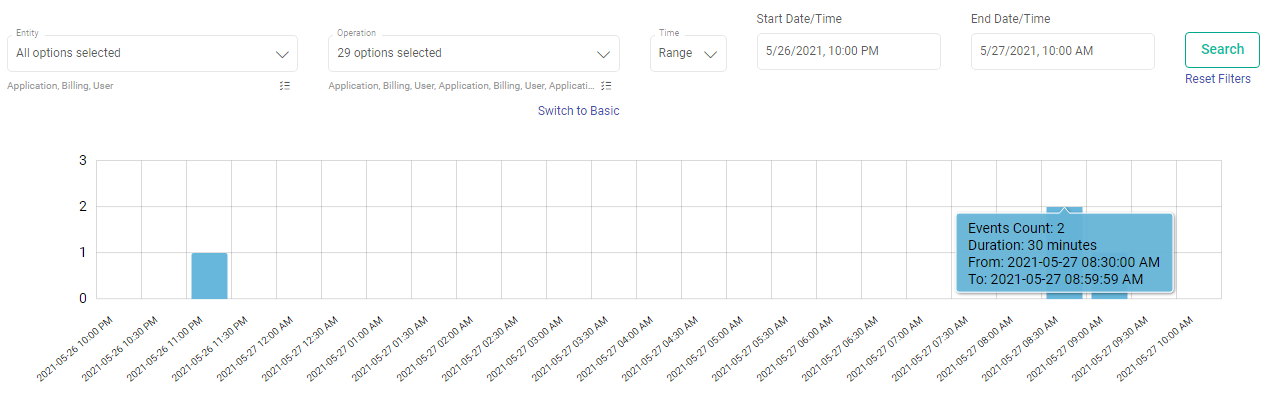
It allows you to zoom in on a specific area of the graph, which will drill down the graph further and will show the zoomed selected area. New search request will be placed with zoomed time range boundaries.
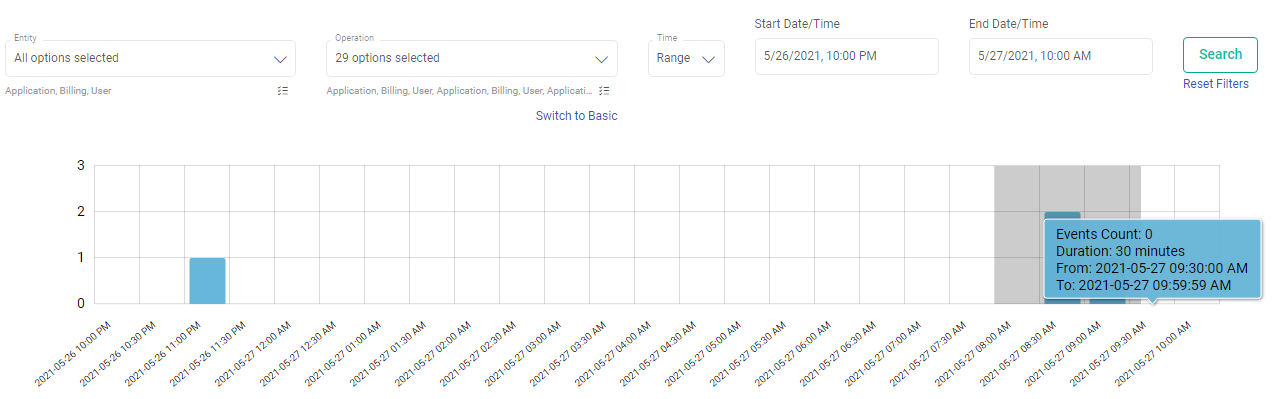
After panning and zooming the results, the graph looks as shown below:
Perform following operations on the search results:
Infinite Scroll
Whenever you scroll down in Result table, next bunch of 100 records will be fetched and appended in result table. You can change the default 100 fetch-size from Audit Configuration page.
Scroll has defined an expiry time after which scroll window will be expired. Default scroll expiry time is 5 minutes.
On every subsequent scroll and new search request, scroll expiry time will get reset.

Sorting of Events
You can sort results based on field value of events. A new search request will be placed on each sort action and top 100 (default fetch size) sorted results will be shown out of total matched hits.
This functionality shows the event activities performed on a pipeline.
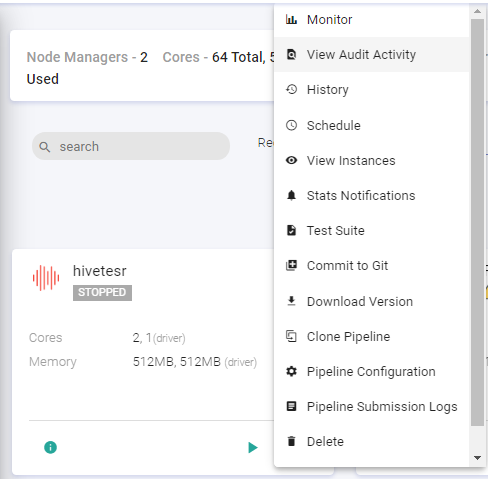
Event counts are represented by circles on time series graph.

Event interaction will be auto deleted after configured retention time.
The common terms displayed in the search result table are explained in the table below.
Field | Description |
|---|---|
Activity Time | Event time when the event was performed. To see that exact time stamp of event, expand the result row. |
Description | Brief description about the event. |
Operation | Operation name which user has performed. It might be Create, Delete, Update, etc. |
Entity Name | Name of entity on which event has been performed. Example pipeline created named as ‘SanityRun’ will be mapped as entity name. |
Workspace | Name of the workspace under which event got performed (A single user can work on multiple workspaces) |
User | User name who performed the operation |
User can configure events audit mechanism as per the requirement.
Refer the Administration Audit tab for configuration details.
Gathr users are the authorized consumers of the application having one or more roles assigned with certain privileges, to execute a group of tasks.
The Manage Users option is provided in the main menu and the workspace menu.
Only the superuser has control over user and role management features that are available in the main menu, whereas both the admin user and the superuser can manage users and roles in the workspace menu.
The other workspace users can only view the role(s) and associated privileges assigned to them in the Manage Users option of the workspace menu.
There are several tabs in the Manage Users feature which are explained in the subsequent topics.
The tabs that are available for Manage Users option in the main menu are described below.
The LDAP tab will only appear when user authentication and authorization is controlled by LDAP or Active Directory in the Gathr configuration options.
Listing Page
The superuser can assign global or custom created roles to the existing LDAP groups as per the requirement.
The information and actions displayed for the listed LDAP groups are explained below:
Field | Description |
|---|---|
Global LDAP Groups The global LDAP groups that are created by the superuser from main menu, cannot be deleted in the workspace listing of LDAP tab. | |
Add LDAP Roles | The Add LDAP Roles option is given at the top right side of the page. It can be used to add new entries for the LDAP group listings |
Gathr Role | A drop-down option having list of all the global and custom roles. The desired role for the LDAP group must be selected. Example: Workspace Admin, Data Analyst I, Data Analyst II, Read Only, and so on. |
LDAP Group | Search or enter the LDAP group(s) name that must be assigned with the selected Gathr Role. |
Action | Option to remove the role assignment done for any specific LDAP group. |
Once the role assignment for required LDAP groups is done, click on the VALIDATE option to cross-check the LDAP group name and SAVE to register the changes.
This tab contains the list of the out of box global roles and the custom roles that are created using New Role option.
The out of box Global roles are:
l System Admin
l Workspace Admin
l Data Analyst - I
l Data Analyst - II
l Read Only
Listing Page
The information and actions displayed on the Roles listing page are explained below:
Field | Description |
|---|---|
Roles | Name of the roles that are existing in Gathr. |
Type | Type of role. Global if created from main menu and Custom if created from the workspace menu. |
Privileges | The number of privileges that are assigned to the particular role. The assigned privileges can be viewed by clicking on the value displayed. |
Users | The number of users that are assigned with the particular role. The list of users assigned with the particular role can be viewed by clicking on the value displayed. |
Actions | Options to edit or delete the listed role(s). Note: The out of box roles cannot be deleted. |
Add Roles
The superuser can create new roles using the Add New Role option given on the top right side of the Roles tab.
The configuration details for creation of a new role are described in the table given below:
Field | Description |
|---|---|
New Role | |
Role Name | Unique name of the new role to be created. |
Load Privilege by Users | Privilege(s) of the existing user(s) selected will instantly load in the Set Privilege section. For any privilege conflicts, load preference is given to Deny > Allow > Revoke. |
Load Privilege by Roles | Privilege(s) of the existing role(s) selected will instantly load in the Set Privilege section. For any privilege conflicts, load preference is given to Deny > Allow > Revoke. |
Description | Optional description can be provided. |
Set Privilege Select and set the role privilege(s), or instantly load privilege(s) of the existing role(s) and user(s) with configuration options explained above. Possible options to set privileges are: Revoke: Set by default. User(s) assigned with this role will not be able to perform the revoked action(s). Allow: User(s) assigned with this role will be able to perform the allowed action(s) unrestricted. Deny: User(s) assigned with this role will not be able to perform the denied action(s). Revoke and Allow can be changed to any other privilege as required (by providing direct privilege) when the existing roles are later mapped to user(s). But, Deny privilege(s) strictly remain unchanged. | |
Workspace | If the role privileges are customized in the Set Privilege section, then the privilege settings for features: Summary, Audit, Project, Cluster, Register Image and Connections can be done in the Workspace section. |
Project | If the role privileges are customized in the Set Privilege section, then the privilege settings for features: Template, Models, Register Entities, Instances, Data Validation, Workflow, Version Control, Import Export Entities, Sandbox, Pipeline, Compute Environment, Processor Group, Dataset and Applications can be done in the Project section. |
Once the required privilege assignment is done for the new role, click on the CREATE option to register the role in Gathr.
This tab contains the list of the users that are registered with Gathr.
The options available on this tab will be different for LDAP configured user management. The description clearly states the options that will be only visible when Gathr Metastore configuration is used for user management.
Listing Page
The information and actions displayed on the Users listing page are explained below:
Field | Description |
|---|---|
Name | Name of the existing user. |
Workspace Name | Name of the workspace for which the user is assigned. |
Email Id | The registered email id of the user. Note: Only applicable for Gathr Metastore configuration. |
Assigned Roles | Type of role that is assigned to the user. |
Actions | The actions that can be performed are: l Enable/disable user l Edit user details l Edit assigned privileges l Delete user Note: Only applicable for Gathr Metastore configuration. |
Add Users
Note: Add users option is only applicable for Gathr Metastore configuration user management.
The superuser can create new users using the New User option given on the top right side of the Users tab.
The configuration details for creation of a new user are described in the table given below:
Field | Description |
|---|---|
New User The new user configuration section is divided in two parts, namely, Add Roles and Add Users. The configuration options for both parts are explained below. | |
Add Roles This is an optional part. If the new user has to be assigned with any of the existing roles, it is possible to do so with Add Roles option. | |
Select Roles | Privilege(s) of the role(s) selected will instantly load in the Set Privilege section. For any privilege conflicts, load preference is given to Deny > Allow > Revoke. Deny privilege(s) strictly remain unchanged, whereas any additional privilege changes will appear as ‘Direct Privileges’. |
Set Privilege Revoke: Set by default. User(s) assigned with this role will not be able to perform the revoked action(s). Allow: User(s) assigned with this role will be able to perform the allowed action(s) unrestricted. Deny: User(s) assigned with this role will not be able to perform the denied action(s). | |
Workspace | The role privileges for features: Summary, Audit, Project, Register Image and Connections will be visible in the Workspace section. |
Project | The role privileges for features: Models, Register Entities, Data Validation, Workflow, Version Control, Import Export Entities, Sandbox, Pipeline, Processor Group, Compute Environment, Dataset and Applications will be visible in the Project section. |
Add User Users selected will get assigned with the privilege(s), if configured in the Add Roles page. | |
User Name | Unique name for the new user must be provided. |
Email Id | Email Id of the new user must be provided. |
Password | Password for the new user must be provided. |
Confirm Password | Re-type the password. |
Language | Choose the language, from English (US) and German (DE). |
Configure Artifactory | The user can configure artifactory by checkmarking the checkbox. Provide Artifactory URL, Username and Password. |
Once the required configuration is done for the new user, click on the CREATE option to register the user in Gathr.
The tabs that are available for Manage Users option in the workspace menu are described below.
The users can verify their assigned privileges on the My Roles tab.
The information displayed on the My Roles tab are explained below:
Field | Description |
|---|---|
Roles | Privileges assigned to the user for the role(s) selected from this list can be viewed in the Privilege section. |
Privilege Revoked: You will not be able to perform the revoked action(s). Request your System Administrator to allow any revoked privilege(s) that you may need. Allowed: You will be able to perform the allowed action(s) unrestricted. Denied: You will not be able to perform the denied action(s). | |
Workspace | The role privileges for features: Summary, Audit, Project, Register Image and Connections will be visible in the Workspace section. |
Project | The role privileges for features: Models, Register Entities, Data Validation, Workflow, Version Control, Import Export Entities, Sandbox, Pipeline, Processor Group, Compute Environment, Dataset and Applications will be visible in the Project section. |
The LDAP tab on the workspace listing is divided in two parts, Global LDAP Groups and Custom LDAP Groups.
The Global LDAP Groups will contain the list of LDAP groups and the roles assigned by the superuser. They cannot be deleted from the Actions column.
The Custom LDAP Groups will contain the list of LDAP groups and roles assigned at the Workspace level. They can be deleted from the Actions column.
The steps and configuration to add custom LDAP groups and roles is same as mentioned in the table for Global LDAP groups which is given in Manage Users (Main Menu) topic.
The Roles tab contains the list of Global roles (created by superuser through the main menu) and custom roles (added through the workspace menu).
The Global roles listed on this tab cannot be deleted from the Actions column.
The steps and configuration to add roles is same as mentioned in the Manage Users (Main Menu) topic.
The Users tab contains the list of users.
The options and functionality are same as described in the Users section of the Manage Users (Main Menu) topic.
A number of users that are registered in Gathr can be combined in a group to manage assignment of privileges for the entire group from Groups tab.
Listing Page
The information and actions displayed on the Groups listing page are explained below:
Field | Description |
|---|---|
Name | Name of the group created. |
Members | Total count of the users in the group. |
Roles | Type of roles assigned to the group. |
Actions | Options to edit or delete the group. |
Add Groups
The groups can be created using the New Group option given on the top right side of the Groups tab.
The configuration details for creation of a new group are described in the table given below:
Field | Description |
|---|---|
New Group The New Group section is divided in two parts, Users and Set Privileges. Each of them is explained in detail below. | |
Users Any number of users that exist in Gathr can be registered using the Add Users to Group option. Either the users can be added from the given list or a CSV file having the list of users can be uploaded and validated. | |
Set Privileges | |
Select Roles | Privilege(s) of the role(s) selected will instantly load in the Set Privilege section. For any privilege conflicts, load preference is given to Deny > Allow > Revoke. Deny privilege(s) strictly remain unchanged, whereas any additional privilege changes appear as ‘Direct Privileges’ on the listing page. |
Set Privileges as Role | For the privilege(s) that are selected and set, a new role can be created using this option. If user clicks on SET PRIVILEGES AS ROLES option, a new window will pop up with options to provide the role name and description and thereby register the role. |
Set Privilege Select and set the role privilege(s), or instantly load privilege(s) of the existing role(s) and user(s) with configuration options explained above. Possible options to set privileges are: Revoke: Set by default. User(s) assigned with this role will not be able to perform the revoked action(s). Allow: User(s) assigned with this role will be able to perform the allowed action(s) unrestricted. Deny: User(s) assigned with this role will not be able to perform the denied action(s). Revoke and Allow can be changed to any other privilege as required (by providing direct privilege) when the existing roles are later mapped to user(s). But, Deny privilege(s) strictly remain unchanged. | |
Workspace | If the role privileges are customized in the Set Privilege section, then the privilege settings for features: Summary, Audit, Project, Register Image and Connections can be done in the Workspace section. |
Project | If the role privileges are customized in the Set Privilege section, then the privilege settings for features: Models, Register Entities, Data Validation, Workflow, Version Control, Import Export Entities, Sandbox, Pipeline, Processor Group, Compute Environment, Dataset and Applications can be done in the Project section. |
To change outline of any existing connection, components or pipelines, a developer has to manually edit JSON files residing in /conf/common/template directory of Gathr bundle. Templates allow you to update these from UI. You can create many versions of them and switch to any desired version at any point. The changes in the outline of that component will be reflected immediately.
Components tab allows you to edit the JSON, view the type of component for Spark engine.
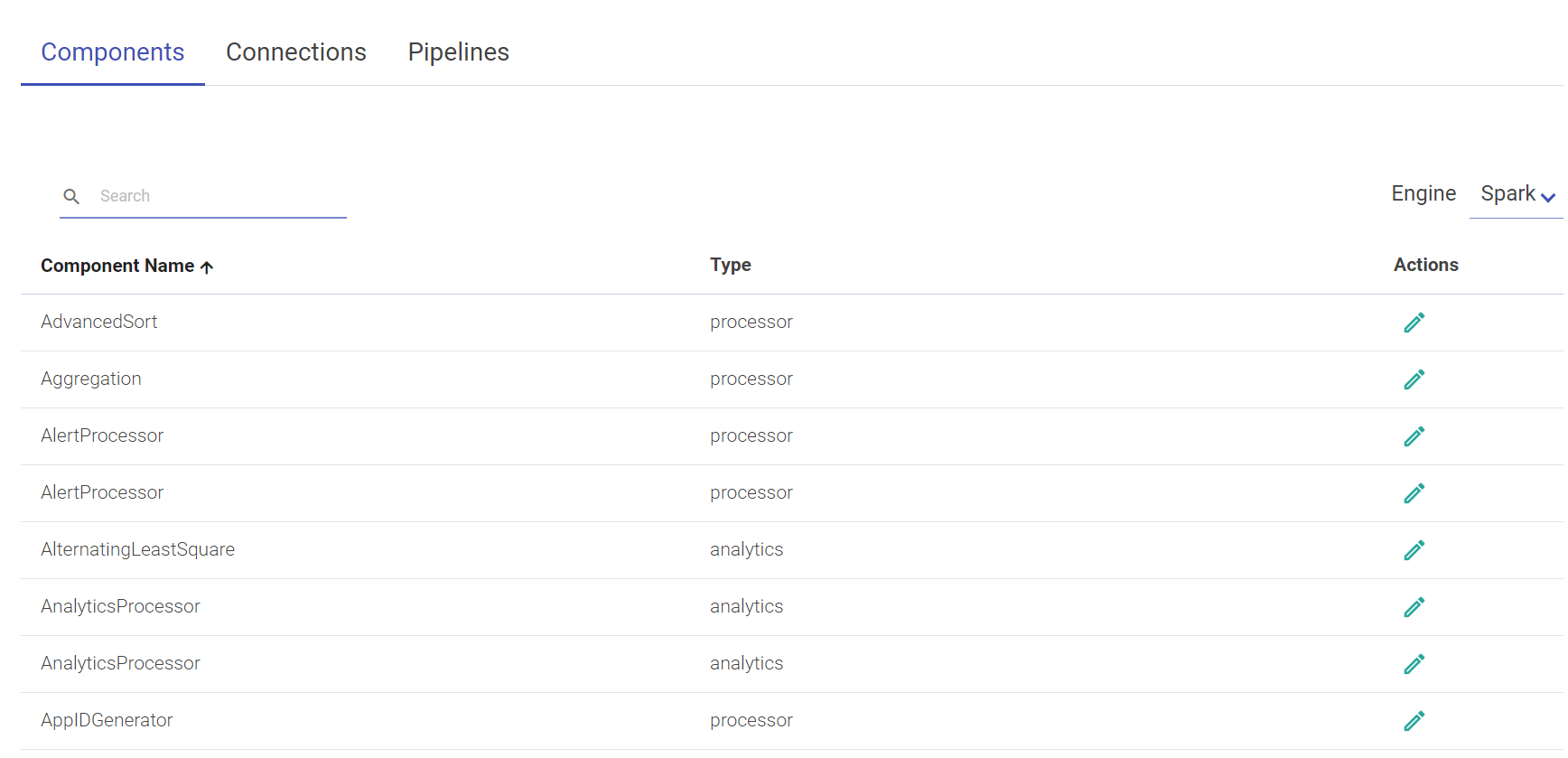
Field | Description |
|---|---|
Component Name | The name of the component. |
Type | Type of component. For e.g. Processor, Data Source, Emitter or Analytics. |
Action | Edit the Json or Version |
When you edit any component, Version, Date Modified and Comments added are viewable.
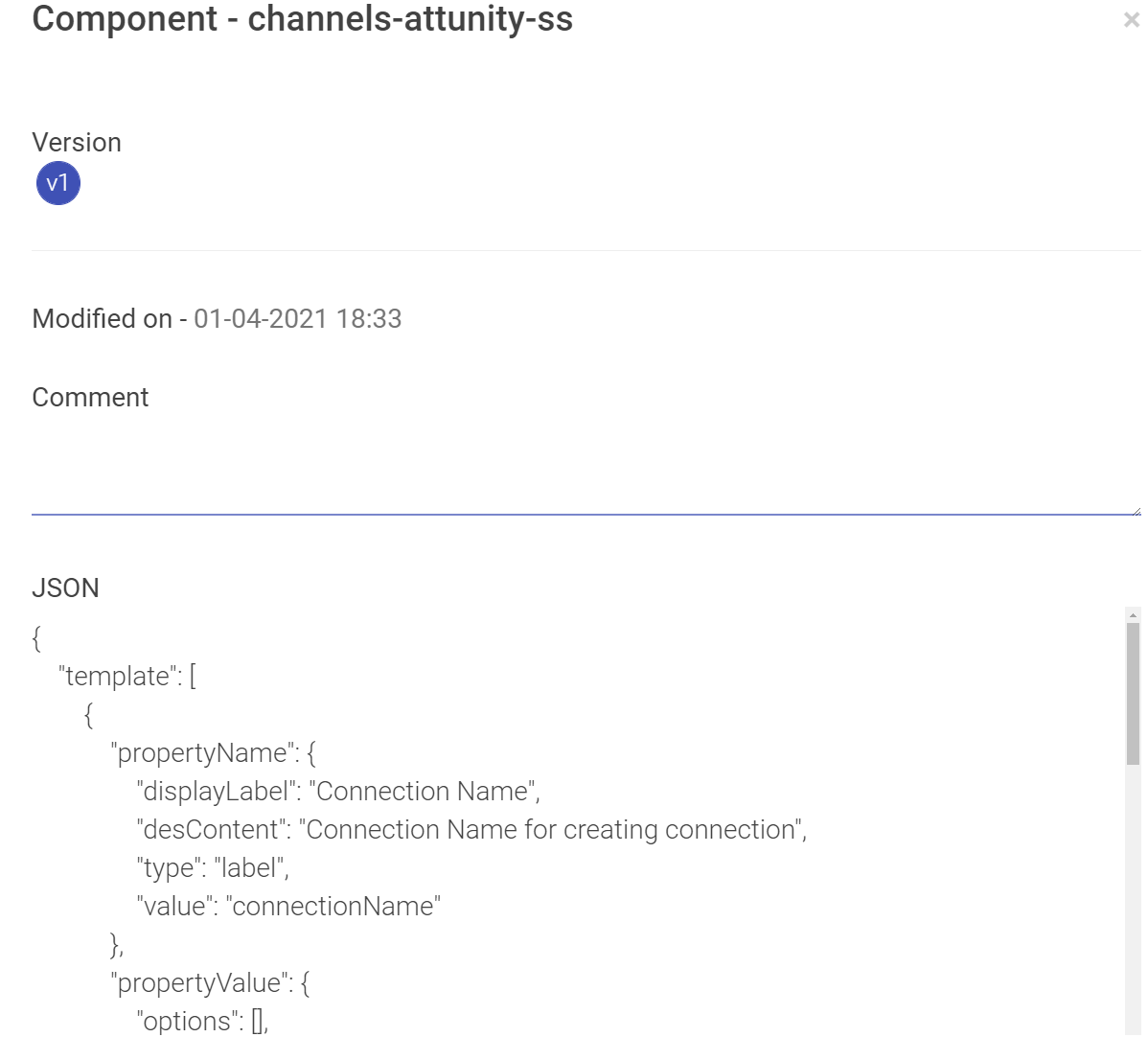
Connection tab allows you to edit the JSON and create as many versions as required
.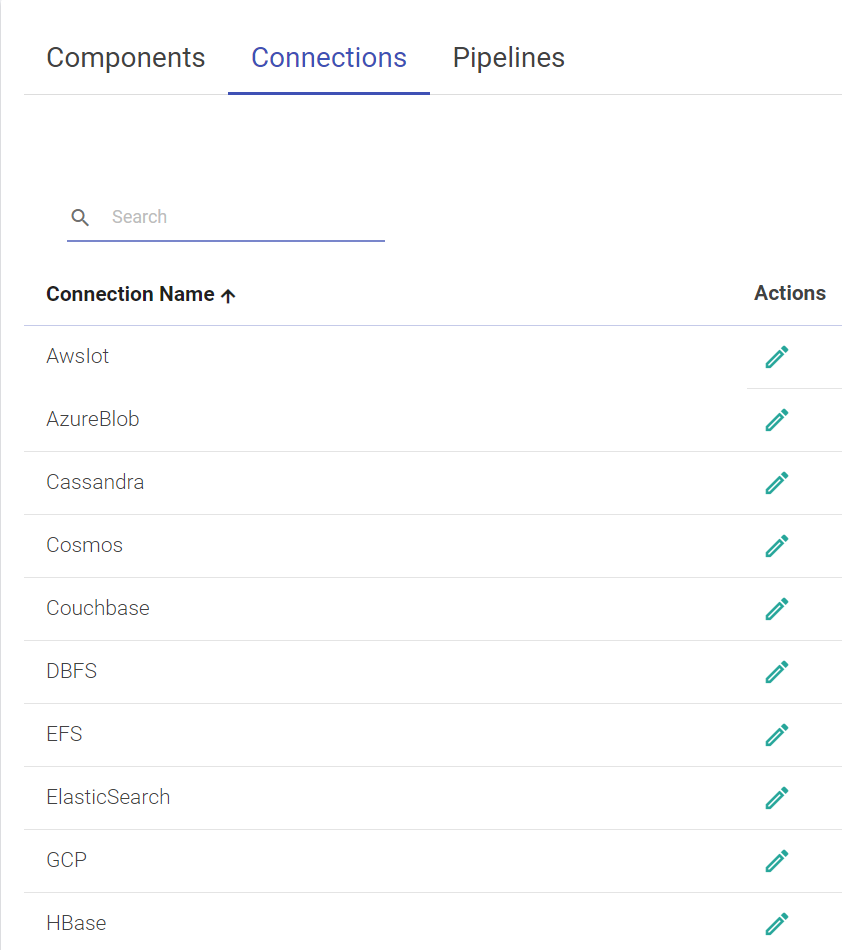
Field | Description |
|---|---|
Connection Name | The name of the component. |
Action | Edit the JSON or Version |
When you edit any Connection, Version, Date Modified and Comments added are viewable.
Gathr Credit Points Consumption calculates the credits which is based on the number of cores used in the running jobs for a period of one month. It is a costing model which charges customer based on their usage.
The number of cores used is captured every minute for every running job. Currently the number of cores used is calculated for two types of clusters: EMR and Databricks.
This option redirects the user to Gathr support portal.